







CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.IndoorSim-to-OutdoorReal: Learning to Navigate Outdoors without any Outdoor Experience

标题:IndoorSim-to-OutdoorReal:在没有任何户外经验的情况下学习在户外导航
作者:Joanne Truong, April Zitkovich, Sonia Chernova, Dhruv Batra, Tingnan Zhang, Jie Tan, Wenhao Yu
文章链接:https://arxiv.org/abs/2305.01098
项目代码:https://www.joannetruong.com/projects/i2o.html

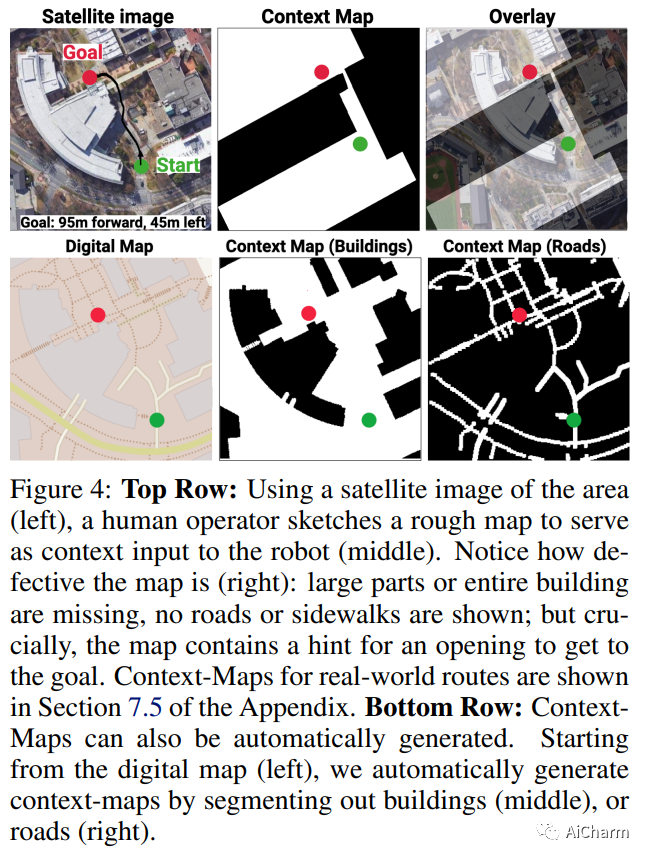
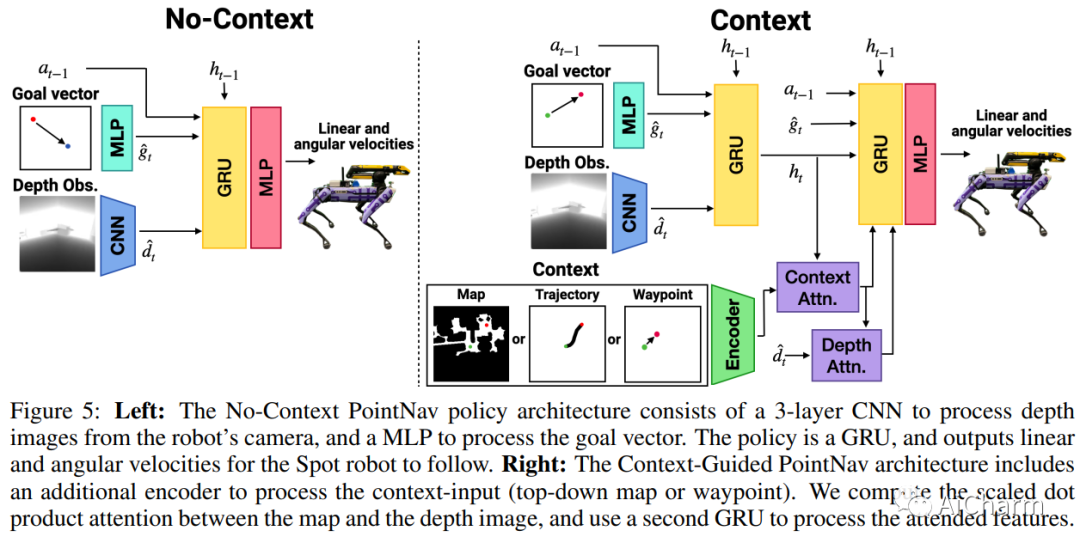

摘要:
我们展示了 IndoorSim-to-OutdoorReal (I2O),这是一种端到端的学习视觉导航方法,仅在模拟的短程室内环境中进行训练,并演示了零样本模拟到真实的远程转移到室外在 Spot 机器人上导航。我们的方法使用零真实世界经验(室内或室外),并且要求模拟器模拟没有主要是室外的现象(倾斜的地面、人行道等)。I2O 传输的关键是为机器人提供额外的环境上下文(即卫星地图、人类绘制的粗略地图等)以指导机器人在现实世界中的导航。提供的上下文地图不需要准确或完整——现实世界的障碍物(例如,树木、灌木、行人等)未绘制在地图上,开口与它们在真实世界中的位置不对齐-世界。至关重要的是,这些不准确的上下文映射为机器人提供了关于通往目标的路线的提示。我们发现,我们利用 Context-Maps 的方法能够在新环境中成功导航数百米,避开其路径上的新障碍,在没有任何碰撞或人工干预的情况下到达遥远的目标。相比之下,没有附加上下文的策略会完全失败。最后,我们通过在模拟中向地图添加不同程度的噪声来测试 Context-Map 策略的稳健性。我们发现上下文映射策略对提供的上下文映射中的噪声具有惊人的鲁棒性。在存在明显不准确的地图(被 50% 的噪声损坏或完全空白的地图)的情况下,策略会优雅地回归到没有上下文的策略行为。此 https 网址提供视频
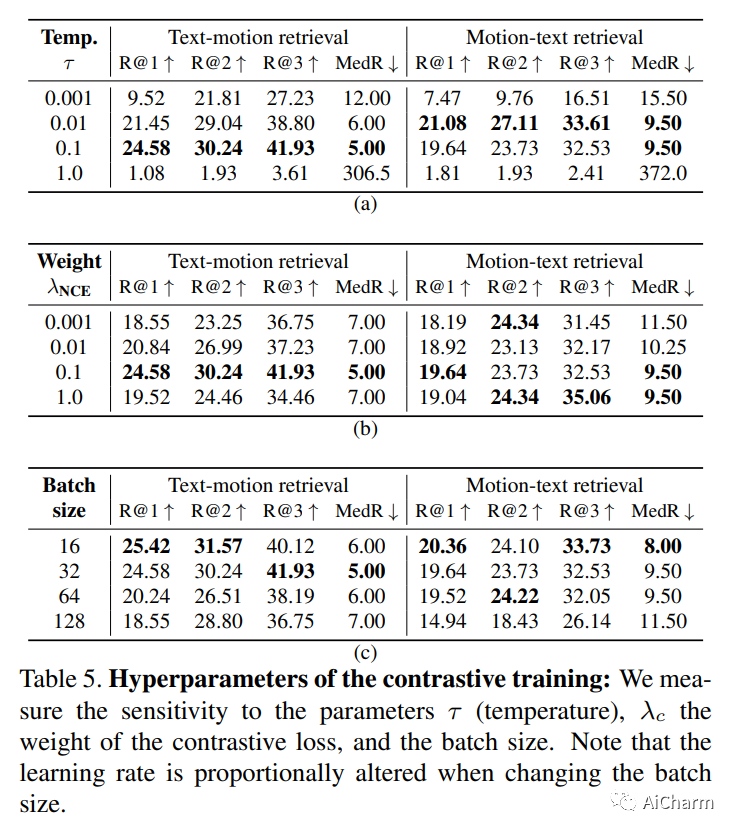
2.TMR: Text-to-Motion Retrieval Using Contrastive 3D Human Motion Synthesis

标题:TMR:使用对比 3D 人体动作合成的文本到动作检索
作者:Mathis Petrovich, Michael J. Black, Gül Varol
文章链接:https://arxiv.org/abs/2305.00976
项目代码:https://mathis.petrovich.fr/tmr/
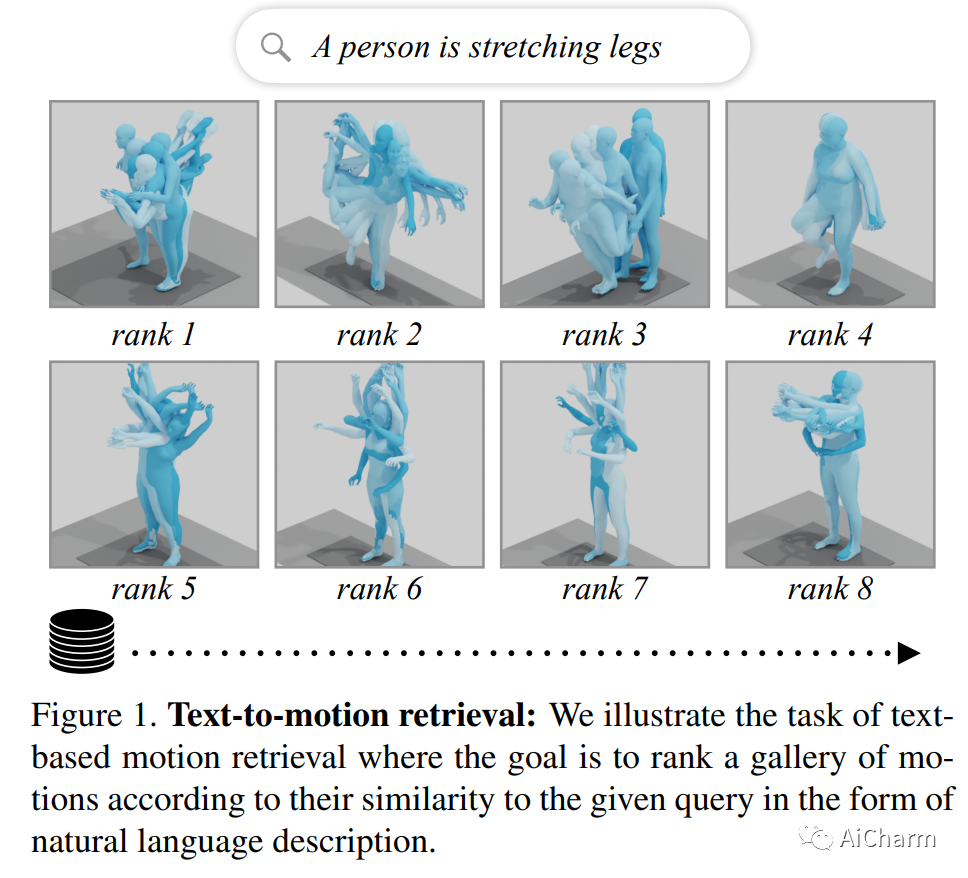
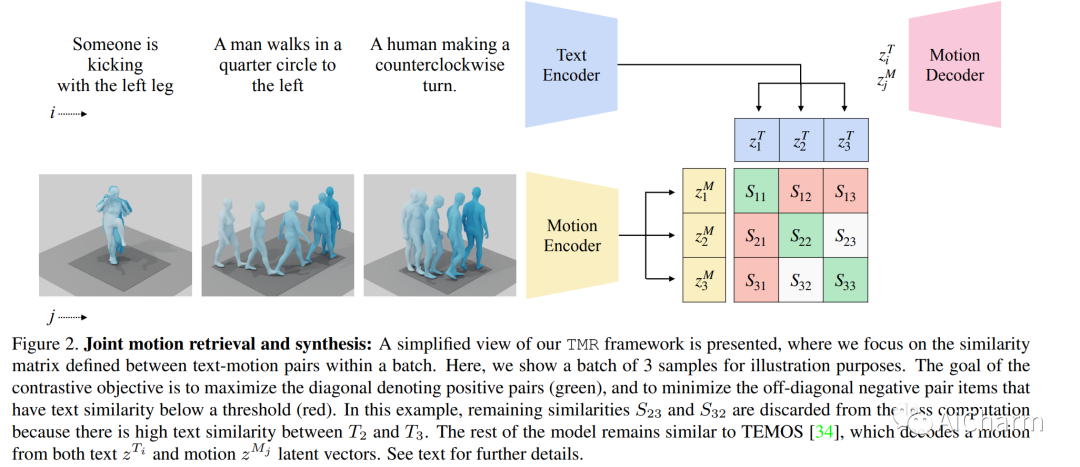

摘要:
在本文中,我们介绍了 TMR,这是一种简单而有效的文本到 3D 人体运动检索方法。虽然以前的工作只将检索作为代理评估指标,但我们将其作为一项独立任务来处理。我们的方法扩展了最先进的文本到运动合成模型 TEMOS,并结合了对比损失以更好地构建跨模态潜在空间。我们表明,保持运动生成损失以及对比训练对于获得良好性能至关重要。我们引入了评估基准,并通过报告几种协议的结果来提供深入分析。我们在 KIT-ML 和 HumanML3D 数据集上进行的大量实验表明,TMR 的性能明显优于之前的工作,例如,将中位数排名从 54 降低到 19。最后,我们展示了我们的方法在矩检索方面的潜力。我们的代码和模型是公开的。
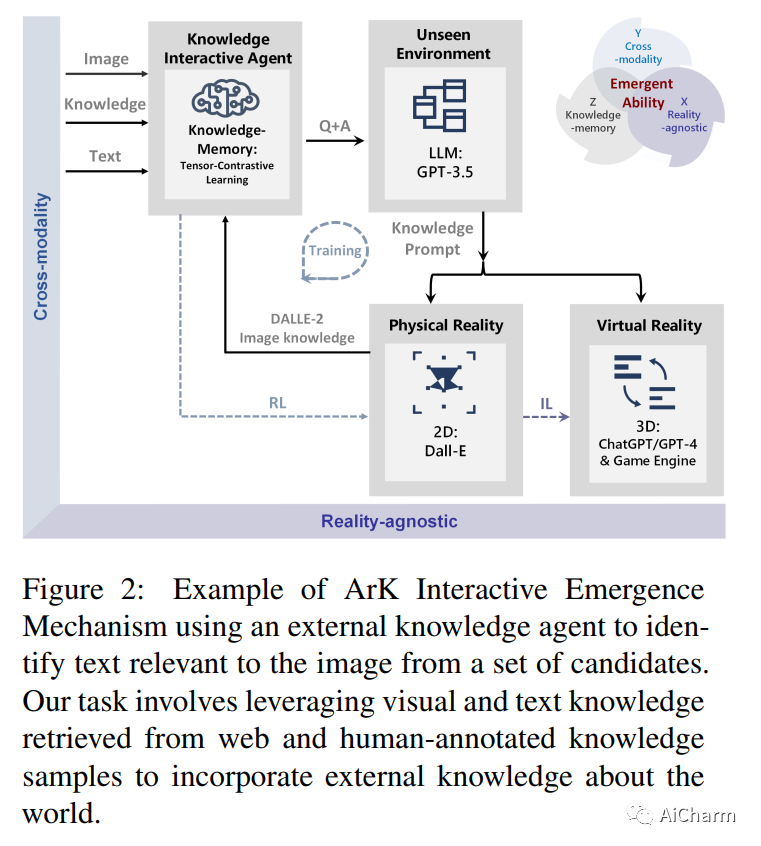
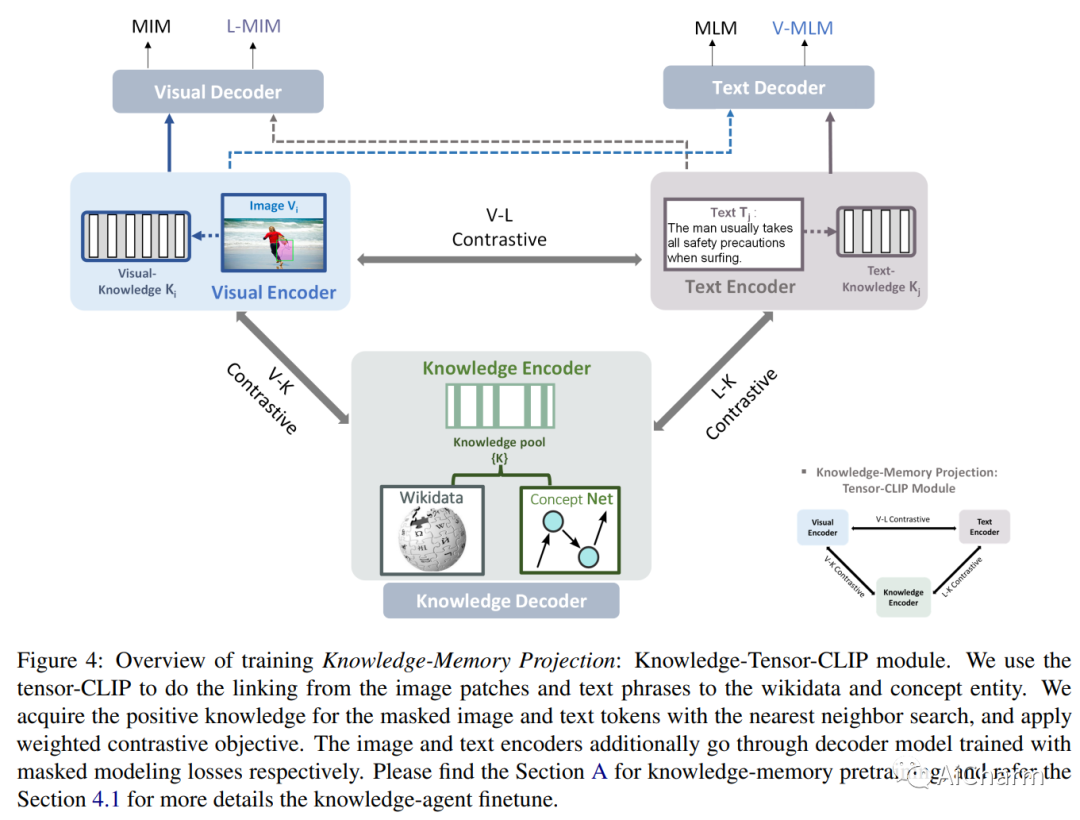
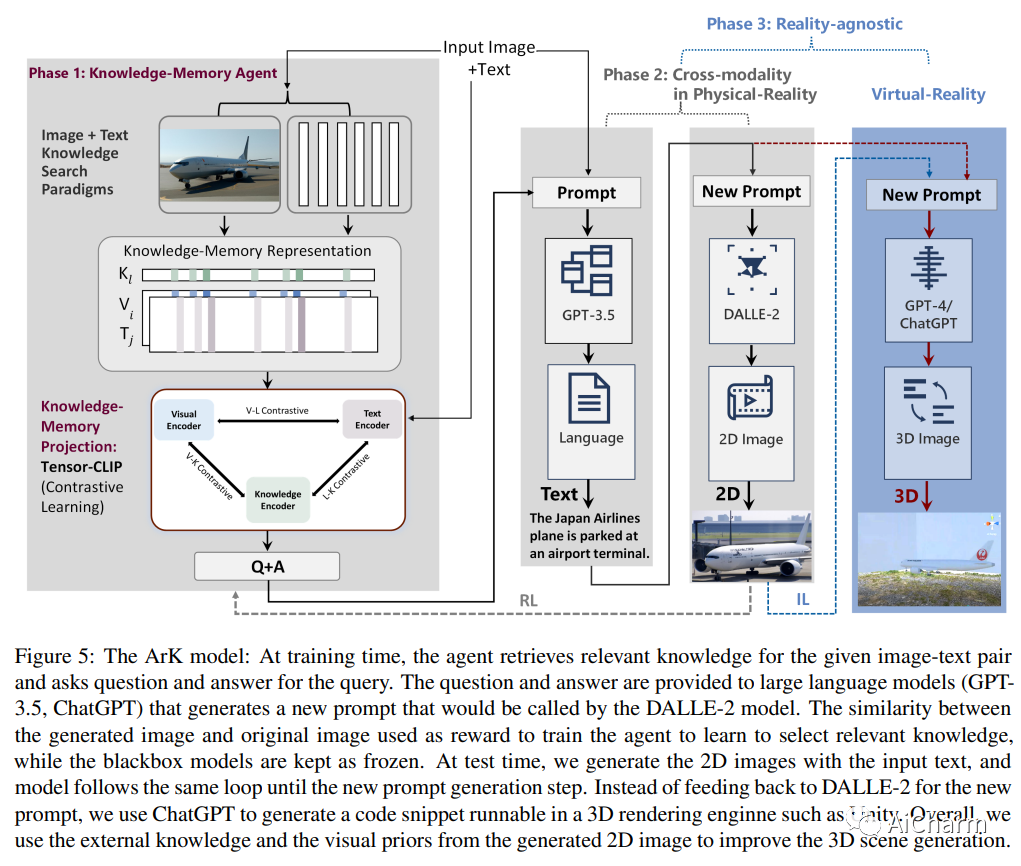
3.ArK: Augmented Reality with Knowledge Interactive Emergent Ability

标题:Ark:增强现实与知识互动涌现能力
作者:Qiuyuan Huang, Jae Sung Park, Abhinav Gupta, Paul Bennett, Ran Gong, Subhojit Som, Baolin Peng, Owais Khan Mohammed, Chris Pal, Yejin Choi, Jianfeng Gao
文章链接:https://arxiv.org/abs/2304.05977
项目代码:https://github.com/THUDM/ImageReward


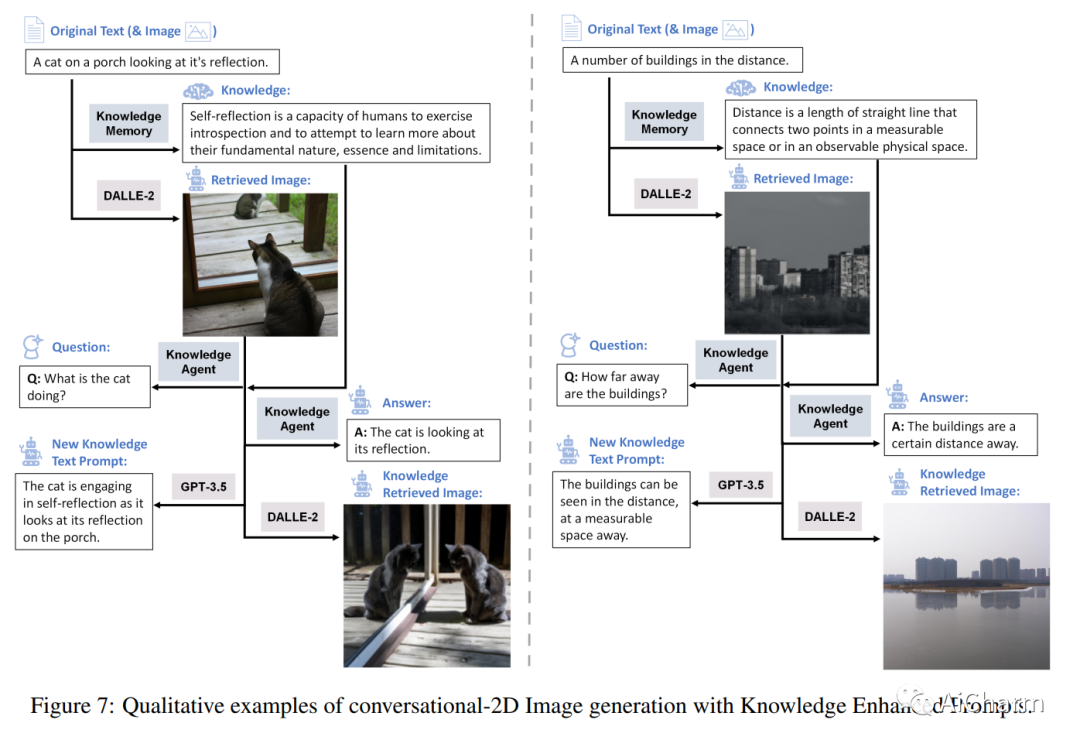
摘要:
尽管越来越多地采用混合现实和交互式 AI 代理,但这些系统在看不见的环境中生成高质量的 2D/3D 场景仍然具有挑战性。通常的做法需要部署一个 AI 代理来收集大量数据,以便为每个新任务进行模型训练。对于许多领域来说,这个过程是昂贵的,甚至是不可能的。在这项研究中,我们开发了一个无限代理,它学习将知识记忆从一般基础模型(例如 GPT4、DALLE)转移到新的领域或场景,以在物理或虚拟世界中进行场景理解和生成。我们方法的核心是一种新兴机制,称为知识推理交互增强现实 (ArK),它利用知识记忆在看不见的物理世界和虚拟现实环境中生成场景。知识交互涌现能力(图 1)被展示为观察学习 i)跨模态的微动作:在多模态模型中为每个交互任务收集大量相关知识记忆数据(例如,看不见的场景理解) 来自物理现实;ii) 与现实无关的宏观行为:在混合现实环境中改进针对不同特征角色、目标变量、协作信息等定制的交互。我们验证了 ArK 在场景生成和编辑任务上的有效性。我们展示了我们的 ArK 方法与大型基础模型相结合,与基线相比显着提高了生成的 2D/3D 场景的质量,展示了将 ArK 结合到生成 AI 中用于元宇宙和游戏模拟等应用程序的潜在好处。
更多Ai资讯:公主号AiCharm

















 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











