






1.FANet: Feature Amplification Network for Semantic Segmentation in Cluttered Background

标题: FANet:杂乱背景下语义分割的特征放大网络
作者:Muhammad Ali, Mamoona Javaid, Mubashir Noman, Mustansar Fiaz, Salman Khan
文章链接:https://arxiv.org/abs/2407.09379





摘要:
现有的深度学习方法忽略了在复杂场景中存在的语义分割中至关重要的语义线索,包括杂乱的背景和半透明物体等。为了应对这些挑战,我们提出了一种特征放大网络(FANet)作为融合语义信息的骨干网络在多阶段使用新颖的特征增强模块。为了实现这一目标,我们提出了一种自适应特征增强(AFE)模块,它以并行方式受益于空间上下文模块(SCM)和特征细化模块(FRM)。SCM 旨在利用更大的内核杠杆来增加感受野,以处理场景中的尺度变化。而我们新颖的 FRM 负责生成语义线索,可以捕获低频和高频区域,以实现更好的分割任务。我们对具有挑战性的现实世界 ZeroWaste-f 数据集进行了实验,该数据集包含背景杂乱和半透明的对象。我们的实验结果证明了与现有方法相比最先进的性能。
这篇论文试图解决什么问题?
这篇论文提出了一种名为特征放大网络(Feature Amplification Network, FANet)的新方法,旨在解决现有深度学习方法在复杂场景中进行语义分割时忽略的关键问题。这些复杂场景包括背景杂乱、半透明物体等,这些因素使得语义分割任务变得更加困难。具体来说,论文试图解决以下挑战:
-
半透明物体的分割:由于半透明物体的固有性质,如不清晰的边界和背景之间的模糊,使得模型难以准确分割。
-
背景杂乱:背景中的杂乱元素使得物体的外观表示变得模糊不清,增加了分割的难度。
-
尺度变化:场景中物体的不同尺寸变化增加了捕捉细节的难度。
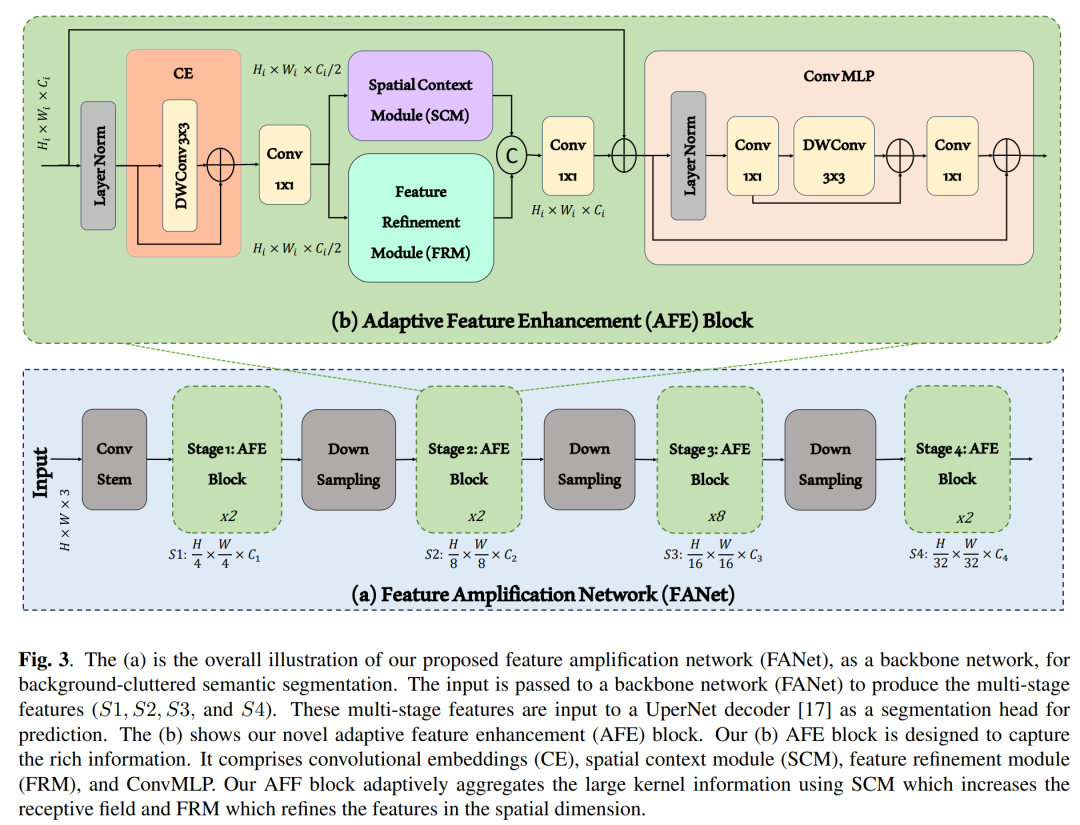
为了应对这些挑战,论文提出了FANet,这是一个包含新颖的特征增强模块(Adaptive Feature Enhancement, AFE)的网络,该模块利用空间上下文模块(Spatial Context Module, SCM)和特征细化模块(Feature Refinement Module, FRM)来增强特征信息,从而在多阶段提取更全面的特征,以更好地区分对象边界。通过这种方式,FANet能够更有效地处理复杂场景中的语义分割任务。
论文如何解决这个问题?
论文通过提出一种名为特征放大网络(Feature Amplification Network, FANet)的方法来解决在复杂场景中进行语义分割的问题。FANet的设计包括以下几个关键组件和策略:
-
自适应特征增强(Adaptive Feature Enhancement, AFE)块:这是FANet的核心,旨在通过并行的方式利用空间上下文模块(Spatial Context Module, SCM)和特征细化模块(Feature Refinement Module, FRM)来增强特征。
-
空间上下文模块(SCM):该模块使用较大的卷积核(例如7x7)来增加感受野,从而能够更好地处理场景中的尺度变化。
-
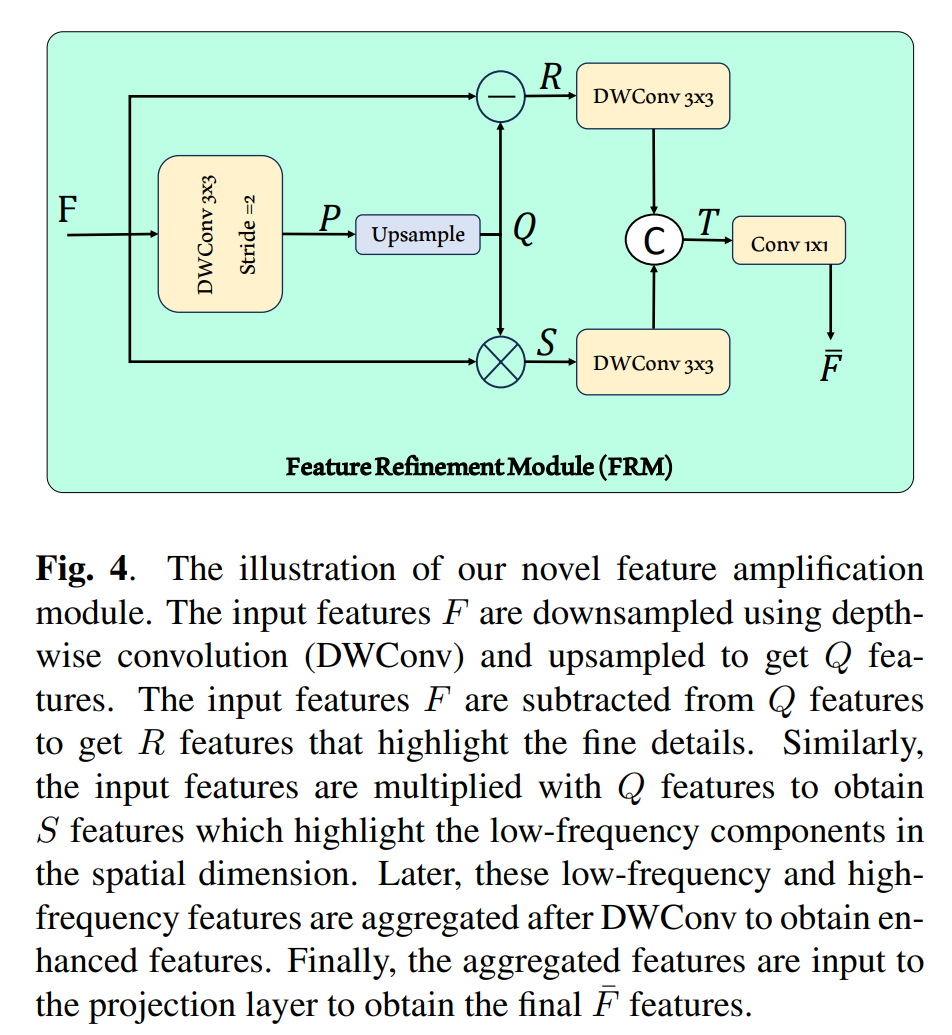
特征细化模块(FRM):这是论文中提出的一个新颖模块,受到图像锐化和对比度增强概念的启发,旨在捕获低频和高频区域,以实现更好的特征细化。
-
多阶段特征生成:FANet能够生成多阶段特征(S1, S2, S3, 和 S4),这些特征通过非重叠的卷积干线层输入,并经过AFE块进行增强。
-
深度监督和损失函数:在训练过程中,FANet利用深度监督来确保每个阶段的特征都能为最终的分割任务做出贡献。
-
实验验证:作者在具有挑战性的ZeroWaste-f数据集上进行了实验,该数据集包含背景杂乱和半透明物体。实验结果表明,FANet与现有方法相比,具有最先进的性能。
-
开源代码:为了促进研究和进一步的开发,作者还提供了FANet的源代码链接。
通过这些策略,FANet能够有效地捕获目标对象的内在属性,并从复杂场景中分割出对象,尤其是在背景杂乱的情况下。这些设计选择使得FANet能够更好地处理语义分割中的挑战,如半透明物体的分割、背景杂乱和尺度变化等问题。
论文做了哪些实验?
论文中进行了以下实验来验证所提出的FANet(Feature Amplification Network)的性能和有效性:
-
数据集选择:选择了ZeroWaste-f数据集进行实验,该数据集专为复杂环境中的垃圾管理和分割设计,包含多种垃圾类型,通常处于杂乱和重叠的状态。
-
评估指标:使用了平均交并比(mean Intersection over Union, mIoU)和像素准确率(pixel accuracy)作为性能评估指标。
-
实现细节:在PyTorch框架上实现了FANet,并在NVIDIA V100 GPU上进行训练。使用了MMSegmentation开源工具箱,并采用了预训练在ImageNet-1K数据集上的权重初始化模型。
-
训练细节:模型在ZeroWaste数据集上进行了40k次迭代的训练。使用AdamW优化器,并采用了多项式衰减策略,初始学习率为9e-5。
-
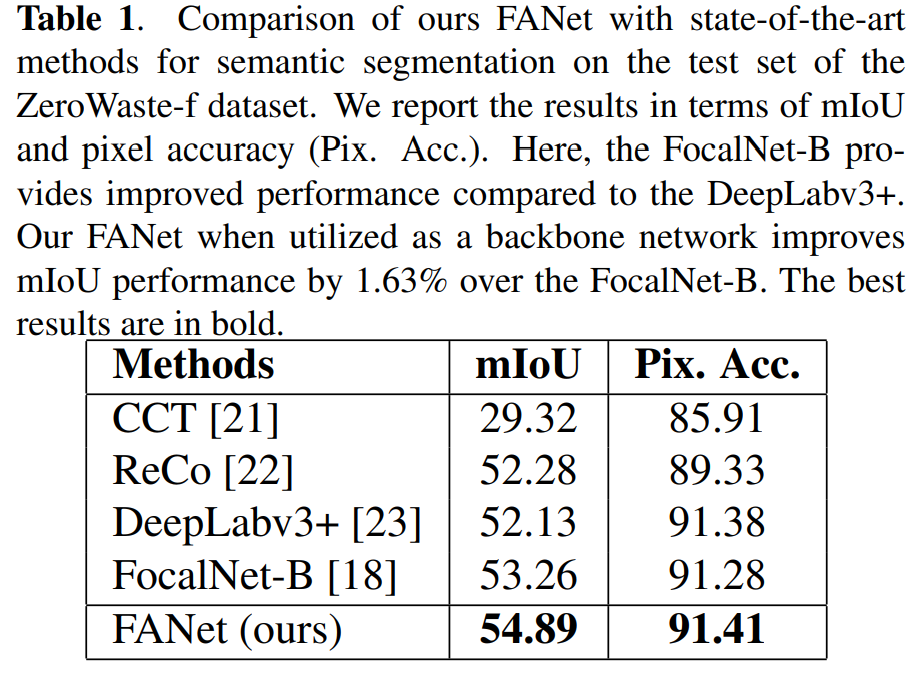
定量比较:与现有的最先进方法(如CCT, ReCo, DeepLabV3+, 和 FocalNet-B)在ZeroWaste-f数据集上进行了性能比较,FANet在mIoU和像素准确率上均取得了更好的结果。
-
定性比较:通过可视化的方式展示了FANet与DeepLabV3+和FocalNet-B在ZeroWaste-f数据集上的分割效果比较,证明了FANet在复杂场景中分割对象的能力。
-
消融研究:进行了消融实验来分析FANet中不同组件(如SCM和FRM)的影响。实验结果表明,SCM和FRM的整合显著提高了模型的性能。
-
参数和计算复杂度比较:将FANet与FocalNet-T和FocalNet-B在参数数量、mIoU和像素准确率方面进行了比较,证明了FANet在减少参数的同时保持了高性能。
-
特征可视化:通过特征可视化展示了FRM的有效性,展示了在复杂环境中FRM如何保留低频和高频组件以实现更好的语义分割。
-
ImageNet-1K验证集上的比较:将FANet与FocalNet-T在ImageNet-1K验证集上进行了比较,以评估模型在更广泛图像识别任务上的性能。
这些实验全面评估了FANet在语义分割任务上的性能,并展示了其在处理复杂场景和提高分割精度方面的潜力。
论文的主要内容:
这篇论文的主要内容包括以下几个方面:
-
问题陈述:论文指出了现有深度学习方法在处理复杂场景(如背景杂乱、半透明物体等)的语义分割任务时存在的问题。
-
FANet提出:为了解决上述问题,论文提出了一种名为特征放大网络(Feature Amplification Network, FANet)的新方法。
-
关键组件:
-
自适应特征增强(AFE)块:包含空间上下文模块(SCM)和特征细化模块(FRM),用于提取更丰富的特征。
-
SCM:利用大卷积核增加感受野,处理尺度变化。
-
FRM:受图像锐化和对比度增强启发,同时捕获低频和高频区域。
-
-
网络架构:FANet的总体架构包括多个阶段,每个阶段使用AFE块来提取多尺度特征,并通过UperNet解码器生成最终的分割结果。
-
实验验证:在ZeroWaste-f数据集上进行了实验,与现有方法相比,FANet在mIoU和像素准确率上取得了更好的性能。
-
消融研究:通过消融实验验证了SCM和FRM的有效性,证明了这些组件对提高性能的重要性。
-
定性分析:通过可视化结果展示了FANet在复杂场景中分割对象的能力。
-
参数和计算效率:论文还比较了FANet与其他方法在参数数量和计算复杂度方面的差异。
-
开源代码:作者提供了FANet的源代码,以促进进一步的研究和开发。
-
结论:论文总结了FANet在复杂场景下进行语义分割的有效性,并指出了未来可能的研究方向。
总的来说,这篇论文通过提出FANet,为复杂背景下的语义分割任务提供了一种新的解决方案,并通过一系列实验验证了其有效性。
2.VGBench: Evaluating Large Language Models on Vector Graphics Understanding and Generation

标题: VGBench:评估矢量图形理解和生成的大型语言模型
作者: Bocheng Zou, Mu Cai, Jianrui Zhang, Yong Jae Lee
文章链接:https://arxiv.org/abs/2407.10972
项目代码:https://vgbench.github.io/
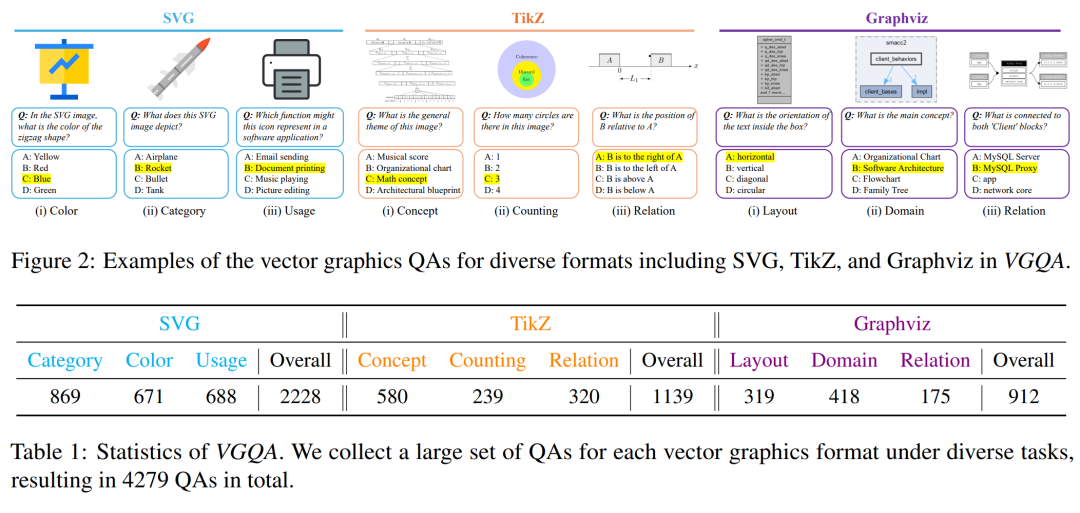
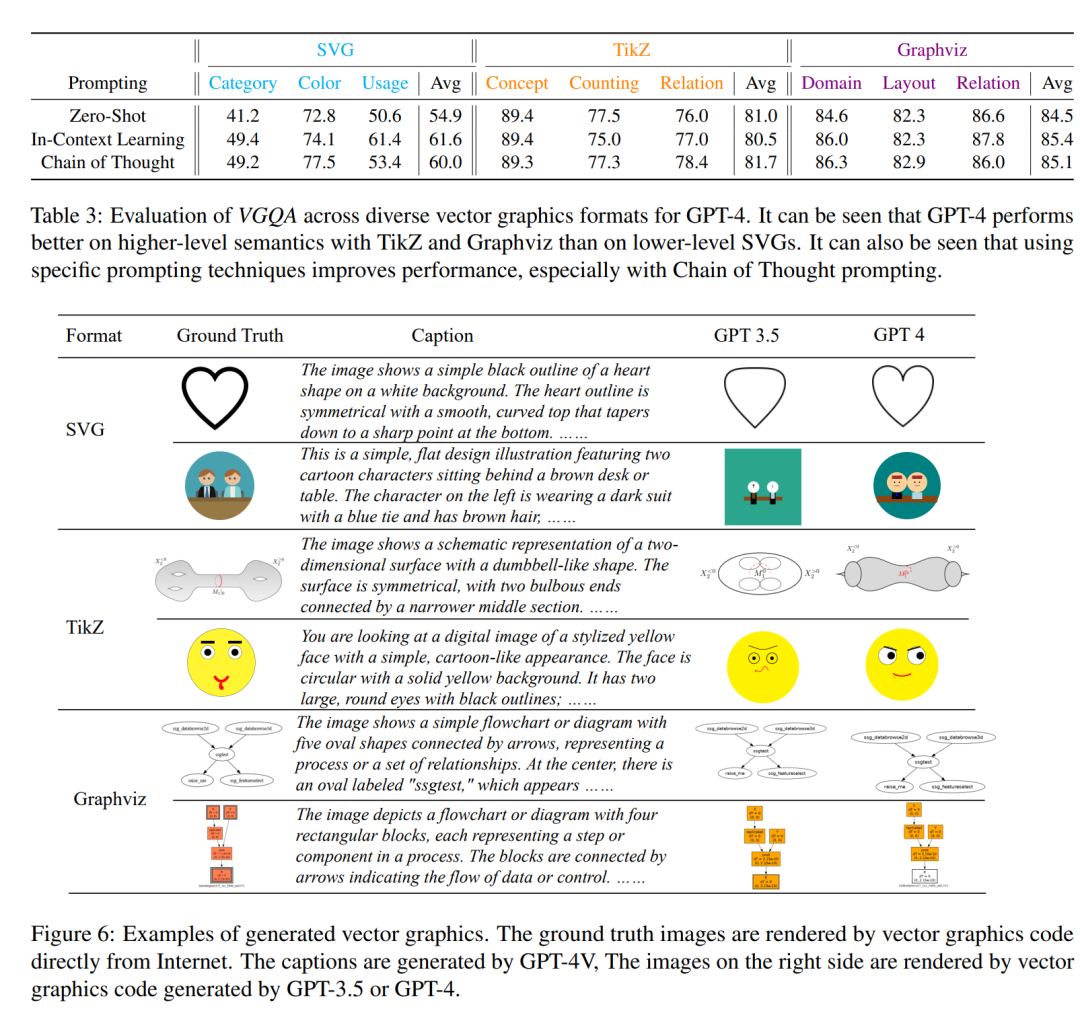
摘要:
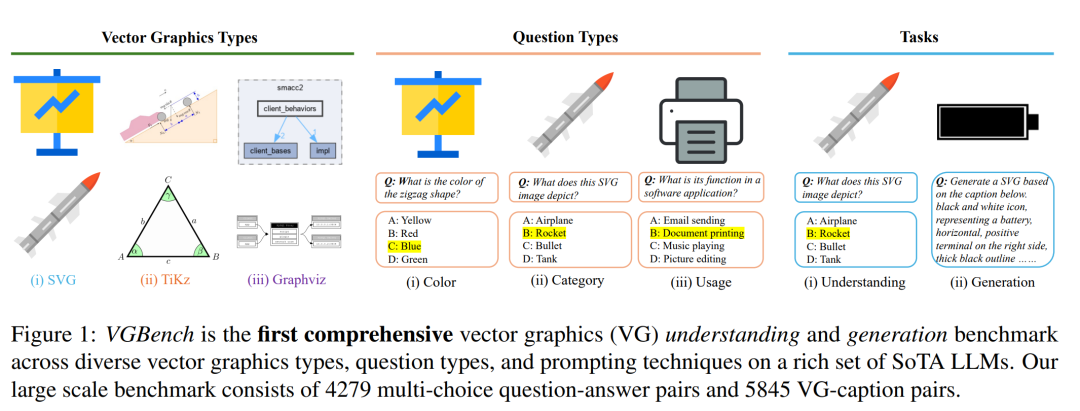
在视觉模型领域,主要的表示模式是使用像素来栅格化视觉世界。然而,这并不总是表示视觉内容的最佳或独特方式,特别是对于使用多边形等几何基元描绘世界的设计师和艺术家而言。另一方面,矢量图形 (VG) 提供视觉内容的文本表示,对于卡通或草图等内容来说可以更加简洁和强大。最近的研究表明,使用大型语言模型 (LLMs) 处理矢量图形会取得可喜的结果。然而,此类作品仅关注定性结果、理解或特定类型的矢量图形。我们提出了 VGBench,这是一个针对 LLMs 的综合基准,通过不同方面处理矢量图形,包括(a)视觉理解和生成,(b)各种矢量图形格式的评估,(c)不同的问题类型, (d) 广泛的提示技巧,(e) 在多个LLMs下。对我们收集的 4279 个理解样本和 5845 个生成样本进行评估,我们发现 LLMs 在这两方面都表现出很强的能力,但在低级格式 (SVG) 上表现不佳。数据和评估管道都将在此 https URL 上开源。
这篇论文试图解决什么问题?
这篇论文提出了一个名为VGBench的全面基准测试,旨在评估大型语言模型(LLMs)在处理矢量图形(Vector Graphics,VG)方面的理解与生成能力。具体来说,这项工作试图解决的问题包括:
-
现有视觉模型主要基于像素表示:传统的视觉模型大多使用像素来光栅化视觉世界,但这并不总是表示视觉内容的最佳或唯一的方式,尤其是对于使用几何基本图形(如多边形)来描绘世界的设计师和艺术家。
-
矢量图形的潜力未被充分利用:矢量图形提供了一种文本表示形式,可以更简洁、更强大的表示视觉内容,如卡通或草图。然而,现有的研究主要集中在定性结果、理解或特定类型的矢量图形上。
-
缺乏全面的LLM基准测试:尽管最近的研究表明,使用大型语言模型处理矢量图形有希望取得成果,但社区缺乏一个全面的基准测试,用于评估LLM在矢量图形处理方面的综合能力。
-
评估方法的多样性:VGBench旨在通过不同的方面来全面评估LLMs的矢量图形处理能力,包括视觉理解与生成、不同矢量图形格式的评估、多样化的问题类型、多种提示技术,以及在多个LLMs下的表现。
-
数据和评估流程的开源:作者希望他们的工作能够为LLM在矢量图形理解和生成方面的基准测试提供一个基础,并激励进一步改进这些能力。他们计划将数据集和评估流程开源,以促进社区的发展。
总的来说,VGBench的提出是为了填补现有研究在矢量图形理解和生成方面的空白,提供一个标准化的测试平台,以推动该领域的研究和应用发展。
论文如何解决这个问题?
论文通过以下几个关键步骤来解决评估大型语言模型(LLMs)在矢量图形理解与生成方面的能力问题:
-
创建VGBench基准测试:提出了一个全面的基准测试,用于评估LLMs在处理矢量图形的不同方面,包括视觉理解(VGQA)和生成(VGen)。
-
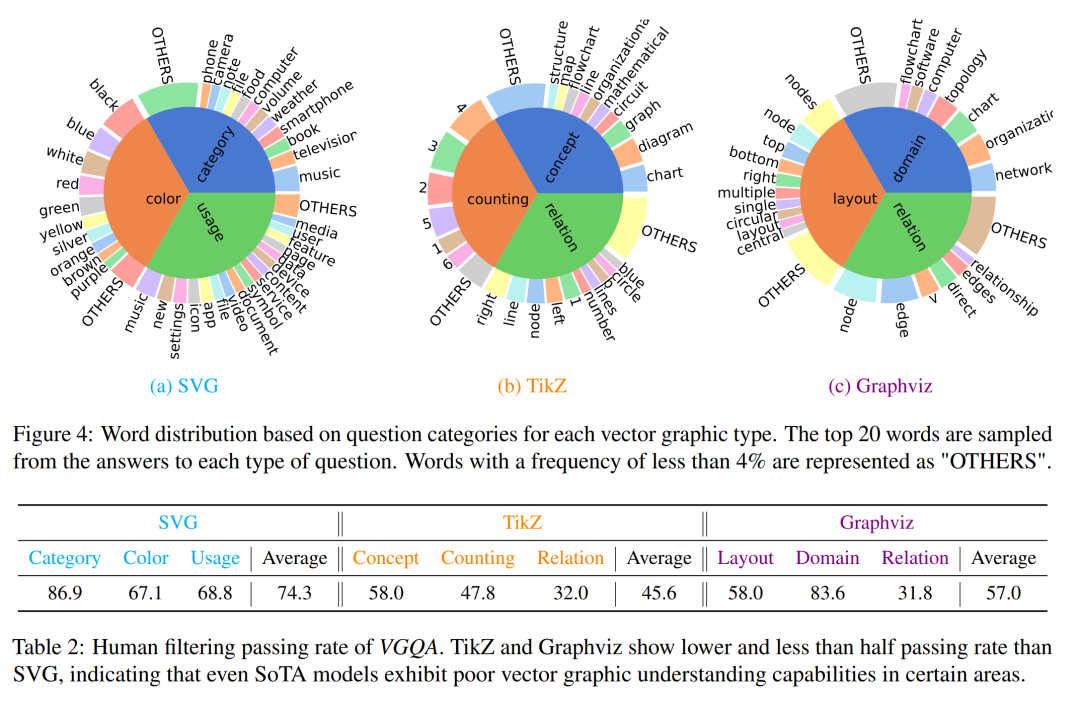
多样化的任务设计:设计了多种任务来全面评估不同语义层次的矢量图形理解能力,包括颜色、类别、用途、概念、计数和关系等。
-
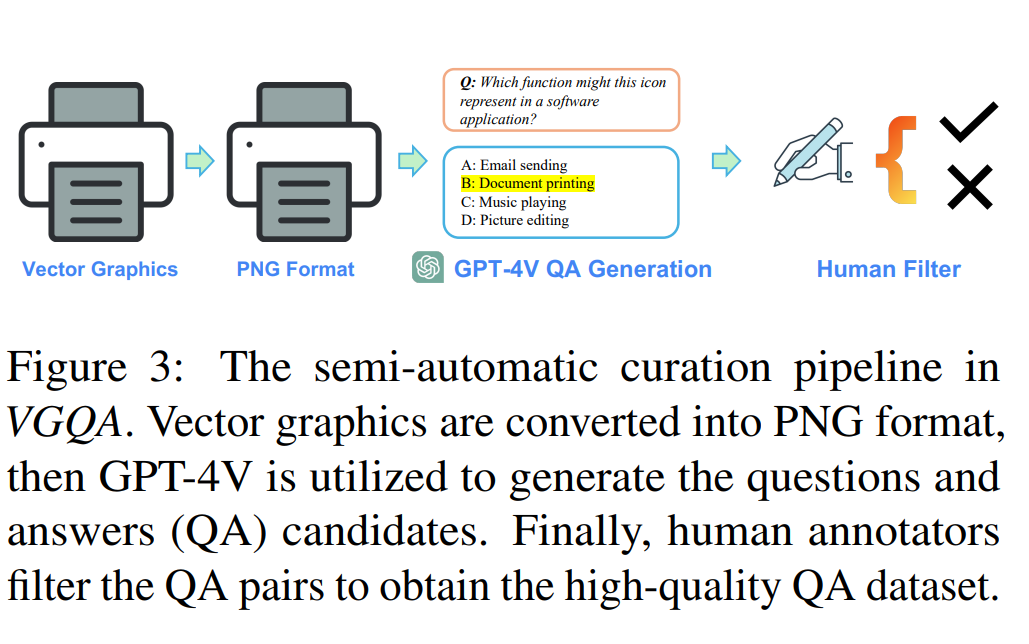
收集和筛选高质量数据:通过半自动化流程收集矢量图形问题-答案(QA)对和矢量图形-标题对。使用GPT-4V生成候选QA对,然后由人类标注者筛选出高质量的数据集。
-
采用多种提示技术:评估了零样本(zero-shot)、思维链(chain-of-thought)和上下文学习(in-context learning)等多种提示技术对LLMs性能的影响。
-
评估多种矢量图形格式:涵盖了SVG、TikZ和Graphviz等不同的矢量图形格式,以评估LLMs对不同格式的理解和生成能力。
-
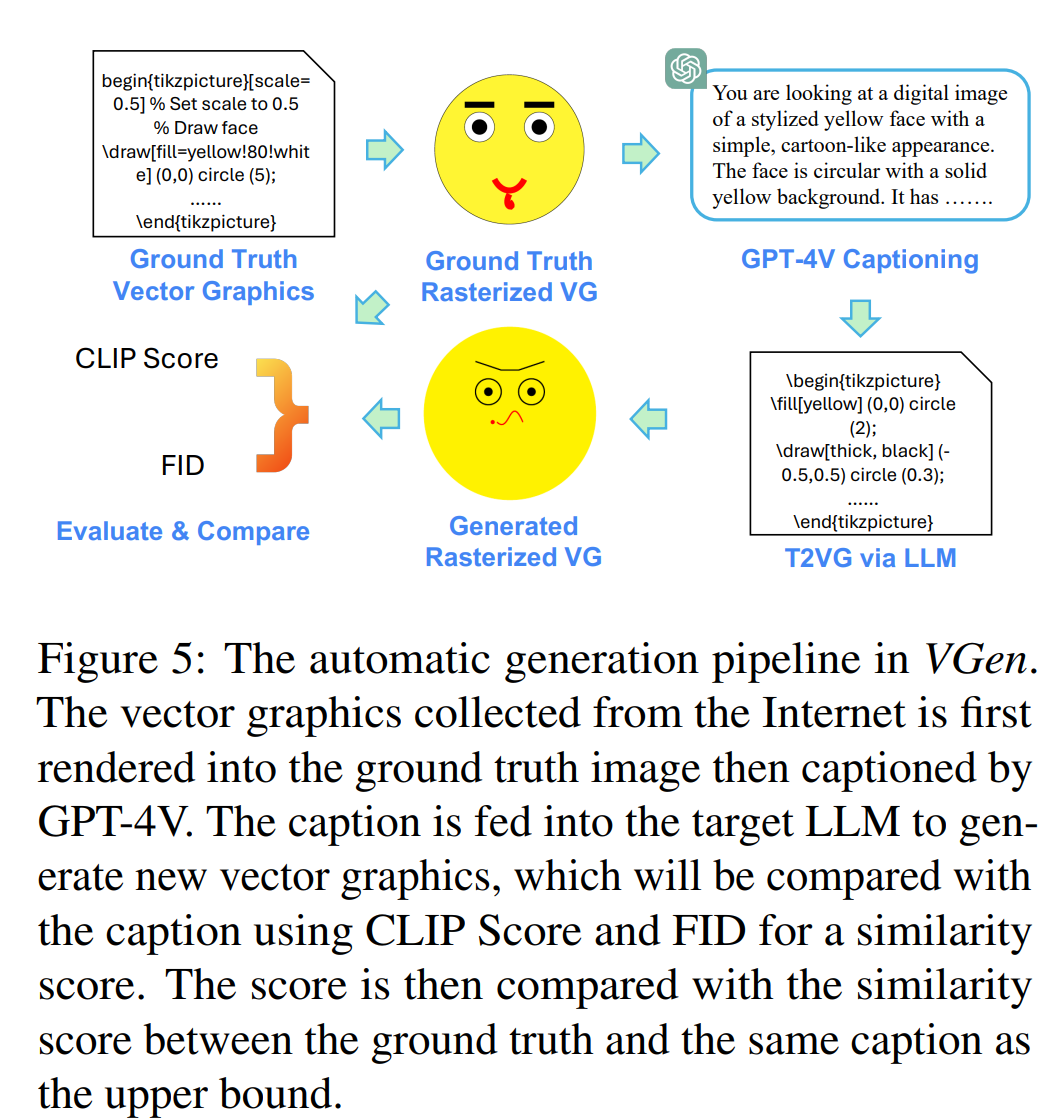
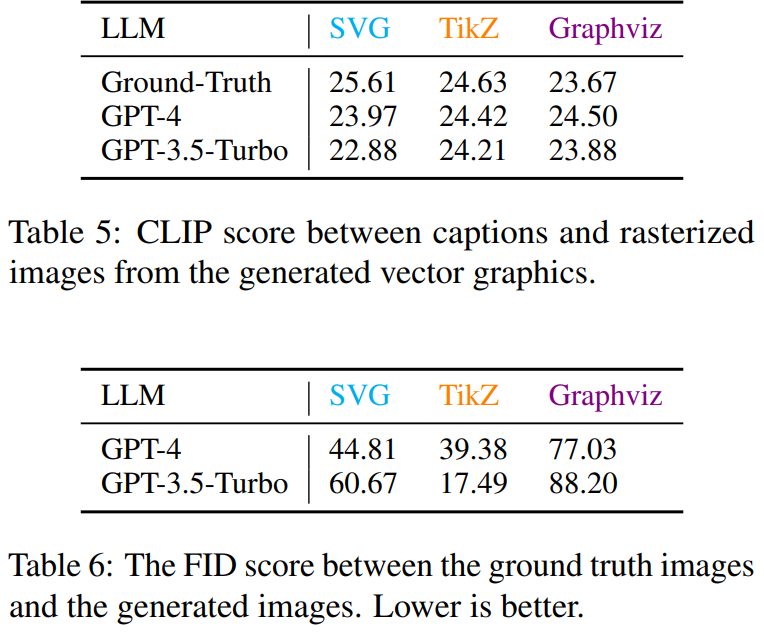
使用先进的评估指标:对于矢量图形生成任务,使用了CLIP Score和Fréchet Inception Distance(FID)等指标来评估生成的矢量图形代码的质量。
-
深入分析:对不同LLMs、不同序列长度和推理过程进行了深入分析,以了解它们在矢量图形理解与生成方面的表现。
-
开源数据和评估流程:计划将收集的数据和评估流程开源,以便社区可以利用这些资源进行进一步的研究和开发。
通过这些步骤,论文不仅提供了一个标准化的测试平台,还通过实际的评估和分析,揭示了LLMs在矢量图形处理方面的优势和局限性,为未来的研究提供了方向和基础。
论文做了哪些实验?
论文中进行了一系列实验来评估大型语言模型(LLMs)在矢量图形理解(VGQA)和生成(VGen)方面的能力。以下是实验的主要部分:
-
数据收集:
-
从不同的源收集SVG、TikZ和Graphviz格式的矢量图形样本。
-
-
实验设置:
-
定义了三种主要的矢量图形类型,并选择了GPT-4作为主要的评估模型,同时也考虑了其他开源的LLMs。
-
-
VGQA:矢量图形理解基准测试:
-
设计了多种任务,包括颜色、类别、用途、概念、计数和关系等问题类型。
-
使用半自动化流程创建基准测试,包括将矢量图形渲染为PNG图像,利用GPT-4V生成问题和答案候选,然后由人类标注者筛选。
-
-
VGen:矢量图形生成基准测试:
-
测试LLMs根据文本提示生成矢量图形代码的能力。
-
使用GPT4V为每个矢量图形图像生成标题,然后提示LLM生成对应的矢量图形代码。
-
-
评估与比较:
-
对于VGQA,将LLMs的回答与正确答案进行比较,计算准确率。
-
对于VGen,将生成的矢量图形映射为光栅图像,并使用CLIP Score和Fréchet Inception Distance (FID)来评估生成矢量图形的质量。
-
-
不同LLMs的影响分析:
-
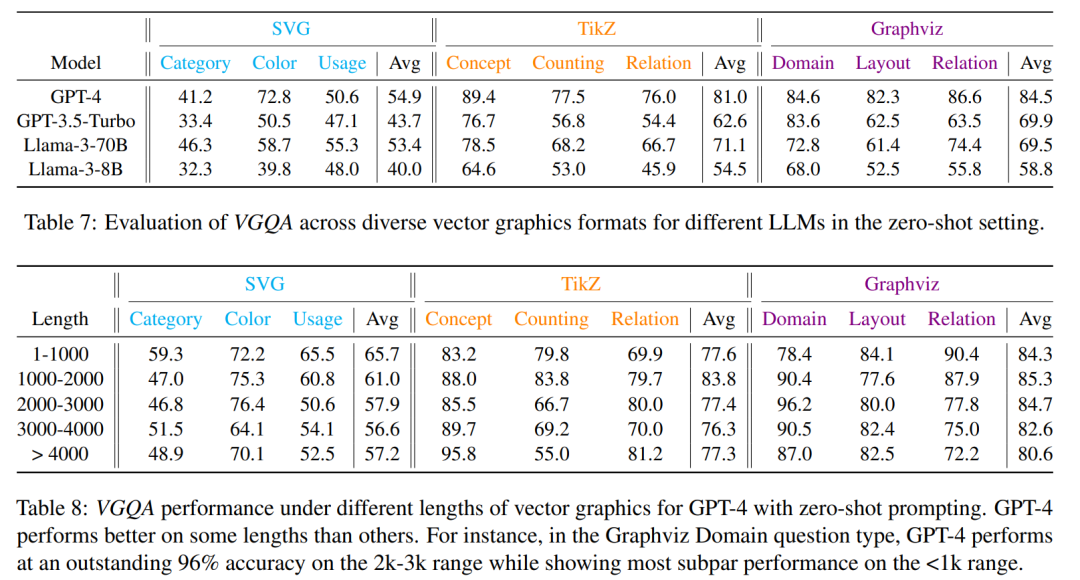
对比了GPT-4、GPT-3.5、Llama-3-70BInstruct和Llama-3-8B-Instruct等不同模型在矢量图形理解任务上的表现。
-
-
矢量图形序列长度的影响分析:
-
研究了矢量图形的长度对LLMs理解性能的影响。
-
-
推理过程分析:
-
展示了GPT-4在使用思维链(Chain-of-Thought)提示时的推理过程。
-
-
深入分析:
-
对不同LLMs、不同序列长度和推理过程进行了详细的分析,以了解它们在矢量图形理解与生成方面的表现。
-
这些实验提供了对LLMs在矢量图形处理方面能力的全面评估,并揭示了它们在不同任务和条件下的性能表现。
论文的主要内容:
这篇论文的主要内容可以概括为以下几个要点:
-
问题提出:指出当前视觉模型主要基于像素表示,但对于矢量图形(VG),这种表示方法并不总是最佳选择。矢量图形提供了一种更简洁、更强大的视觉内容表示方式,尤其是在设计和艺术领域。
-
VGBench基准测试:提出了VGBench,这是一个全面评估LLMs在矢量图形理解与生成方面能力的基准测试。
-
任务与评估:VGBench包括视觉理解(VGQA)和视觉生成(VGen)两个主要任务,并涵盖了多种矢量图形格式、问题类型、提示技术,并在多个LLMs上进行评估。
-
数据收集与处理:通过半自动化流程收集了高质量的矢量图形QA对和VG-caption对,用于评估LLMs的理解与生成能力。
-
实验设置:选择了GPT-4和其他几种LLMs作为评估对象,并采用了零样本、思维链和上下文学习等提示技术。
-
实验结果:发现LLMs在矢量图形理解方面,特别是在TikZ和Graphviz格式上表现出色,而在SVG这种低级格式上表现较差。同时,LLMs在矢量图形生成方面也显示出强大的能力。
-
深入分析:对不同LLMs、不同序列长度和推理过程进行了分析,揭示了LLMs在矢量图形任务中的性能和潜在的改进方向。
-
开源贡献:论文承诺将数据集和评估流程开源,以促进社区进一步的研究和开发。
-
结论与未来工作:论文总结了LLMs在矢量图形理解和生成方面的能力,并提出了未来研究的方向,包括探索新的提示技术、模型优化和跨领域应用等。
-
局限性与致谢:论文讨论了研究的局限性,并感谢了支持这项研究的资金和资源提供者。
3.Ref-AVS: Refer and Segment Objects in Audio-Visual Scenes

标题: Ref-AVS:在视听场景中引用和分割对象
作者:Yaoting Wang, Peiwen Sun, Dongzhan Zhou, Guangyao Li, Honggang Zhang, Di Hu
文章链接:https://arxiv.org/abs/2407.10957
项目代码:https://gewu-lab.github.io/Ref-AVS/
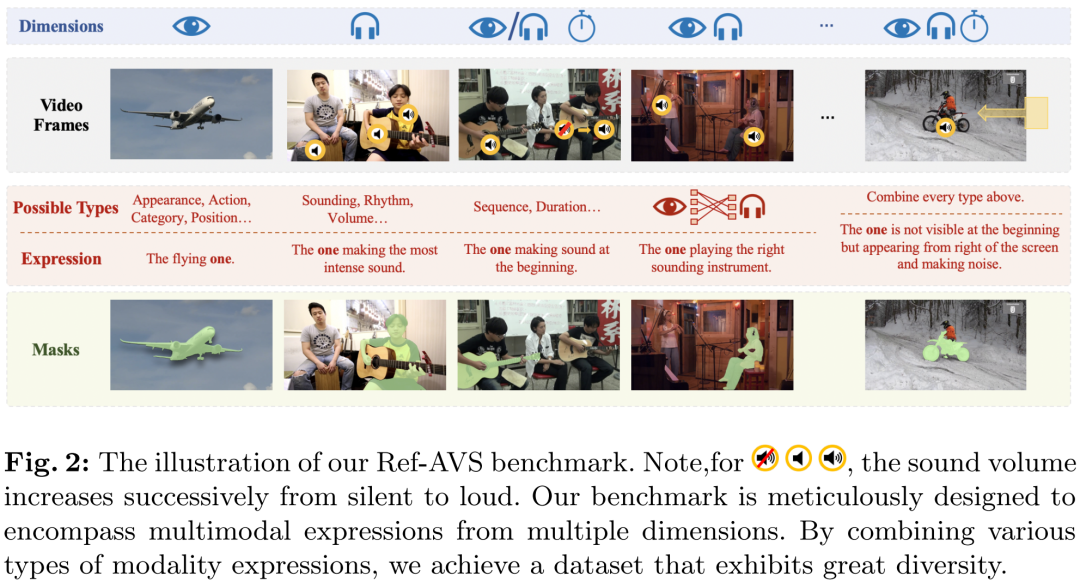

摘要:
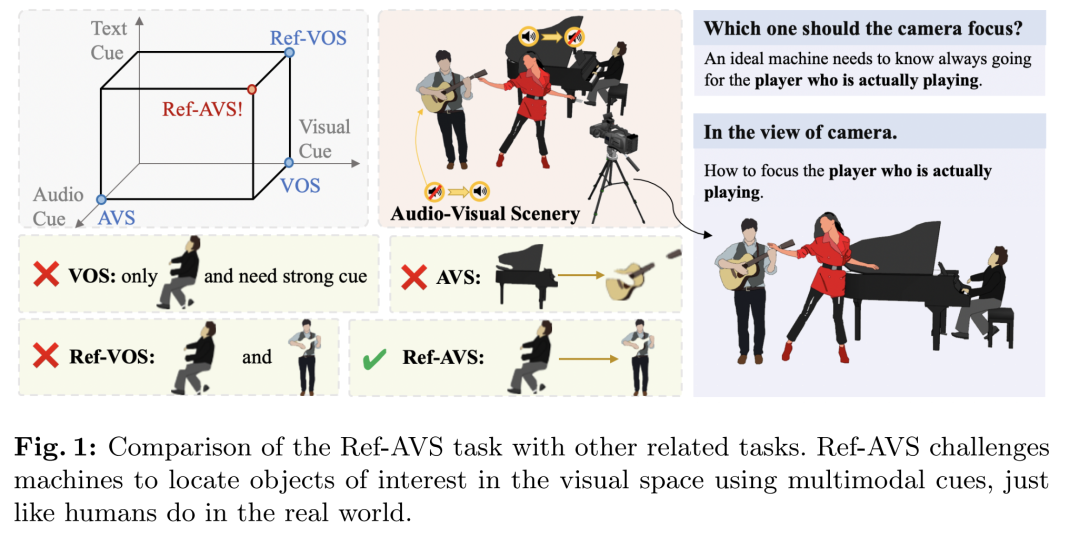
传统的参考分割任务主要关注安静的视觉场景,忽略了多模态感知和交互在人类体验中的不可或缺的作用。在这项工作中,我们引入了一项名为参考视听分割(Ref-AVS)的新颖任务,该任务旨在基于包含多模态线索的表达来分割视觉域内的对象。这些表达以自然语言形式表达,但富含多模态线索,包括音频和视觉描述。为了促进这项研究,我们构建了第一个 Ref-AVS 基准,它为相应的多模态提示表达式中描述的对象提供像素级注释。为了解决 Ref-AVS 任务,我们提出了一种新方法,该方法充分利用多模态线索来提供精确的分割指导。最后,我们对三个测试子集进行定量和定性实验,以将我们的方法与相关任务的现有方法进行比较。结果证明了我们方法的有效性,突出了其使用多模态提示表达式精确分割对象的能力。
这篇论文试图解决什么问题?
这篇论文介绍了一种名为“Ref-AVS”(Reference Audio-Visual Segmentation)的新任务,旨在解决以下问题:
-
多模态信息融合:传统视觉场景分割任务通常只关注单一模态(如视觉或文本),而忽略了真实世界中多模态信息(如音频、视觉和文本)的整合。Ref-AVS任务旨在利用包含多模态线索(如音频和视觉描述)的自然语言表达式来分割视觉领域中的对象。
-
动态音频-视觉场景中的对象定位:在动态且复杂的音频-视觉场景中,如何准确定位和分割用户感兴趣的对象是一个挑战。Ref-AVS任务要求机器能够理解多模态表达式,并在视觉空间中精确地定位和分割出表达式所描述的对象。
-
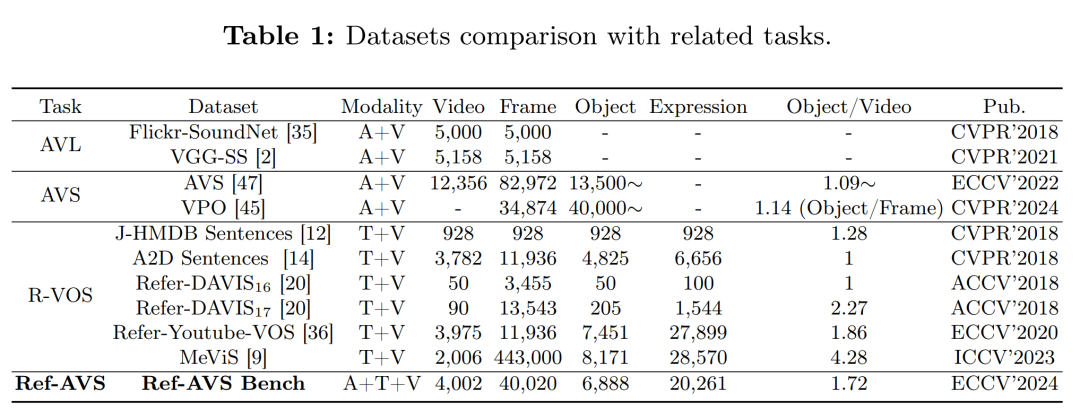
构建基准数据集:为了推动这一领域的研究,作者构建了第一个Ref-AVS基准测试(Ref-AVS Bench),提供了对应多模态线索表达式的像素级注释,以便在多模态环境中进行对象描述。
-
跨模态交互和理解:现有的分割方法在处理多模态信息时存在局限性,Ref-AVS任务通过引入多模态线索,促进了对不同模态之间交互和理解的研究。
-
实际应用中的挑战:例如在音乐会场景中定位正在演奏乐器的音乐家,或者在电影场景中定位在特定背景下的特定对象。这些场景要求机器能够综合音频和视觉信息,以实现更自然和动态的对象分割。
通过提出Ref-AVS任务和相应的基准测试,论文旨在推动多模态学习和理解在视觉分割任务中的应用,提高机器在复杂环境中对用户指令的响应能力和精确度。
论文如何解决这个问题?
论文通过以下几个关键步骤来解决Ref-AVS(Reference Audio-Visual Segmentation)任务中的问题:
-
构建基准数据集(Ref-AVS Bench):
-
收集了约4,000个可听视频剪辑,超过60%是多源声音场景。
-
收集并验证了超过20,000个参考表达式,这些表达式采用多模态线索描述多样化和动态的音频-视觉场景。
-
-
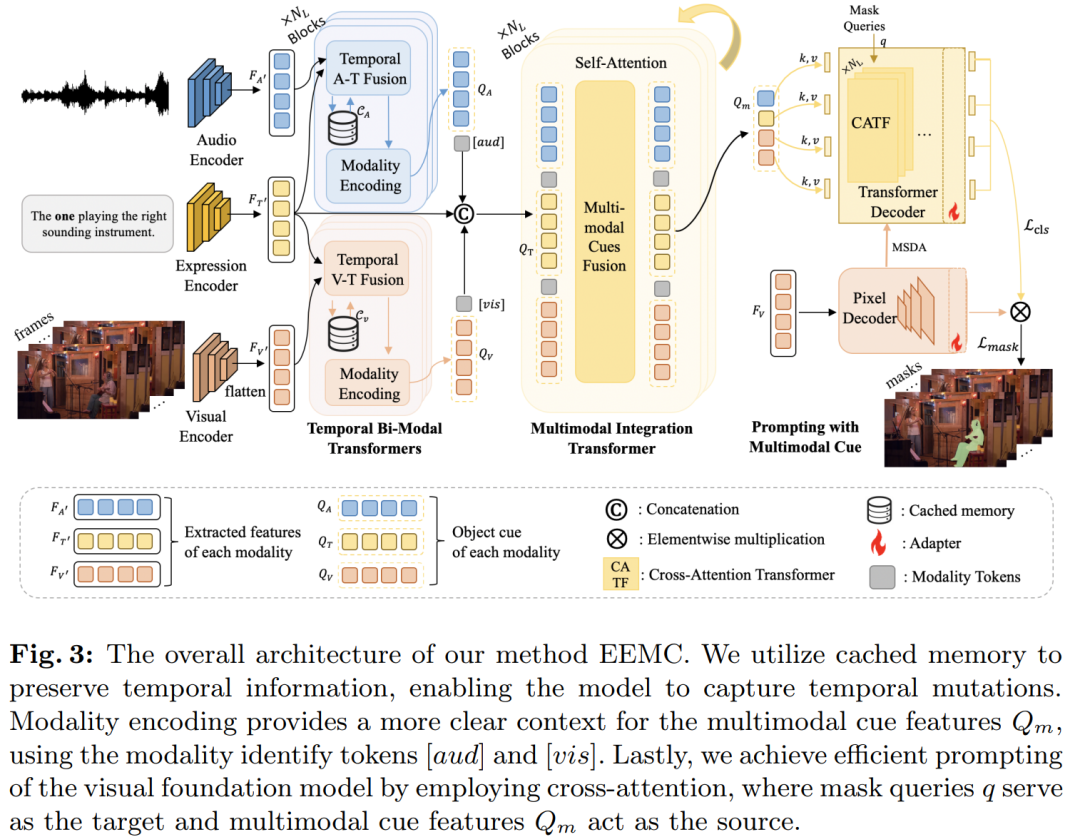
设计端到端框架:
-
提出了一个名为“Expression Enhancing with Multimodal Cues (EEMC)”的方法,该方法有效地处理多模态线索,并将其作为分割指导。
-
-
多模态表示:
-
音频表示:使用VGGish从音频输入中提取特征。
-
视觉表示:使用预训练的Swin-base模型从视频输入中提取特征。
-
表达式表示:使用RoBERTa提取文本表达式的特征。
-
-
时序双模态变换器(Temporal Bi-modal Transformer):
-
引入模块以检索每种模态的表达式相关信息,并通过自注意力机制融合模态特征。
-
使用缓存记忆(Cached Memory)来显式捕获时间域中的变化。
-
-
多模态编码(Modality Encoding):
-
将模态标识符(如[aud]和[vis])融入到多模态线索整合过程中,以增强模态感知。
-
-
多模态线索提示(Prompting with Multimodal Cues, PMC):
-
将多模态线索特征通过自注意力机制融合,形成综合的多模态线索。
-
使用这些线索作为提示,通过交叉注意力机制更新可学习的掩码查询,以促进最终的分割过程。
-
-
实验验证:
-
在三个测试子集上进行定量和定性实验,与相关任务的现有方法进行比较。
-
结果表明,所提出的方法能够有效地使用多模态线索表达式进行精确的对象分割。
-
-
数据集分割:
-
将数据集分为训练集、验证集和测试集,并进一步将测试集分为“seen”(见过的类别)、“unseen”(未见过的类别)和“null”(空引用问题)子集,以全面评估模型性能。
-
通过这些步骤,论文不仅提出了一个新的挑战性任务,还构建了相应的基准数据集,并设计了一个有效的端到端框架来处理这一任务,展示了在多模态学习和理解方面的创新和进展。
论文做了哪些实验?
论文中进行了以下实验来验证所提出的Ref-AVS(Reference Audio-Visual Segmentation)方法的有效性:
-
数据集构建和统计:
-
收集了约4,000个视频剪辑,包含超过20,000个参考表达式,并进行了像素级注释。
-
对数据集的多样性和复杂性进行了统计分析,包括对象类别的分布、视频选择的标准、表达式的多样性和准确性。
-
-
实验设置:
-
使用Mask2Former作为视觉基础模型,提供了一个常用的基于变换器的分割解码器。
-
输入视频帧被缩放到384×384,并对视觉特征进行了8倍下采样以减少计算成本。
-
-
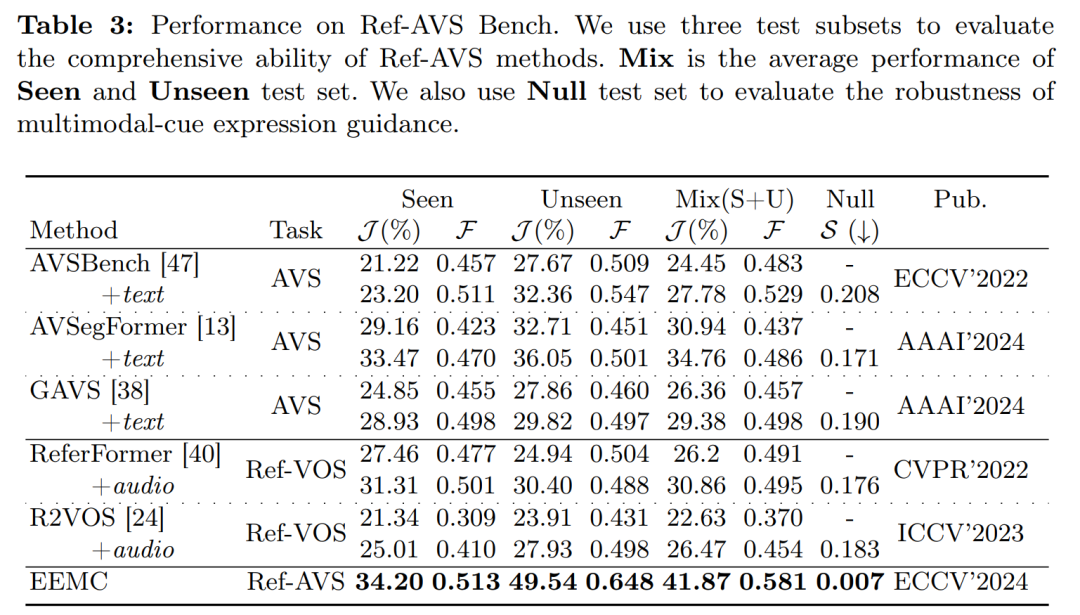
评估指标:
-
使用Jaccard指数(J)和F分数(F)作为性能指标。
-
引入S指数来评估模型在空引用测试集中表达式指导的有效性。
-
-
定量结果:
-
在Ref-AVS Bench数据集的三个测试子集(seen、unseen和null)上比较了所提出方法与其他现有方法的性能。
-
展示了所提出方法在这些子集上的优势,特别是在未见过的类别(unseen)和空引用(null)测试集中。
-
-
定性结果:
-
可视化了Ref-AVS Bench测试集上的分割掩码,并与AVSegFormer和ReferFormer等方法进行了比较。
-
展示了所提出方法在准确解释用户指令和分割目标对象方面的优势。
-
-
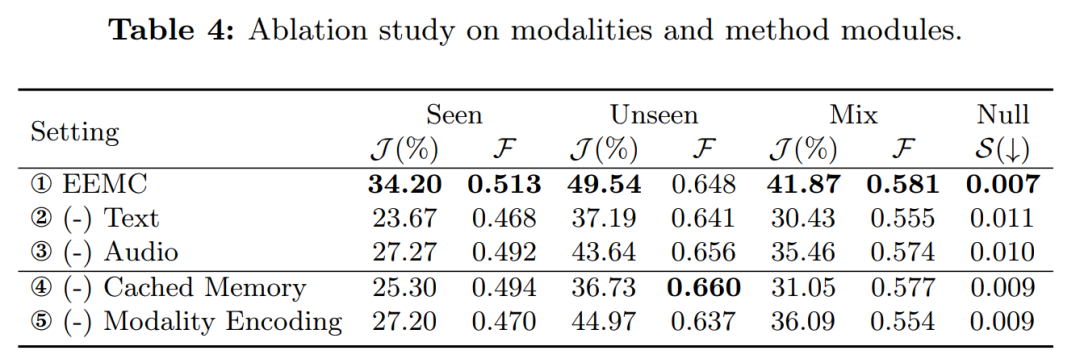
消融研究:
-
对音频和文本信息的影响进行了消融研究,以及所提出方法中不同模块的有效性。
-
通过去除文本信息、音频信息、缓存记忆和模态编码等模块,展示了这些组件对整体性能的贡献。
-
-
系统延迟:
-
测量了所提出方法在1×RTX 3090上的推理速度,为2 FPS,并讨论了可能的加速方法,如剪枝和量化。
-
-
补充材料:
-
提供了额外的数据集统计和示例,以及数据收集流程的详细说明。
-
讨论了表达式模板、表达式分级系统以及如何确保表达式的唯一性、必要性和清晰度。
-
通过这些实验,论文全面评估了所提出方法在Ref-AVS任务中的性能,并展示了其在多模态线索表达式引导下进行精确对象分割的能力。
论文的主要内容:
这篇论文的主要内容包括以下几个方面:
-
任务提出:
-
引入了一个新的任务:Reference Audio-Visual Segmentation (Ref-AVS),旨在基于包含多模态线索(如音频和视觉描述)的自然语言表达式来分割视觉领域中的对象。
-
-
数据集构建:
-
构建了第一个Ref-AVS基准测试(Ref-AVS Bench),包含约4,000个视频剪辑和超过20,000个参考表达式,这些表达式采用多模态线索描述对象。
-
-
方法设计:
-
提出了一种新方法“Expression Enhancing with Multimodal Cues (EEMC)”,该方法利用多模态线索提供精确的分割指导。
-
-
多模态表示:
-
使用VGGish提取音频特征,使用Swin-base模型提取视觉特征,使用RoBERTa提取文本表达式特征。
-
-
时序双模态变换器:
-
引入了Temporal Bi-modal Transformer模块来检索每种模态的表达式相关信息,并通过自注意力机制融合模态特征。
-
-
多模态编码:
-
通过模态标识符(如[aud]和[vis])增强模态感知,整合多模态线索。
-
-
多模态线索提示:
-
使用综合的多模态线索通过交叉注意力机制更新可学习的掩码查询,以促进最终的分割过程。
-
-
实验验证:
-
在Ref-AVS Bench数据集的三个测试子集(seen、unseen和null)上进行了定量和定性实验,与现有方法进行了比较,验证了所提出方法的有效性。
-
-
消融研究:
-
通过去除文本信息、音频信息、缓存记忆和模态编码等模块,展示了这些组件对整体性能的贡献。
-
-
系统延迟:
-
测量了所提出方法在1×RTX 3090上的推理速度,并讨论了可能的加速方法。
-
-
补充材料:
-
提供了额外的数据集统计和示例,以及数据收集流程的详细说明。
-
-
未来工作:
-
论文提出了未来可能的研究方向,包括多模态融合方法的改进、长时依赖性建模、多实例场景的分割等。
-
总的来说,这篇论文通过提出一个新的任务、构建相应的基准数据集,并设计了一个有效的端到端框架,展示了在多模态学习和理解方面的创新和进展。


















 1397
1397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











