







CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CL
1.Improving Factuality and Reasoning in Language Models through Multiagent Debate

标题:通过多主体辩论改进语言模型中的事实性和推理
作者:Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, Igor Mordatch
文章链接:https://arxiv.org/abs/2305.14325
项目代码:https://composable-models.github.io/llm_debate/



摘要:
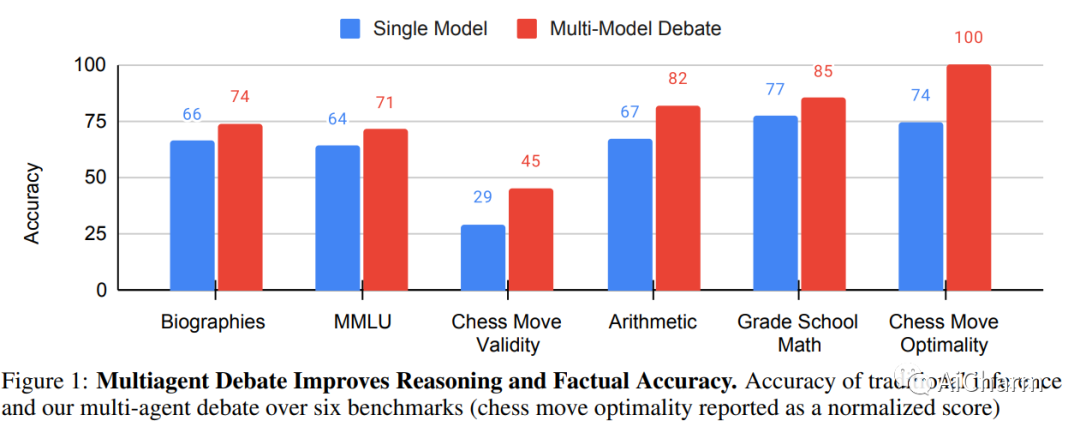
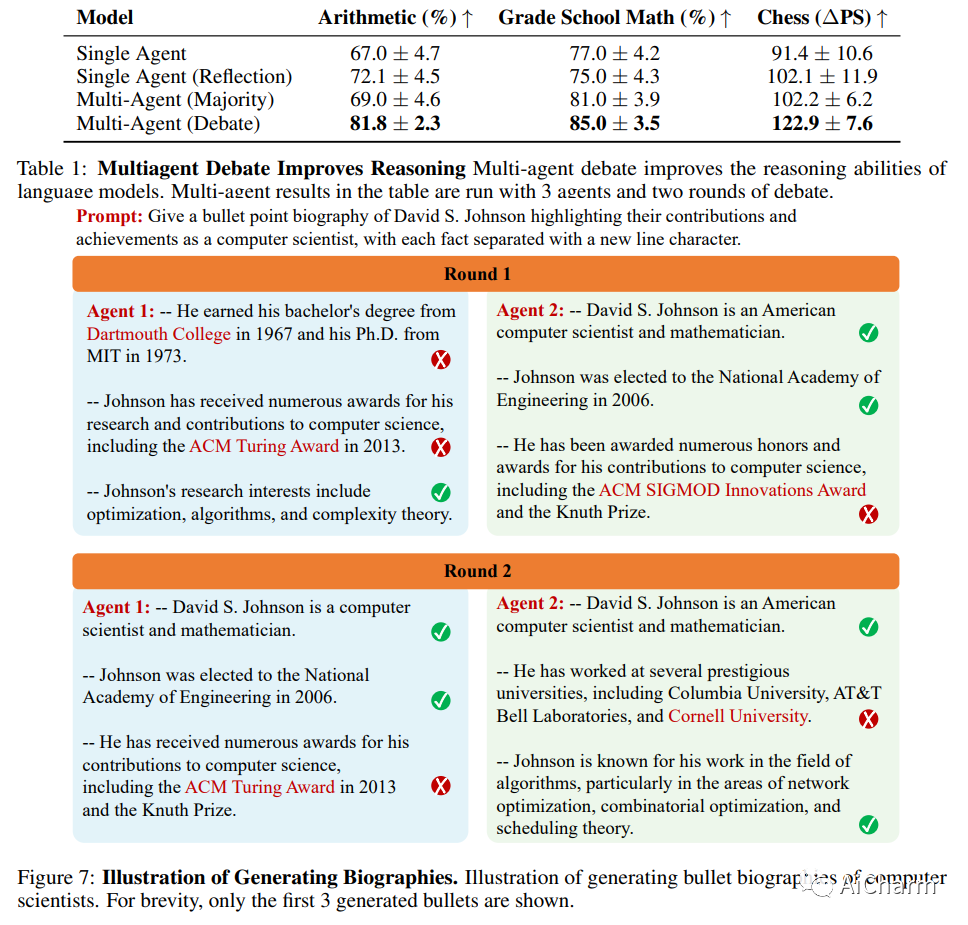
近年来,大型语言模型 (LLM) 在语言生成、理解和小样本学习方面展示了卓越的能力。大量的工作探索了如何通过提示工具进一步提高他们的表现,包括验证、自洽或中间暂存器。在本文中,我们提出了一种改进语言响应的补充方法,其中多个语言模型实例在多轮中提出并辩论其各自的响应和推理过程,以得出共同的最终答案。我们的研究结果表明,这种方法显着增强了许多任务的数学和战略推理。我们还证明,我们的方法提高了生成内容的事实有效性,减少了当代模型容易出现的错误答案和幻觉。我们的方法可以直接应用于现有的黑盒模型,并对我们调查的所有任务使用相同的程序和提示。总的来说,我们的研究结果表明,这种“思想社会”方法有可能显着提高 LLM 的能力,并为语言生成和理解的进一步突破铺平道路。
2."According to ..." Prompting Language Models Improves Quoting from Pre-Training Data

标题:“根据……”提示语言模型改进了预训练数据的引用
作者:Orion Weller, Marc Marone, Nathaniel Weir, Dawn Lawrie, Daniel Khashabi, Benjamin Van Durme
文章链接:https://arxiv.org/abs/2305.13252
摘要:
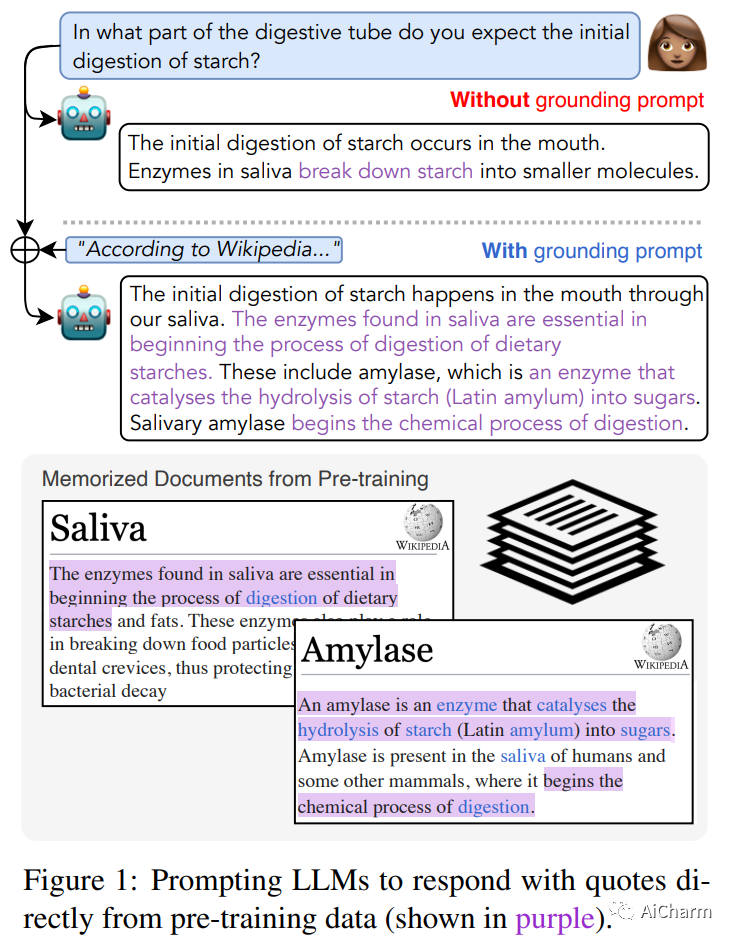
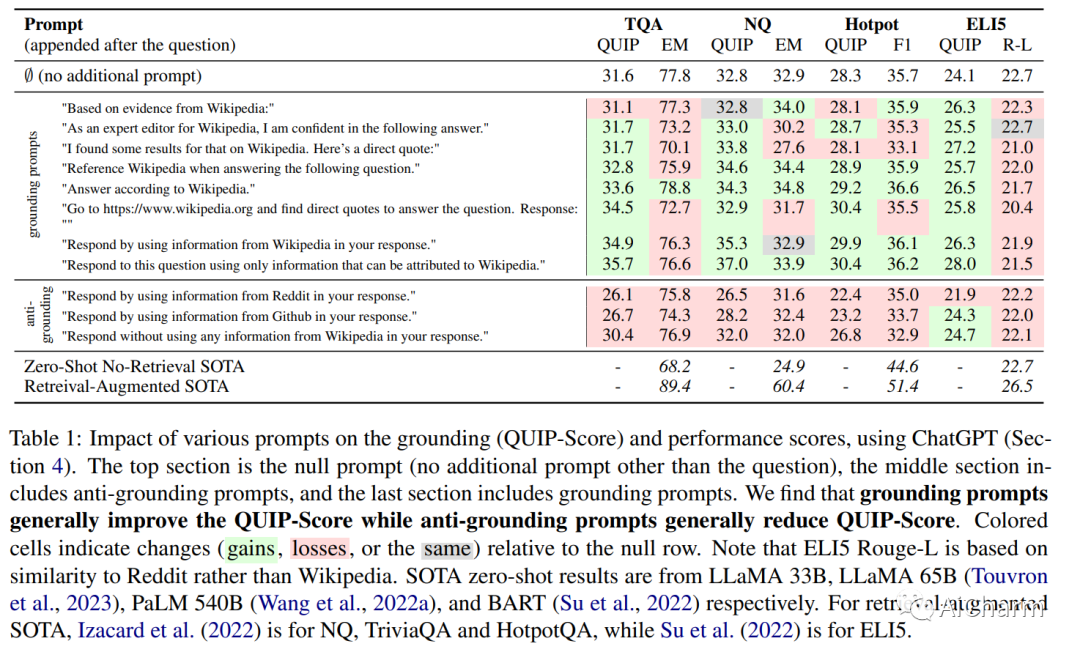
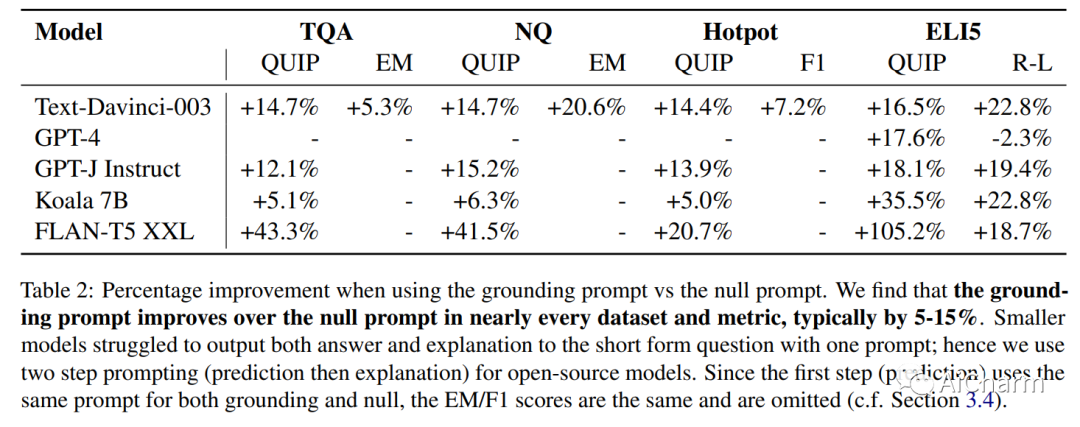
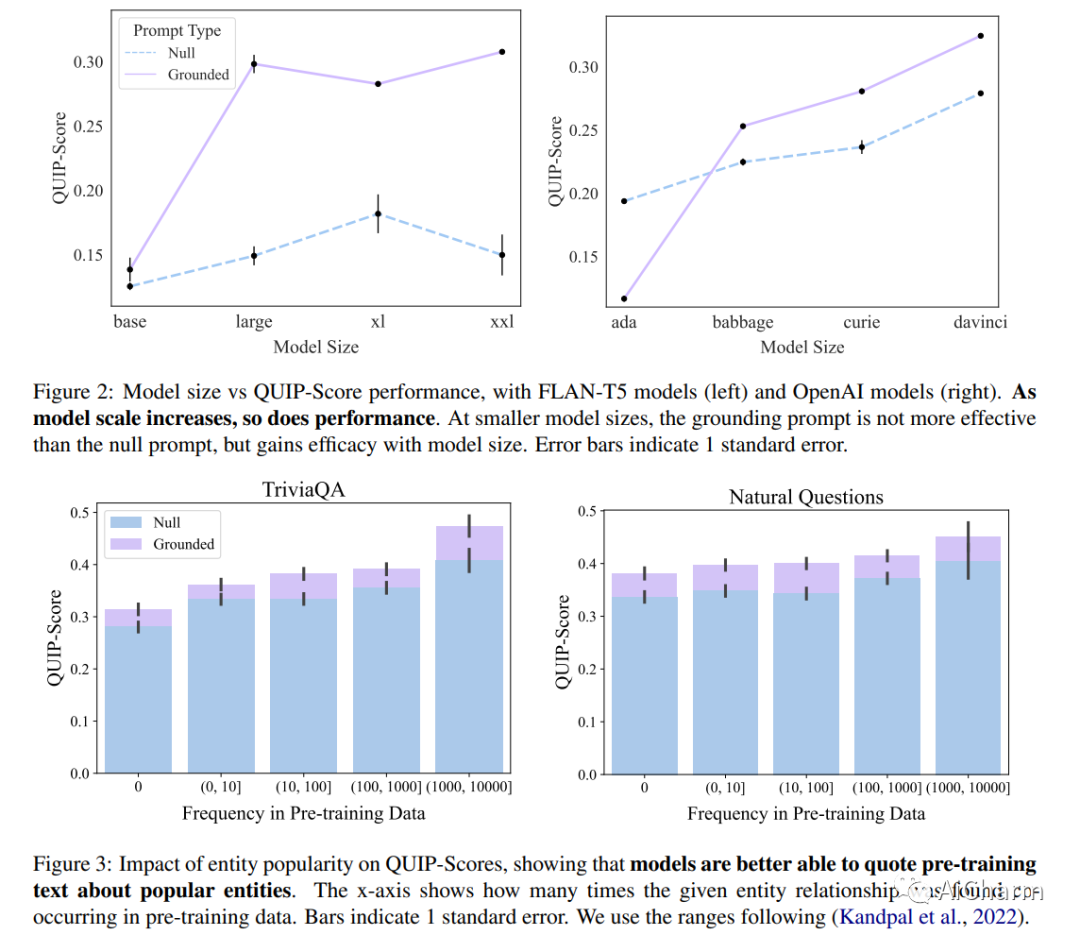
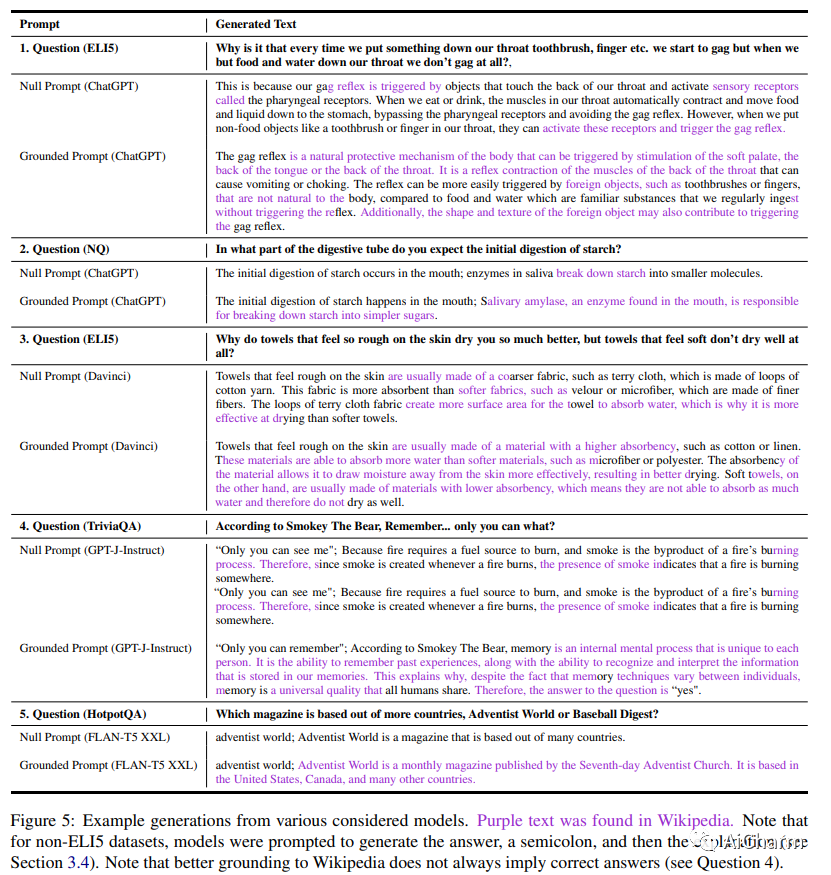
尽管对事实数据进行了预训练,但大型语言模型 (LLM) 可能会产生幻觉并生成虚假信息。受“根据消息来源”这一新闻手段的启发,我们建议根据提示:指导 LLM 对先前观察到的文本做出地面反应。为了量化这种基础,我们提出了一种新颖的评估指标(QUIP-Score),用于衡量模型生成的答案在基础文本语料库中直接找到的程度。我们通过维基百科上的实验来说明,这些提示可以改善我们指标下的基础,并具有经常提高最终任务绩效的额外好处。此外,要求模型减少接地(或接地到其他语料库)的提示会减少接地,表明语言模型能够根据要求增加或减少接地世代。
3.Aligning Large Language Models through Synthetic Feedback

标题:通过综合反馈对齐大型语言模型
作者:Sungdong Kim, Sanghwan Bae, Jamin Shin, Soyoung Kang, Donghyun Kwak, Kang Min Yoo, Minjoon Seo
文章链接:https://arxiv.org/abs/2305.13735


摘要:
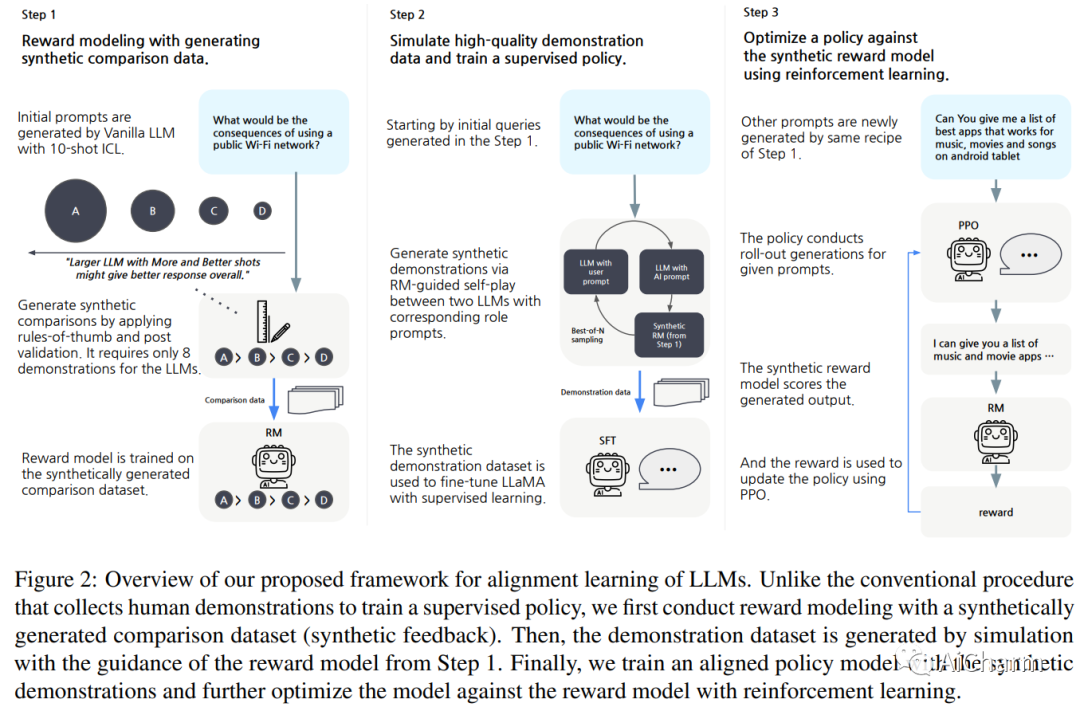
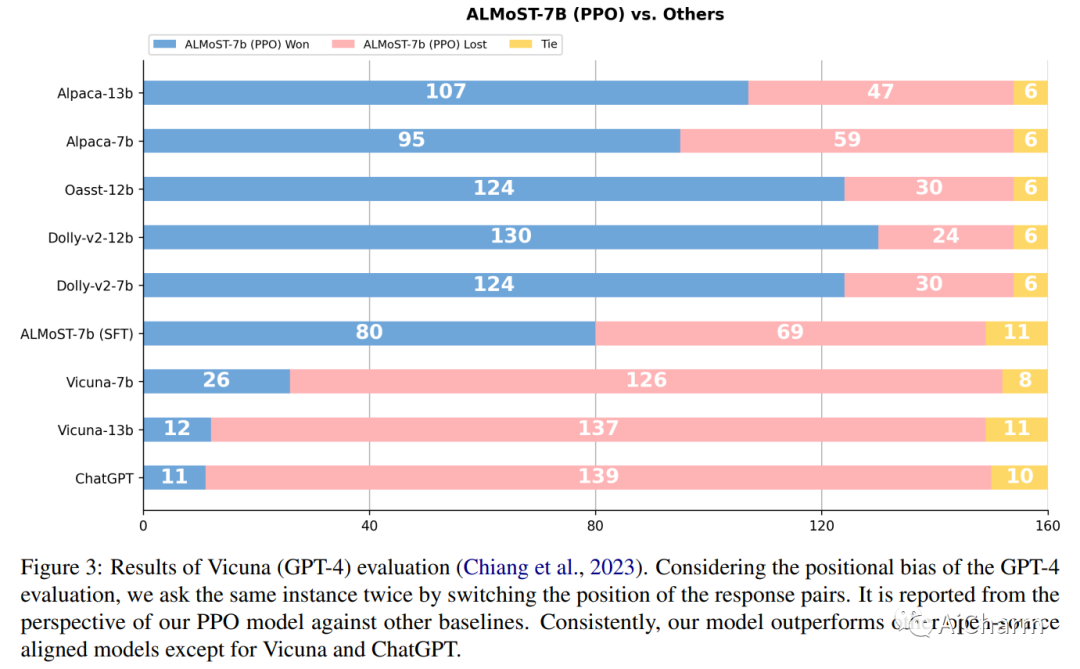
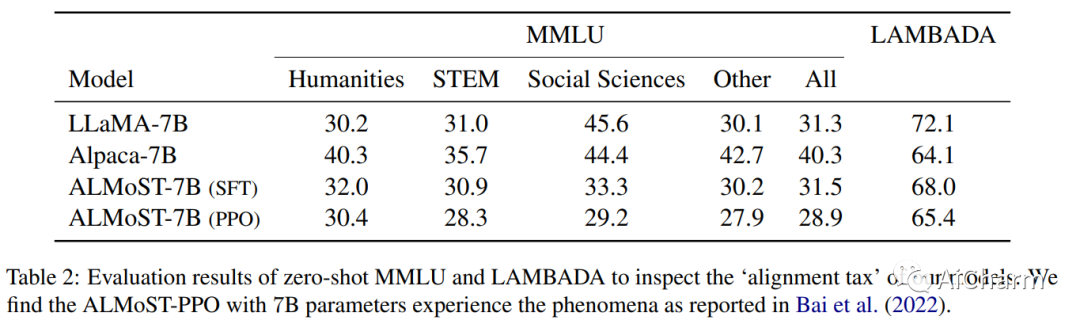
使大型语言模型 (LLM) 与人类价值观保持一致变得越来越重要,因为它可以对 LLM 进行复杂的控制,例如,使它们遵循给定的指令,同时降低它们的毒性。但是,它需要大量的人工演示和反馈。最近,开源模型试图通过从 InstructGPT 或 ChatGPT 等已经对齐的 LLM 中提取数据来复制对齐学习过程。虽然这个过程减少了人力,但构建这些数据集对教师模型有很大的依赖性。在这项工作中,我们提出了一个新的对齐学习框架,几乎不需要人工,也不依赖于预先对齐的 LLM。首先,我们通过对比来自具有各种规模和提示的原始 LLM 的响应,使用合成反馈执行奖励建模 (RM)。然后,我们使用 RM 模拟高质量演示来训练监督策略,并通过强化学习进一步优化模型。我们生成的模型,Aligned Language Model with Synthetic Training dataset (ALMoST),优于开源模型,包括 Alpaca、Dolly 和 OpenAssistant,这些模型是根据 InstructGPT 或人工注释指令的输出进行训练的。我们的 7B 尺寸模型在使用 GPT-4 作为判断的 A/B 测试中优于 12-13B 模型,平均胜率约为 75%。
更多Ai资讯:公主号AiCharm
















 2142
2142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











