




节点状态查看
- 用
sinfo可以查看现有的节点,分区:
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
cpu* up 30-00:00:0 1 comp cn042
cpu* up 30-00:00:0 45 mix cn[001-031,036-041,043-050]
gpu up 30-00:00:0 4 mix gn[001-004]
agpu up 30-00:00:0 1 mix gn101
| 关键词 | 含义 |
|---|---|
| PARTITION | 分区名,大型集群为了方便管理,会将节点划分为不同的分区设置不同权限 |
| AVAIL | 可用状态:up 可用;down 不可用 |
| TIMELIMIT | 该分区的作业最大运行时长限制, 30:00 表示30分钟,如果是2-00:00:00表示2天,如果是infinite表示不限时间 |
| NODES | 节点数量 |
| STATE | 状态:drain: 排空状态,表示该类结点不再分配到其他;idle: 空闲状态;alloc: 被分配状态;mix:部分被占用,但是仍有可用资源 |
scontrol show partition [PARTITION_NAME],查看分区的状态信息scontrol show node [NODE_NAME],查看节点的状态信息srun -p gpu --gres=gpu:volta:2 nvidia-smi,查看指定显卡的信息
追踪任务
squeue -u username来查看目前username下面所有运行的项目:
[liuhy@admin playground]$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
140 cpu test liuhy R 0:01 1 comput1
其中各列的含义如下:
PARTITION:分区是cpu还是gpu
NAME:运行的程序的name,例如 java,python,blackbird等
ST:状态,PD排队;R运行;S挂起;CG正在退出
TIME:耗时
NODES:该任务用了几个节点
NODELIST(REASON):作业未运行时,它显示未运行的原因;当作业在运行时,显示作业是在哪个节点运行的
错误的原因如下:
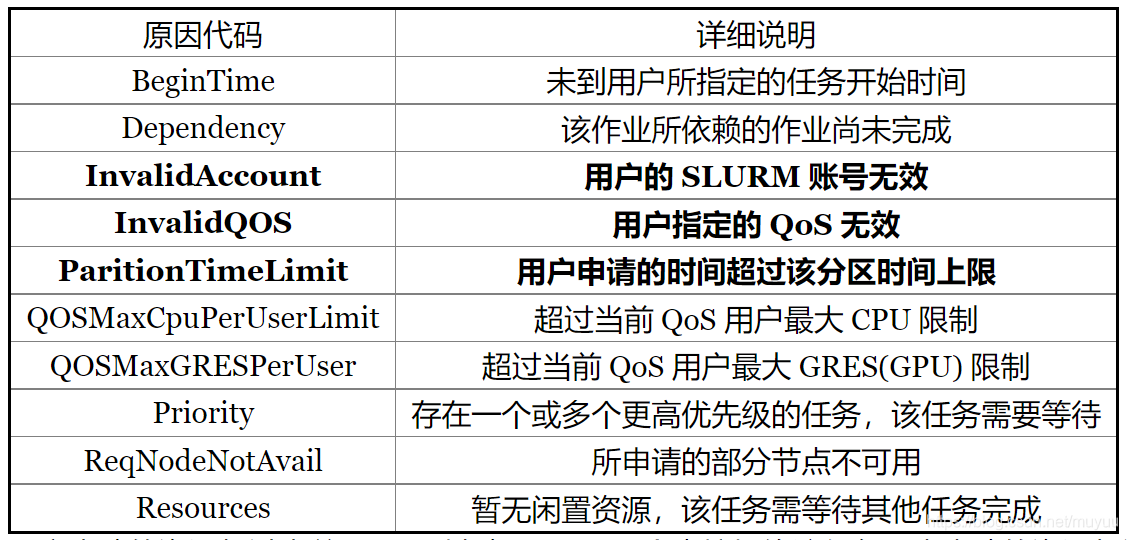
scontrol show job JOBID,其中JOBID是squeue得到的
[liuhy@admin playground]$ scontrol show job 140
JobId=140 JobName=test
UserId=liuhy(502) GroupId=users(100) MCS_label=N/A
Priority=283 Nice=0 Account=root QOS=normal
JobState=RUNNING Reason=None Dependency=(null)
Requeue=1 Restarts=0 BatchFlag=0 Reboot=0 ExitCode=0:0
RunTime=02:00:58 TimeLimit=14-00:00:00 TimeMin=N/A
SubmitTime=2021-08-18T01:12:52 EligibleTime=2021-08-18T01:12:52
AccrueTime=2021-08-18T01:12:52
StartTime=2021-08-18T01:12:55 EndTime=2021-09-01T01:12:55 Deadline=N/A
SuspendTime=None SecsPreSuspend=0 LastSchedEval=2021-08-18T01:12:55
Partition=cpu AllocNode:Sid=unn2:10030
ReqNodeList=(null) ExcNodeList=(null)
NodeList=cn004
BatchHost=cn004
NumNodes=1 NumCPUs=12 NumTasks=1 CPUs/Task=12 ReqB:S:C:T=0:0:*:*
TRES=cpu=12,mem=120G,node=1,billing=12
Socks/Node=* NtasksPerN:B:S:C=0:0:*:* CoreSpec=*
MinCPUsNode=12 MinMemoryCPU=10G MinTmpDiskNode=0
Features=(null) DelayBoot=00:00:00
OverSubscribe=OK Contiguous=0 Licenses=(null) Network=(null)
Command=java
...
会显示很多信息,其中值得注意的有NumNodes=1 NumCPUs=12 NumTasks=1 CPUs/Task=12 TRES=cpu=12,mem=120G,node=1 MinCPUsNode=12 MinMemoryCPU=10G
这些显示的是这个程序占用的资源
- 历史作业可以用
sacct来查看,默认情况下,用户仅能查看属于 自己的历史作业。直接使用 sacct 命令会输出从当天 00:00:00 起到现在的全部作业
[liuhy@admin playground]$ sacct
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
104 bash gpu root 1 COMPLETED 0:0
140 test cpu root 12 COMPLETED 0:0
141 test cpu root 12 CANCELLED+ 0:0
141.batch batch root 12 CANCELLED 0:15
141.extern extern root 12 COMPLETED 0:0
142 lllll cpu root 1 FAILED 2:0
142.extern extern root 1 COMPLETED 0:0
142.0 lllll root 1 FAILED 2:0
如果用sacct -S MMDD,则会输出从 MM 月 DD 日起的所有历史作业。默认情况会输出作业 ID,作业名,分区,账户,分配的 CPU,任务结束状态,返回码。
[liuhy@admin playground]$ sacct --format=jobid,user,alloccpu,allocgres,state%15,exitcode
JobID User AllocCPUS AllocGRES State ExitCode
------------ --------- ---------- ------------ --------------- --------
104 liuhy 1 gpu:1 COMPLETED 0:0
104.extern 1 gpu:1 COMPLETED 0:0
105 liuhy 1 COMPLETED 0:0
140.batch 12 COMPLETED 0:0
141.batch 12 CANCELLED 0:15
141.extern 12 COMPLETED 0:0
142 liuhy 1 FAILED 2:0
142.0 1 FAILED 2:0
运行任务
- 可以直接使用
srun命令,其中一些比较有用的参数有:
| 参数用法 | 意义 |
|---|---|
| -p cpu | 指定分区为CPU |
| --nodes=N | 指定使用的节点数量 |
| --nodelist=comput1 | 指定特定节点 |
| --cpus-per-task=4 | 指定 CPU 核心数量 |
| --mem-per-cpu=10G | 指定每个CPU核心的内存 |
| --gres=gpu:1 | 指定GPU卡数 |
| --ntasks=ntasks | 指定运行的任务个数 |
使用示例
- 用12个cpu核并行运行一个单任务:
srun --mem-per-cpu=10G --cpus-per-task=12 --nodes=1 --ntasks=1,总内存大小是120G - 步骤 1: 提交作业
首先,你需要有一个 SLURM 作业脚本。假设我们有一个简单的 Bash 脚本 run_my_job.sh,它在 SLURM 系统中运行一个多进程的 Python 程序:
import multiprocessing
import time
def compute_fibonacci(number):
"""计算 Fibonacci 序列的指定项"""
if number <= 1:
return number
else:
return compute_fibonacci(number-1) + compute_fibonacci(number-2)
def worker_task(process_id):
print(f"Process {process_id} started.")
start_time = time.time()
# 计算一个较大的 Fibonacci 数,你可能需要根据你的系统性能调整这个值
fib_number = compute_fibonacci(35 + process_id) # process_id 用来确保每个进程计算的值略有不同
end_time = time.time()
print(f"Process {process_id} finished. Fibonacci number: {fib_number}. Time taken: {end_time - start_time} seconds.")
def main():
# 获取系统的 CPU 核心数量
num_cores = multiprocessing.cpu_count()
print(f'Number of CPU cores: {num_cores}')
# 创建进程池
with multiprocessing.Pool(processes=num_cores) as pool:
# 创建进程ID列表
process_ids = list(range(num_cores))
# 并行运行工作任务
pool.map(worker_task, process_ids)
if __name__ == '__main__':
main()
这个脚本首先获取系统的 CPU 核心数量,然后创建一个进程池,其中每个进程执行 worker_task 函数。在这个例子中,我们计算Fibonacci(35)作为任务列表。
#!/bin/bash
#SBATCH --job-name=multi_process_python
#SBATCH --cpus-per-task=4
#SBATCH --nodes=1
#SBATCH --ntasks=1
#SBATCH --time=00:10:00
#SBATCH --output=job_output_%j.txt
srun python my_multi_process_script.py
这个 SLURM 脚本请求 1 个任务和每个任务 4 个 CPU 核心来运行一个名为 my_multi_process_script.py 的 Python 脚本。使用以下命令提交作业:
sbatch run_my_job.sh
步骤 2: 检查作业状态
提交作业后,使用 squeue 命令查看你的作业状态:
squeue -u your_username
这将显示你所有在队列中的作业的状态。找到你刚提交的作业,并记下它的作业 ID。
步骤 3: 登录到节点并检查进程
一旦你的作业开始运行,使用 scontrol show job 命令查找作业分配到的节点名:
scontrol show job <JobID>
查找输出中的 Nodes 字段,它会告诉你作业运行在哪个节点上。然后,使用 ssh 命令登录到该节点:
ssh nodename
登录后,使用 top 或 htop(如果可用)查看 CPU 的使用情况,或者直接使用 ps 命令查看你的 Python 脚本相关的进程:
ps -l -u your.name | grep python
假设 my_multi_process_script.py 正在节点上运行,使用 ps 命令可能会显示如下信息:
1 R 7051 444198 444125 9 80 0 - 57585 - ? 00:00:02 python
1 R 7051 444199 444125 9 80 0 - 57585 - ? 00:00:02 python
1 R 7051 444200 444125 9 80 0 - 57585 - ? 00:00:02 python
1 R 7051 444201 444125 9 80 0 - 57585 - ? 00:00:02 python
1 R 7051 444202 444125 9 80 0 - 57585 - ? 00:00:02 python
1 R 7051 444203 444125 9 80 0 - 57585 - ? 00:00:02 python
1 R 7051 444204 444125 9 80 0 - 57585 - ? 00:00:02 python
1 R 7051 444205 444125 9 80 0 - 57585 - ? 00:00:02 python
这里,444125 是父进程的 PID,而 444198, 444200, 444204 是由主进程创建的子进程(如果你的脚本是多进程的),R表明多进程确实在运行中。以下是其他状态:
R (running): 表示进程正在运行或在运行队列中等待。
S (sleeping): 表示进程处于休眠状态,等待某些事件或定时器。
D (disk sleep): 不可中断的休眠状态,通常在等待I/O操作。
T (stopped): 表示进程已停止执行,可能是被调试或控制。
Z (zombie): 表示进程已结束,但其父进程尚未通过调用 wait() 来读取其退出状态。
Reference:
Slurm使用参考
SLURM 系统入门使用指南
Slurm Document

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









