






系统环境:
Linux 系统:Ubuntu 22.04.4 LTS
LTS Git 版本:git version 2.34.1
Docker 版本:28.0.1
Docker Compose 版本:2.33.1
dify网址:http://IP (一般默认端口号是80)
一 dify介绍
Dify 是一款开源的大语言模型 LLM(Large Language Model)应用开发平台,它将后端即服务(Backend as a Service)与 LLMOps 两大理念有机结合,旨在帮助开发者与非技术人员快速构建、部署和管理基于大型语言模型的 AI 应用。
二 知识库素材
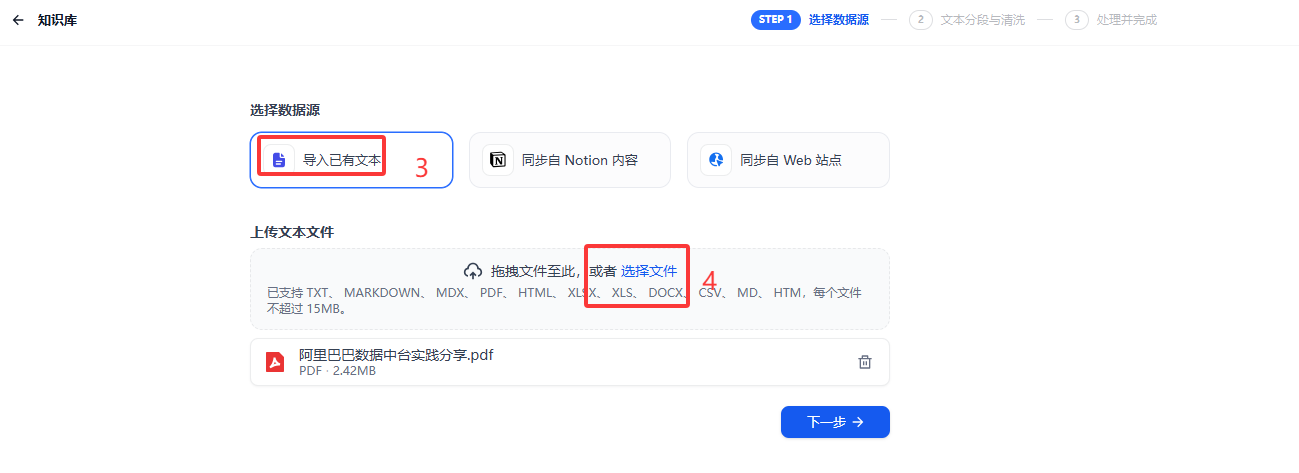
资料格式符合 Dify 要求,如TXT、 MARKDOWN、 MDX、 PDF、 HTML、 XLSX、 XLS、 DOCX、 CSV、 MD、 HTM。
三 登录dify平台,并进入知识库模块
- 使用已经注册的账号,登录本地部署的dify平台http://XX.XX.XX.XX,进入工作室,创建一个新的知识库名称:“数据中台”
2 .添加知识库文件,可以添加多个,须符合Dify 平台的格式要求。
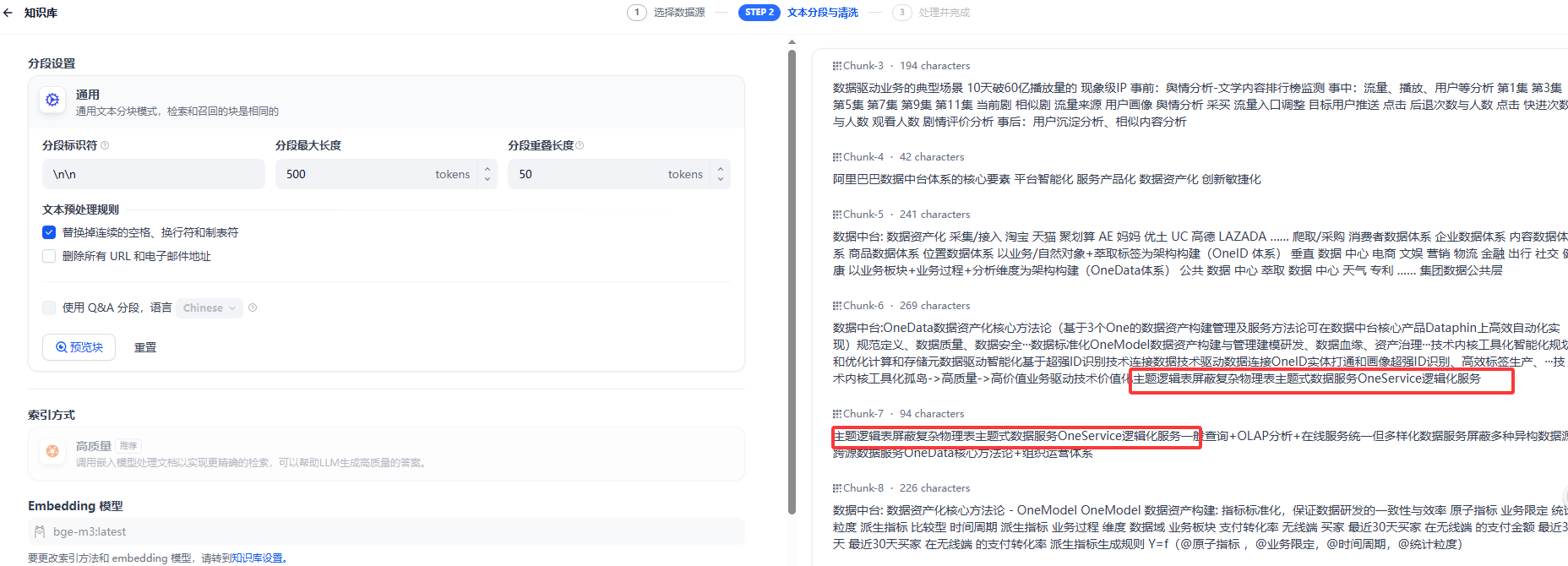
通用分段(原自动分段与清洗)
关键点:
1.默认\n作为分段标识
2.最大分段长度为4000tokens,默认为500tokens
3.分段重叠长度,默认为50tokens,用于分段时,段与段之间存在一定的重叠部分。建议设置为分段长度 Tokens 数的 10-25%;
4.文本预处理规则:用于移除冗余符号、URL等噪声 5,这里还有一个点,向量模型会自动按段落或语义进行切分,也就是大家分段以后内容缺失的根因。
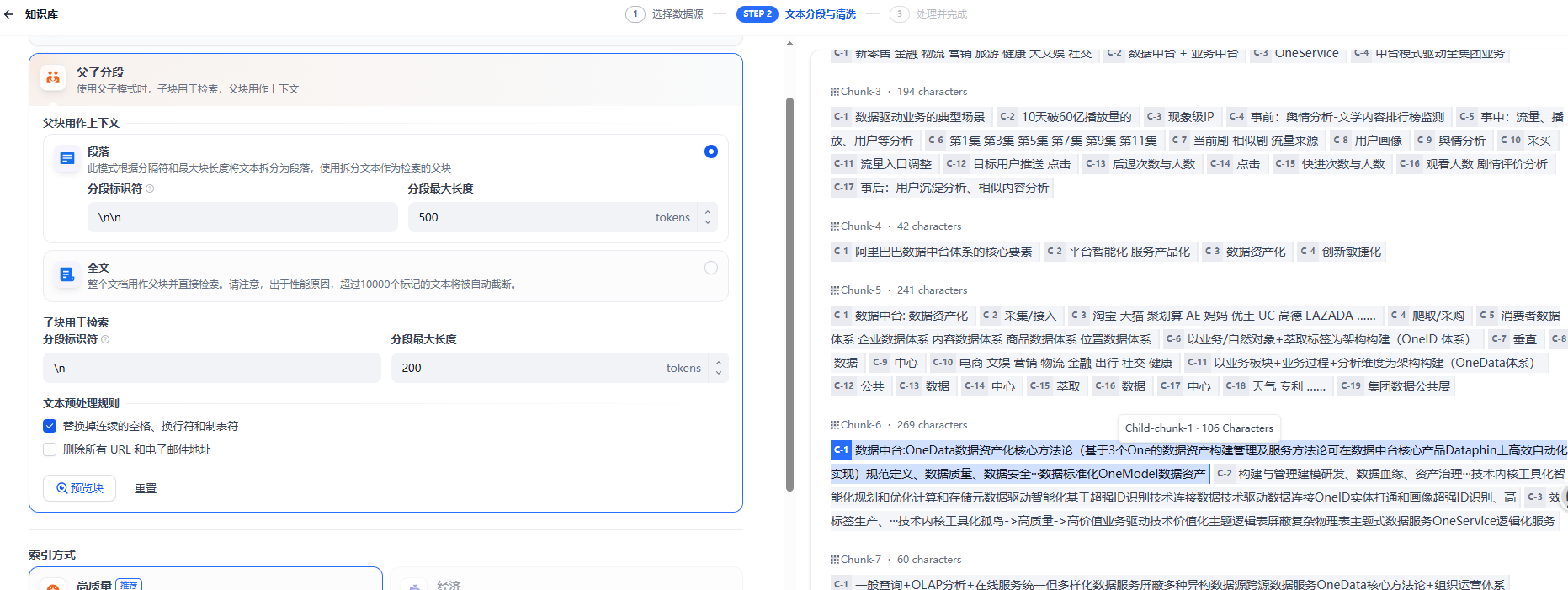
父子分段
父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。
关键点
1.父区块(Parent-chunk)保持较大的文本单位(如段落),上下文内容丰富且连贯。默认以\n\n为分段标识,如果知识不长,可以以整个作为父区块(超过1万个分段就直接被截断了)。
2.子区块(Child-chunk)以较小的文本单位(如句子),用于精确检索。默认以\n为分段标识。
3.也可以选择噪音清理
4.在搜索时通过子区块精确检索后,获取父区块来补充上下文信息,从而给LLM的上下文内容更丰富 以句子为最小单位,向量化以后向量匹配的准确度会极大的提升。
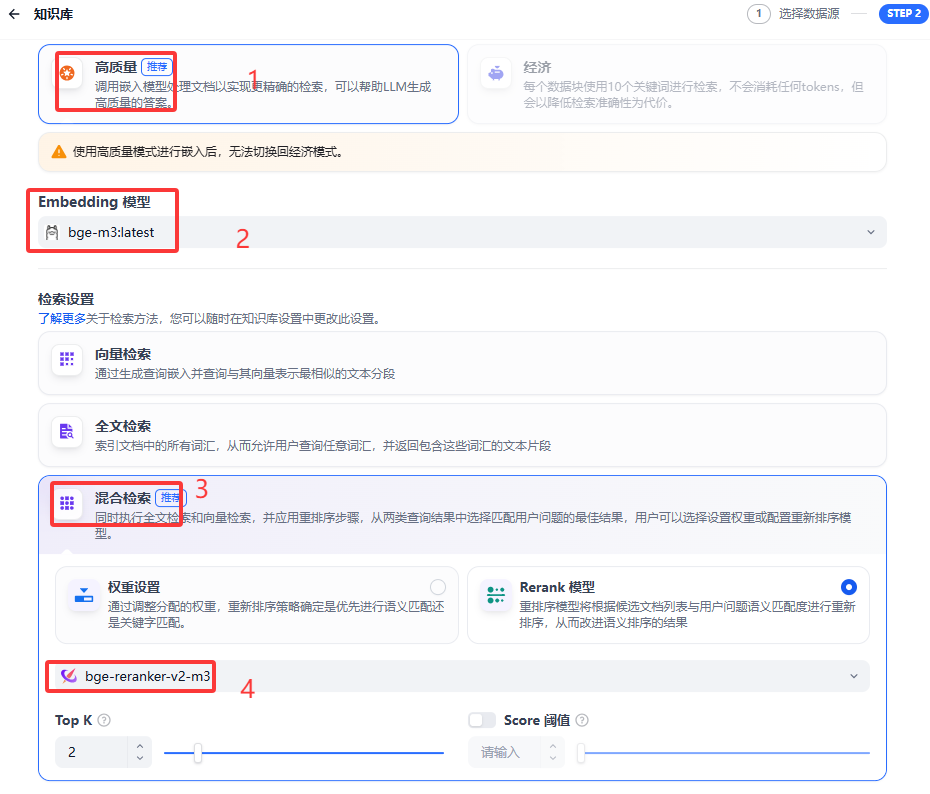
索引模式 (本例子采用高质量索引方式)
索引模式有两种。分别是高质量索引和经济索引
- 检索精度:高质量索引是依赖嵌入模型生成向量索引,结合 ReRank 模型优化排序,检索精度高;经济索引采用关键词索引或离线向量引擎等方式,准确度相对较低。
- 检索方案:高质量索引有向量检索、全文检索、混合检索三种方案;经济索引通常采用倒排索引方案,在实际应用中效果一般。
- 适用文档:高质量索引适用于格式化文档,如表格、技术手册等,通常具有较为严谨的结构和专业的内容,需要高精度的语义检索来准确获取信息。例如,技术手册中关于产品功能、操作步骤、技术规格等方面的内容;经济索引适用于非结构化文本,如会议记录。这类文档结构相对松散,内容较为随意,对检索精度的要求相对不高。
四 创建dify知识库工作流
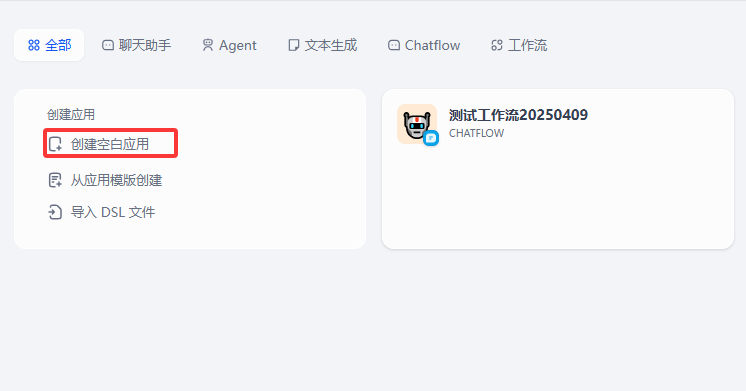
- 登录dify平台,进入“工作空间”,点击“创建空白应用”,选择应用类型——chatflow,应用名称:知识库多轮对话
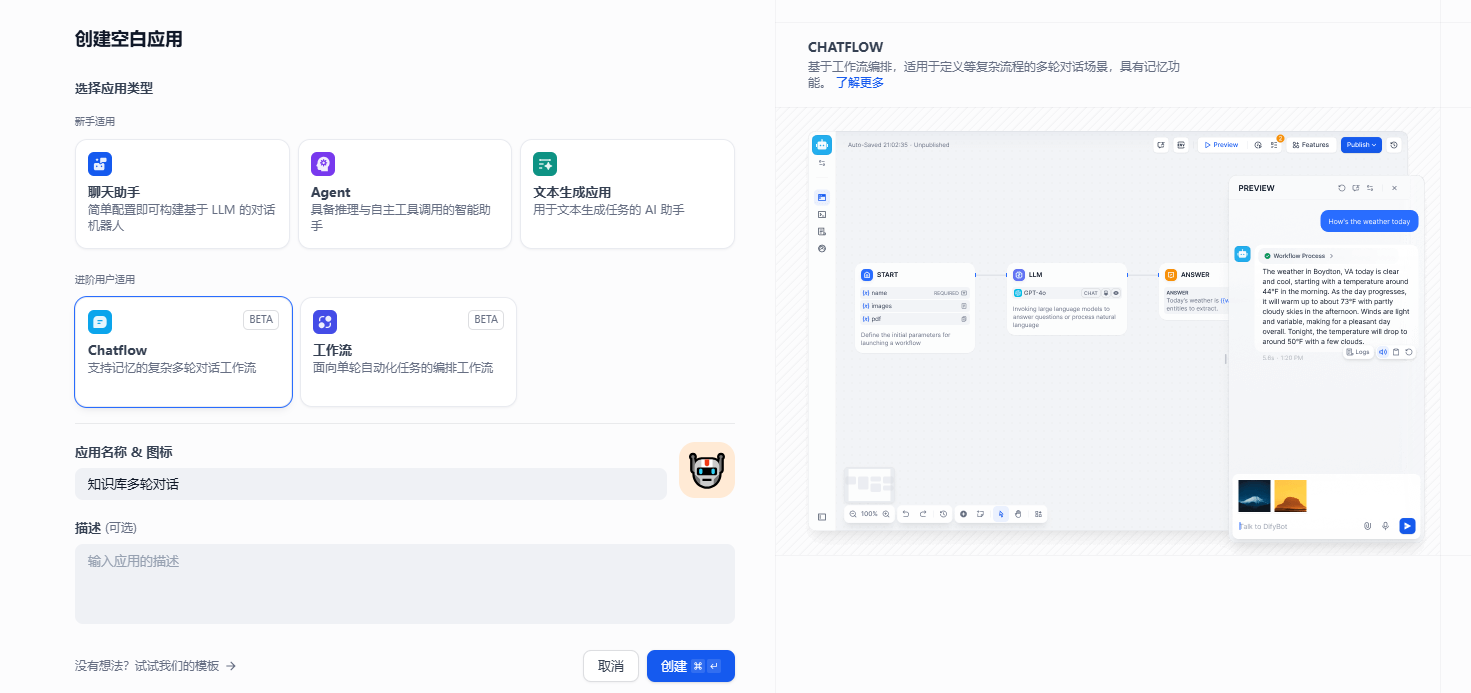
2 可以看到一个画布,dify给出了一个初始工作流编排。
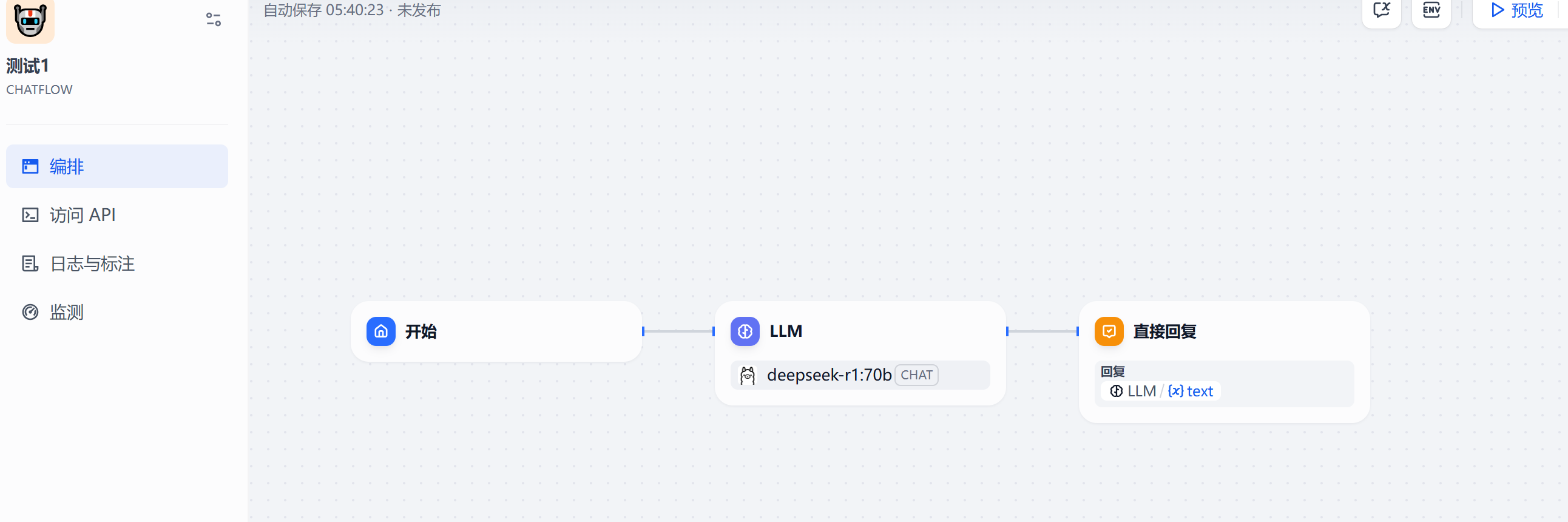
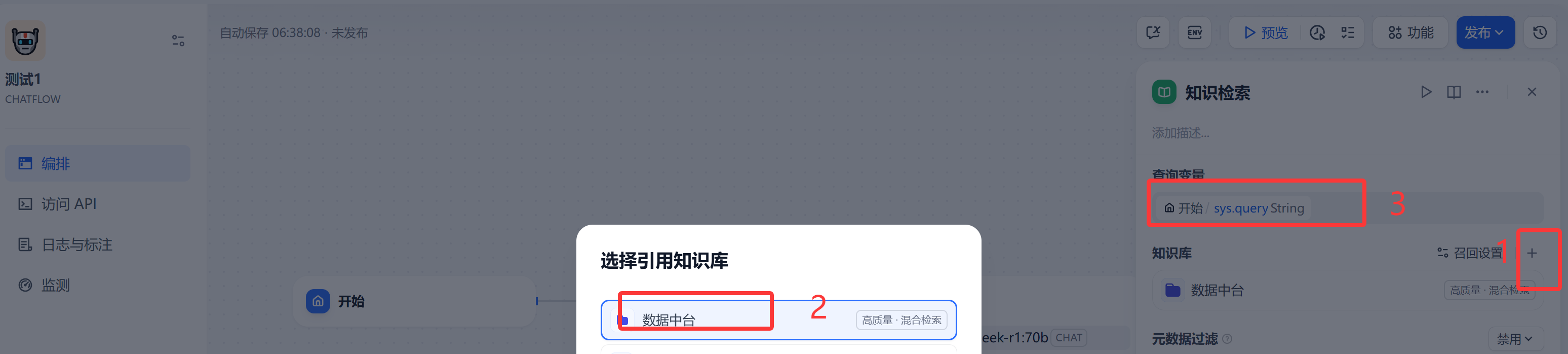
3 添加“知识检索”节点
在dify的开始节点,点击选择“知识检索”,这时"开始"节点和新增的"知识检索"就链接起来了,
右侧配置项,点击"知识库"右边的"+"号,选择创建的知识库“数据中台”。如果此时没有知识库,先去知识库那里,按照上面的步骤上传一个需要添加的知识库。
查询变量选择“sys.query”,表示从知识库里查询的什么内容。
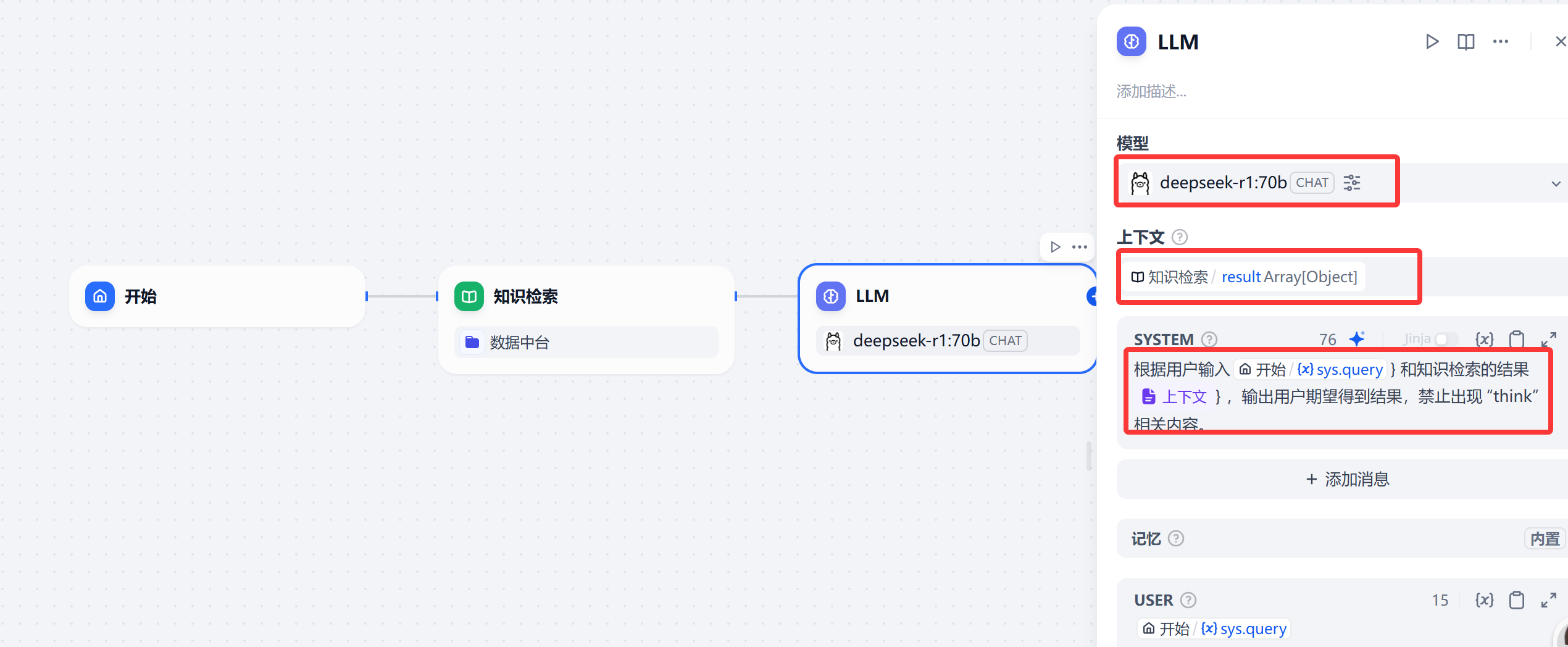
4.LLM节点配置
模型,选择正确的模型,本例子选用deepseek-r1:70b
上下文:选择知识检索。
关键的SYSTEM里面,其实就是系统提示词,填入以下内容:根据用户输入和知识检索的结果 ,输出用户期望得到结果,禁止出现 “think” 相关内容。
其中在填写系统提示词时,在"用户输入"后,需要输入{,这时系统会提示变量;"知识检索结果"后,也同样输入{,根据系统提示,选择"上下文"。这里一定要按指导操作。
5.流程完成后,“直接回复”节点配置
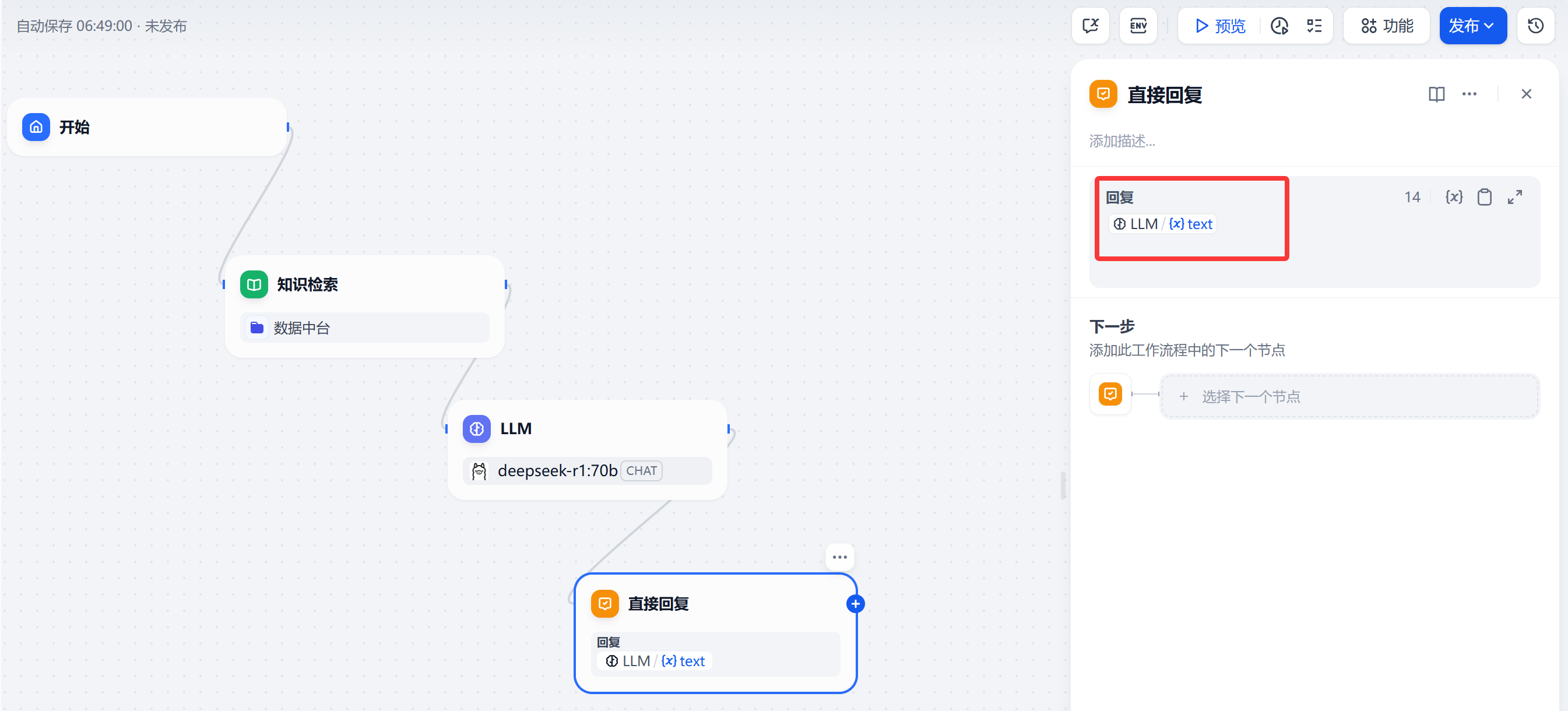
6,点击"发布",保存。提示"操作成功"。就可以在“工作室”空间看到新加的工作流了,可以在“探索”空间进行对话测试。

















 2130
2130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









