




大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径:AI代理工作流
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
- 批量使用API调用langchain-chatchat知识库能力
- langchin-chatchat部分开发笔记(持续更新)
- 文心一言、讯飞星火、GPT、通义千问等线上API调用示例
- 大模型RAG性能提升路径
- langchain的基本使用
- 结合基础模型的大模型多源信息应用开发
- COT:大模型的强化利器
- 多角色大模型问答性能提升策略(附代码)
- 大模型接入外部在线信息提升应用性能
- 从零开始的Dify大模型应用开发指南
- 基于dify开发的多模态大模型应用(附代码)
- 基于零一万物多模态大模型通过外接数据方案优化图像文字抽取系统
- 快速接入stable diffusion的文生图能力
- 多模态大模型通过外接数据方案实现电力智能巡检(设计方案)
- 大模型prompt实例:知识库信息质量校验模块
- 基于Dify的LLM-RAG多轮对话需求解决方案(附代码)
需求介绍
区别于通用LLM的多轮对话实现,RAG中多轮对话,既需要保证LLM在对话时的历史对话能力,也要保证RAG检索时输入信息的完整,同时对于模型来说,应将对话信息和RAG检索等非对话信息有清晰、明确的区分。
例如
介绍下烟台市大数据局——>他的联系方式和地址——>是否负责智慧城市建设——>介绍下技术手段
可见,上述多轮对话时的用户提问时,除首次提问要素完整外,其余提问都缺失了问题主题,甚至第四次提问时,缺失的提问主题从烟台市大数据局隐性变成了智慧城市建设。
而传统LLM RAG项目在对话和信息检索时均采用用户原始提问,导致具备多轮功能的大模型可以利用不完整提问进行连续对话,但信息检索时,不论是知识库检索还是RAG检索,都会因为提问缺少提问要素而无法获取有效信息。
例如
他的联系方式和地址作为第二次提问,对话大模型可以依靠多轮对话中的记忆模块找到历史记录,进而回答。但在知识库检索式,知识把他的联系方式和地址做了词嵌入,与向量库作匹配,根据匹配结果从知识库中检索知识,该检索过程显然丢失了最重要的烟台市大数据局这一关键信息。
解决策略
(注释)query:用户的提问
初始策略(langchain-chatchat的RAG策略)
策略过程如下:
query1——query1的检索信息——LLM结合query1、query1的检索信息进行回答
query2——query2的检索信息——LLM结合query1、query1的检索信息、query2、query2的检索信息进行回答
诸如此类,当然,记忆长度要设定为有限。
显然此策略存在且严重存在需求介绍中强调的query2的检索信息质量差,信息不全/错误/缺失的问题。
拼接历史query策略
策略过程如下:
query1——query1的检索信息——LLM结合query1、query1的检索信息进行回答
query1+query2——query1+query2的检索信息——LLM结合query1、query1的检索信息、query2、query1+query2的检索信息进行回答
同样,记忆长度要设定为有限。
该方法直接拼接一二轮问题,解决了query2中信息丢失的问题。并且在回答过程中,利用大模型的语义理解能力化解了拼接后提问生硬、不符合人类语言规律的问题。
但是此时引出了其他问题。当多轮问答中,用户需切换话题,例如query1、query2…都涉及医疗问题,问答完毕后,用户对人工智能领域进行提问,此时拼接后的query组合,除当前query涉及人工智能外,其他都是医疗相关问题。那么在进行检索信息时,检索出的信息必然侧重医疗,而人工智能的回答较少。虽然在进行用户回答时,LLM会根据语义和历史对话进行整理,但回答质量经实验证明较差。甚至于AI检索在面对语义完全不同的query拼接组合时,会出现检索不到内容的现象。
设计多轮信息处理模块
具体设计:
1.模块判断当前query语义与历史query语义相似度。
2.语义相去较远时,输出当前query。输出格式通过few-shot和后处理agent实现。
3.语义相近时,补充query所需的要素,优化提问。输出格式通过few-shot和后处理agent实现。
4.避免历史query语义词频占比重,设计缓存query,仅缓存优化后具备完整提问要素的query;此外,每次优化对当前语句仅采用最近1次的缓存query。
5.完全隔离问答LLM和功能性LLM。负责用户问答的LLM接口采用多轮模式,优化query、提问范围审查等功能性LLM采用单论,从根上阻隔信息串扰。
具体的设计如图所示:
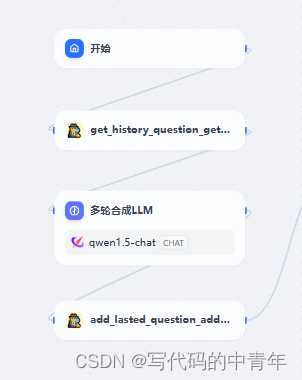
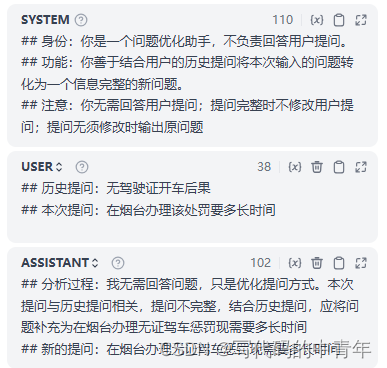
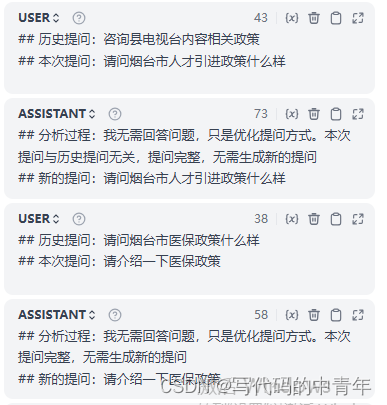
其中获取历史缓存query和存储优化后query的agent工具代码如下:
from fastapi import FastAPI, HTTPException, Depends
from typing import List, Optional
import re
import json
import datetime
import pandas as pd
app = FastAPI()
@app.get("/get_history_question_len3")
def get_history_question():
result = []
with open('/home/gputest/lyq/py_file/cache.txt','r') as f:
result = [i.strip('\n') for i in f.readlines()]
if len(result) <= 1000:
pass
else:
new_result = result[500:]
with open('/home/gputest/lyq/py_file/cache.txt','w') as f:
for i in new_result:
f.write(i)
f.write['\n']
print('cache num :',len(result))
return ';'.join(result[-3:])
@app.get("/get_history_question")
def get_history_question():
result = []
with open('/home/gputest/lyq/py_file/cache.txt','r') as f:
result = [i.strip('\n') for i in f.readlines()]
if len(result) <= 1000:
pass
else:
new_result = result[500:]
with open('/home/gputest/lyq/py_file/cache.txt','w') as f:
for i in new_result:
f.write(i)
f.write['\n']
print('cache num :',len(result))
return ';'.join(result[-1:])
@app.get("/add_lasted_question")
def add_lasted_question(input_str):
mid_str = input_str.split('新的提问:')[-1]
with open('/home/gputest/lyq/py_file/cache.txt','a') as f:
f.write(mid_str)
f.write('\n')
print(mid_str,'History Data Add Finished.')
return mid_str
@app.get("/extract_info")
def extract_info(input_str):
mid_str = input_str.split('新的提问:')[-1]
print(mid_str,'Data Extracted.')
return mid_str
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="172.19.138.52", port=3017)



















&spm=1001.2101.3001.5002&articleId=139118192&d=1&t=3&u=30c2b81e2b8a44b799d0ac5daba2fb88)
 1301
1301

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











