






 文章介绍了如何利用YOLOv5进行行人检测,再结合MediaPipe进行姿态识别,以实现越界行为的检测。通过选取检测区域,运用射线法判断目标是否在区域内,然后使用MediaPipe提取人体关键点,设置三重判定条件来判断是否探出或翻越围栏。这种方法适用于多人姿态检测,能有效识别围栏探出行为。
文章介绍了如何利用YOLOv5进行行人检测,再结合MediaPipe进行姿态识别,以实现越界行为的检测。通过选取检测区域,运用射线法判断目标是否在区域内,然后使用MediaPipe提取人体关键点,设置三重判定条件来判断是否探出或翻越围栏。这种方法适用于多人姿态检测,能有效识别围栏探出行为。
结合YOLOv5和MediaPipe实现越界识别(方法介绍)
目录
前言
针对某些人员围栏探出检测任务中,在使用预训练YOLOv5模型对检测区域的行人进行检测基础上,使用MediaPipe姿态检测模块提取人体的关键点,基于人体的关键点检测设定三重判定条件进一步判断行人是否有探出围栏的行为。
该方法基于预训练模型YOLOv5和机器学习应用开发框架MediaPipe,能在一定程度上同时实现多人围栏探出的检测。
检测区域选取方法
在进行各类检测任务时,画面内可能存在近景和远景两处目标,由于视角的远近不同,检测效果也参差不齐,近景检测效果明显好于远景,并且对于越界识别一类任务,通过对检测区域的设定可以将在区域内的对象变相的看成越界对象,便于项目的实现与操作。

(1)保存视频帧
在这,我们以视频的第一帧作为后续操作的背景,简单的调用opencv的内置函数。
import cv2
vc = cv2.VideoCapture(r"D:1.MOV")
success, frame = vc.read() # 读第一帧
ord = 0
path = "****"
if success:
cv2.imwrite(path, frame)
else:
print('读取失败')
vc.release()
(2)选取检测区域
检测区域的选取通过调用保存的视频帧,
结合 OpenCV 内置函数 cv2.polylines、cv2.fillPoly 获取多边形区域
调用 OpenCV 内置函数 cv2.namedWindow 将图像窗口与鼠标回调函数绑定,完成 ROI 区域的选择,之后保存区域坐标为 pkl 文件,方便调度使用。
部分代码展示如下:
# 创建图像坐标参数
sp = [] # 用于存放点坐标
def draw_roi(event, x, y, flags, param):
img2 = img.copy()
if event == cv2.EVENT_LBUTTONDOWN: # 左键点击,选择点
sp.append((x, y))
if event == cv2.EVENT_RBUTTONDOWN: # 右键点击,取消最近一次选择的点
sp.pop()
if event == cv2.EVENT_MBUTTONDOWN: # 中键绘制轮廓
mask = np.zeros(img.shape, np.uint8)
points = np.array(sp, np.int32)
points = points.reshape((-1, 1, 2))
# 选择多边形
mask = cv2.polylines(mask, [points], True, (255, 255, 255), 2)
mask2 = cv2.fillPoly(mask.copy(), [points], (255, 255, 255)) # 用于求 frame_ROI
mask3 = cv2.fillPoly(mask.copy(), [points], (0, 255, 0)) # 用于 显示在桌面的图像
show_image = cv2.addWeighted(src1=img, alpha=0.8, src2=mask3, beta=0.2, gamma=0)
cv2.imshow("mask", mask2)
cv2.imshow("show_img", show_image)
ROI = cv2.bitwise_and(mask2, img)
cv2.waitKey(0)
if len(sp) > 0:
# 将pts中的最后一点画出来
cv2.circle(img2, sp[-1], 3, (0, 0, 255), -1)
if len(sp) > 1:
# 画线
for i in range(len(sp) - 1):
cv2.circle(img2, sp[i], 5, (0, 0, 255), -1) # x ,y 为鼠标点击地方的坐标
cv2.line(img=img2, pt1=sp[i], pt2=sp[i + 1], color=(255, 0, 0), thickness=2)
cv2.imshow('image', img2)
#将图像窗口与鼠标回调函数绑定
cv2.namedWindow(‘image’, cv2.WINDOW_NORMAL)
最后将点坐标保存到PKL文件中,方便后续调用!!!

目标点落入检测区域的自动判定
检测区域选择后,可以采用射线法将判断目标是否在检测区域问题转变为判
断一个点是否在多边形内的问题
(1)射线法介绍
射线法就是以判断点(检测目标的坐标)开始,向右(或向左)的水平方向作射线,计算此
射线与区域边界的相交次数。如果为奇数,认为点(检测目标的坐标)在多边形内;为偶数,则点在多边形外。
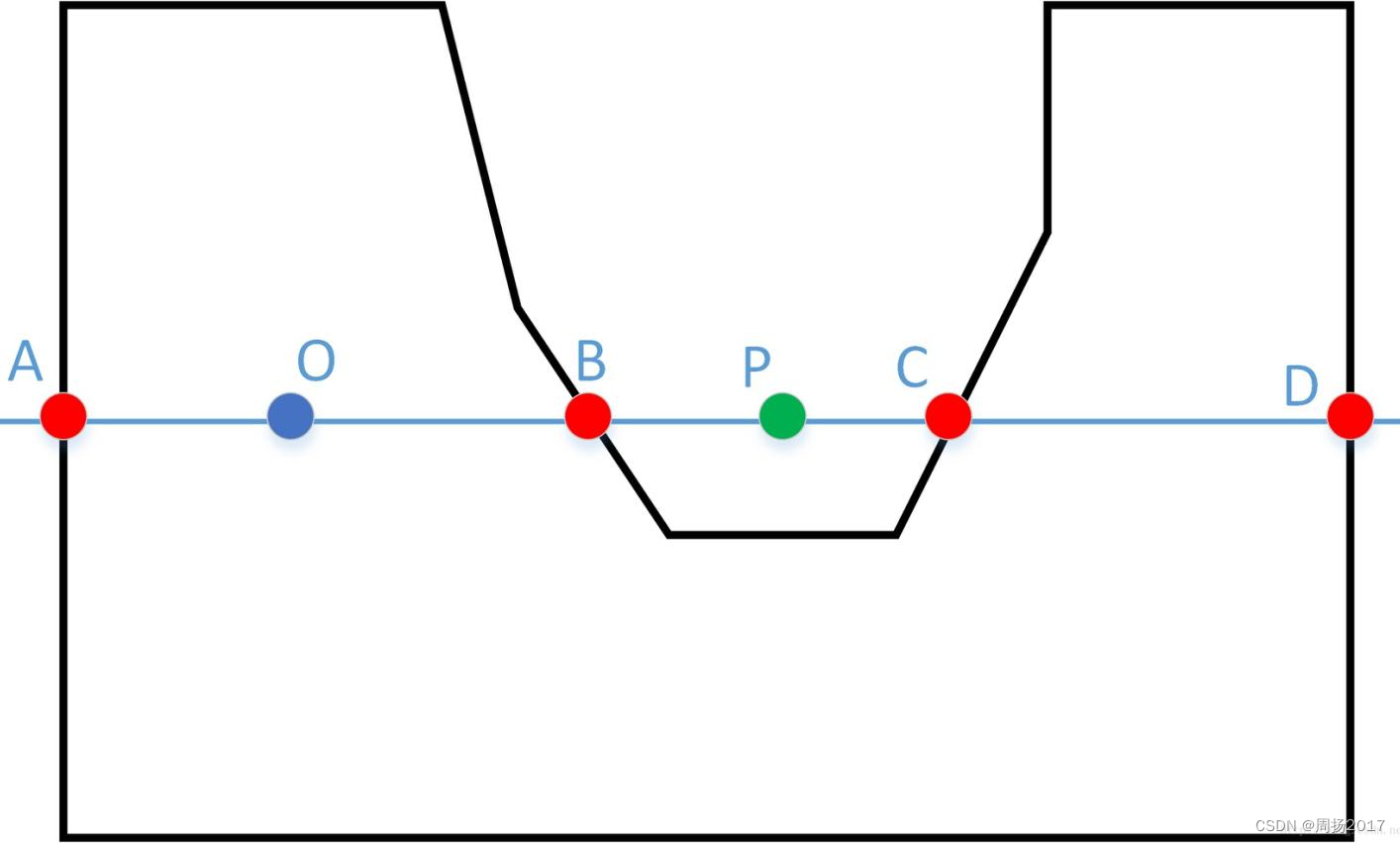
要实现上述效果,还需要做线段与射线重叠或者射线经过线段下端点属于不相交的规范和排除。

排除上述情况后,利用两个三角形的比例关系求出交点在起点的左边还是右边。
(1)目标点落入检测区域的判定实现
当判定检测目标的坐标在检测区域内;则对此目标进行外接矩形框的绘制和进一步实现对应的检测方法;否则忽略该检测目标;
### 线段和射线的特殊关系判断
def isRayIntersectsSegment(poi, s_poi, e_poi): # [x,y] [lng,lat]
# 输入:判断点,边起点,边终点,都是[lng,lat]格式数组
if s_poi[1] == e_poi[1]: # 排除与射线平行、重合,线段首尾端点重合的情况
return False
if s_poi[1] > poi[1] and e_poi[1] > poi[1]: # 线段在射线上边
return False
if s_poi[1] < poi[1] and e_poi[1] < poi[1]: # 线段在射线下边
return False
if s_poi[1] == poi[1] and e_poi[1] > poi[1]: # 交点为下端点,对应spoint
return False
if e_poi[1] == poi[1] and s_poi[1] > poi[1]: # 交点为下端点,对应epoint
return False
if s_poi[0] < poi[0] and e_poi[1] < poi[1]: # 线段在射线左边
return False
xseg = e_poi[0] - (e_poi[0] - s_poi[0]) * (e_poi[1] - poi[1]) / (e_poi[1] - s_poi[1]) # 求交
if xseg < poi[0]: # 交点在射线起点的左侧
return False
return True # 排除上述情况之后
### 射线法判断点是否在区域内
def isPoiWithinPoly(poi, poly):
global entrance,count
sinsc = 0 # 交点个数
for epoly in poly: # 循环每条边的曲线->each polygon 是二维数组[[x1,y1],…[xn,yn]]
for i in range(len(epoly) - 1): # [0,len-1]
s_poi = epoly[i]
e_poi = epoly[i + 1]
if isRayIntersectsSegment(poi, s_poi, e_poi):
sinsc += 1 # 有交点就加1
if sinsc % 2 == 1:
print("****")
return True
上述做为后续yolov5模型的调用函数
人员探出、翻越围栏检测方法
(1)MediaPipe姿态识别
1.1.MediaPipe的安装
这部分很简单,直接在windows命令行的环境下
pip install mediepipe
就OK了。
1.1.MediaPipe的介绍
Mediapipe是google的一个开源项目,可以提供开源的、跨平台的常用机器学习(machine learning)方案。Mediapipe实际上是一个集成的机器学习视觉算法的工具库,包含了人脸检测、人脸关键点、手势识别、头像分割和姿态识别等各种模型。
目前,它提供了16个Solutions,如下所示:
人脸检测
Face Mesh
虹膜
手
姿态
人体
人物分割
头发分割
目标检测
Box Tracking
Instant Motion Tracking
3D目标检测
特征匹配
AutoFlip
MediaSequence
YouTube-8M
目前,我们使用它提供的姿态模型做进一步开发。
(2)结合YOLOv5和MediaPipe实现越界识别
2.1.yolov5整合MediaPipe实现姿态点识别
项目将围栏内侧区域选定为检测区域,目标点定义为人体的腹部关键点。则根据围栏探出的定义:腹部以上超出围栏内侧区域视为围栏探出
将该事件抽象成目标点落入检测区域的判定问题。
首先,选取围栏内区域为检测区域,且围栏边缘作为检测区域的边缘,基于选定的检测区域,首先使用目标检测模型 YOLOV5 执行行人检测,得到检测框,并判定检测框角点是否有落入检测域;一旦检测框落入检测区域,则接着调用MediaPipe 姿态检测模块提取人体的关键点。

将mediapipe源码添加在YOLOv5源项目的detect.py中,以达到预期效果
"""代码如下"""
在yolov5源码detect.py中的if save_img or save_crop or view_img:后添加坐标变量和mediapipe
角点坐标作为 YOLOV5 执行行人检测后行人坐标。
### 获取关键点并进行判断,此处调用了上述射线法
x1 = int(xyxy[0].item())
y1 = int(xyxy[1].item())
x2 = int(xyxy[2].item())
y2 = int(xyxy[3].item())
zs = [x1, y1] # 左上点
ys = [x2, y1] # 右上点
zx = [x1, y2] # 左下点
yx = [x2, y2] # 右下点
# w1 为检测框的宽,h1为检测框的高
w1 = x1 - x2
h1 = y1 - y2
print("box:", zs, ys, zx, yx)
if ROI.input: # 调用ROI文件进行ROI区域点坐标的调用和区域判断(判断四个角任意一点)
if ROI_1.isPoiWithinPoly(zs, ROI.model) or ROI_1.isPoiWithinPoly(ys, ROI.model) or \
ROI_1.isPoiWithinPoly(zx, ROI.model) or ROI_1.isPoiWithinPoly(yx, ROI.model):
print("有人靠近")
# print('bounding box is', x1, y1, x2, y2) # 打印坐标(打印的是人的左上和右下两个点)
'''imgROI为裁剪送于mediapipe检测的单人图片(把检测到的人裁剪送出检测)'''
imROI = im0[y1:y2, x1:x2] # 单人矩形框
cv2.imshow("单人",imROI)
if cv2.waitKey(0) & 0xFF == ord('q'):
break
stage = None
mp_drawing = mp.solutions.drawing_utils
mp_pose = mp.solutions.pose
with mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5) as pose:
image = cv2.cvtColor(imROI, cv2.COLOR_BGR2RGB)
# 这里设置为不可写
image.flags.writeable = False
# 检测
results = pose.process(image)
# 这里设置为可写,颜色也转换回去
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
# 提取关键点
try:
landmarks = results.pose_landmarks.landmark
# 获取相应关键点的坐标
lshoulder = [landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value].x,
landmarks[mp_pose.PoseLandmark.LEFT_SHOULDER.value].y]
lhip = [landmarks[mp_pose.PoseLandmark.LEFT_HIP.value].x,
landmarks[mp_pose.PoseLandmark.LEFT_HIP.value].y]
lknee = [landmarks[mp_pose.PoseLandmark.LEFT_KNEE.value].x,
landmarks[mp_pose.PoseLandmark.LEFT_KNEE.value].y]
rshoulder = [landmarks[mp_pose.PoseLandmark.RIGHT_SHOULDER.value].x,
landmarks[mp_pose.PoseLandmark.RIGHT_SHOULDER.value].y]
rhip = [landmarks[mp_pose.PoseLandmark.RIGHT_HIP.value].x,
landmarks[mp_pose.PoseLandmark.RIGHT_HIP.value].y]
rknee = [landmarks[mp_pose.PoseLandmark.RIGHT_KNEE.value].x,
landmarks[mp_pose.PoseLandmark.RIGHT_KNEE.value].y]

2.2.三重判定条件
Mediapipe 姿态识别模块检测到人体的 33 个关键点。根据具体要求,只需要选取我们需要的点进行操作即可,为了防止人员侧身导致姿态点无法准确识别,所以我们主要选取了 12:左肩、24:左臀、26:左膝盖、11:右肩、23:右臀、25:右膝盖,共计 6 个关键点作为人员探出和翻越围栏检测的基础,具体包含以下三个判定条件:
(1) 保证左右侧身两种情况下都能检测到想要的关键点,之后分别连线 12、 23;11、24 两组点,选取连线的下三分之一处的 1 号点和2 号点设定为腹部所 在位置,腹部关键点落入检测区域;
(2) 为避免两组关键点重合、丢失、模糊等情况导致精度受损。在对 1、2 点做射线法的基础上,又计算 12、24、26 三点连线的夹角 a和 11、23、25 三点 连接的夹角 b,设定 a 和 b 的角度在[0,145]°作为第二重判断,保证了姿态检 测的识别精度;
(3)利用人体检测框的长宽比做第三重判断,避免姿态点未识别、丢失、缺损、重合、杂乱、模糊等情况的发生时检测算法的实效,本项目设定以人体检测
框的高度/宽度<0.5 为判定依据。

如果人体姿态检测的结果同时满足上述 3 个条件,则判定为人员探出或翻越围栏,进行告警。
关键代码如下:
1.首先要设定两个方法calculate_angle、mid_point分别用来计算关节角度和关键点的中间点。
2.根据角度和点坐标作进一步判断
关键判断如下:
# 这块是具体的业务逻辑,各个数值,可根据自己实际情况适当调整
if ROI.input: # 调用ROI0文件进行ROI区域点坐标的调用和区域判断(判断四个角任意一点)
if (ROI_1.isPoiWithinPoly(mid1, ROI.model) or \
ROI_1.isPoiWithinPoly(mid2, ROI.model)) or (
(rhangle > 0 and lhangle > 0) and (rhangle < 145 and lhangle < 145)) \
and (w1 / h1 >= 0.5):
'''以下两种响应随机选一种,若选择print,则注释stage和271行的cv2.putText()'''
## 若有人翻越围栏则打印
print("有人探出围栏")
## 若有人翻越围栏则在裁剪框里展示SSS
stage = 'SSS'
else:
print("一切正常")
# stage = 'normal'
2.3.单人/多人姿态检测具体实现
姿态检测问题涉及单人姿态检测和多人姿态检测,对于围栏探出、翻越的应用场景,需要考虑在多人的情况下对每一个人做姿态的识别,本项目使用MediaPipe 和 YOLOv5 相结合的方式,MediaPipe 主要进行单人姿态识别,配合YOLOv5 可以基本实现多人姿态检测,进而可实现多人探出、翻越围栏的检测。
关键在于:
在检测区域内检测到行人后,截取其检测框,并将其传递给 MediaPipe 进行人体关键点识别。
YOLOv5 可以同时识别多个人进行裁剪,Mediapipe 只需对传递的每一个检测框进行单人姿态识别,之后重新映射回原图,以此实现多人的姿态识别。
效果展示



结语
本文主要为大家提供一个简便的在yolov5中整合mediapipe的方法以实现姿态检测的方法,便于实现更多功能,完整代码未完全展示。


















 1531
1531

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











