







 文章提出了一种名为FSTRN的快速时空残差网络,用于视频超分辨率任务。FSTRN通过快速时空残差块(FRB)降低3D卷积的计算复杂性,同时利用LR和HR空间的全局残差学习(GRL)提高性能。FRB将3D滤波器分解为低维滤波器的乘积,以保持网络深度和效率。实验结果表明,FSTRN在保持时间一致性的同时,显著优于现有的视频超分辨率方法。
文章提出了一种名为FSTRN的快速时空残差网络,用于视频超分辨率任务。FSTRN通过快速时空残差块(FRB)降低3D卷积的计算复杂性,同时利用LR和HR空间的全局残差学习(GRL)提高性能。FRB将3D滤波器分解为低维滤波器的乘积,以保持网络深度和效率。实验结果表明,FSTRN在保持时间一致性的同时,显著优于现有的视频超分辨率方法。
最近,基于深度学习的视频超分辨率(SR)方法取得了令人满意的性能。为了同时利用视频的空间和时间信息,采用三维(3D)卷积是一种自然的方法。然而,直接利用3D卷积可能导致过高的计算复杂性,这限制了视频SR模型的深度,从而破坏了性能。在本文中,我们提出了一种新的快速时空残差网络(FSTRN),以对视频SR任务采用3D卷积,从而在保持低计算负载的同时提高性能。具体而言,我们提出了一种快速时空残差块(FRB),将每个3D滤波器划分为两个3D滤波器的乘积,这两个滤波器具有相当低的维数。此外,我们设计了一种直接链接低分辨率空间和高分辨率空间的跨空间残差学习,这可以大大减轻特征融合和放大部分的计算负担。对基准数据集的广泛评估和比较验证了所提出方法的优势,并证明所提出的网络显著优于当前最先进的方法。
1. Introduction
超分辨率(SR)解决了从其低分辨率(LR)对应物估计高分辨率(HR)图像或视频的问题。SR广泛用于各种计算机视觉任务,如卫星成像[4]和监视成像[17]。最近,基于深度学习的方法已成为解决SR问题的一种有前途的方法。视频SR的直接思想是逐帧执行单个图像SR。然而,它忽略了帧之间的时间相关性,输出的HR视频通常缺乏时间一致性,这可能会出现虚假的闪烁伪影。用于视频SR任务的大多数现有方法利用时间融合技术来提取数据中的时间信息,例如运动补偿[3,39],这通常需要手动设计的结构和更多的计算消耗。为了自动地同时利用空间和时间信息,自然要使用三维(3D)滤波器来替换二维(2D)过滤器。然而,额外的维度将带来更多的参数,并导致过重的计算复杂性。这种现象严重限制了视频SR方法中采用的神经网络的深度,从而削弱了性能[15]。
由于输入的LR视频和期望的HR视频之间存在相当大的相似性,因此残余连接广泛涉及各种SR网络[20,25,27],充分展示了残余连接的优势。然而,SR任务的剩余身份映射超出了充分的使用范围,它要么应用于HR空间[20,37],大大增加了网络的计算复杂性,要么应用于LR空间,以充分保留原始LR输入的信息[47],给网络最后部分的特征融合和升级阶段带来了沉重的负担。为了解决这些问题,我们提出了视频SR的快速时空残差网络(FSTRN)(图3)。由于高计算复杂性和内存限制,直接使用原始3D卷积(C3D)构建非常深的时空网络是困难和不切实际的。因此,我们提出了快速时空残差块(FRB)(图1c)作为FSTRN的构建模块,该模块由跳跃连接和时空因子化C3D组成。FRB可以大大降低计算复杂性,使网络能够同时学习时空特征,同时保证计算效率。此外,引入全局残差学习(GRL)以利用输入LR视频和期望HR视频之间的相似性。
一方面,我们采用LR空间残差学习(LRL)来提高特征提取性能。另一方面,我们进一步提出了一种跨空间剩余连接(CRL)来直接链接LR空间和HR空间。通过CRL,LR视频被用作“锚点”,以保留输出HR视频中的空间信息。对所提出的方法的理论分析提供了一个不明显依赖于网络大小(n是样本大小)的推广界O(1/√n),这保证了我们的算法对未知数据的可行性。对基准数据集评估的深入实证研究验证了所提出的FSTRN优于现有算法。
总之,本文的主要贡献有三个方面:我们提出了一种用于高质量视频SR的新框架快速时空残差网络(FSTRN)。网络可以同时利用空间和时间信息。通过这种方式,我们保持了时间一致性,并缓解了虚假闪烁伪影的问题。
我们提出了一种新的快速时空残差块(FRB),它将每个3D滤波器划分为两个具有显著较低维度的3D滤波器的乘积。通过这种方式,我们通过更深层次的神经网络架构显著降低了计算负载,同时提高了性能。
我们建议使用全局残差学习(GRL),其包括LR空间残差学习(LRL)和跨空间残差学习(CRL),利用输入LR视频和输出HR视频之间的显著相似性,显著提高了性能。
2. Related work
2.1. Single-image SR with CNNs
近年来,卷积神经网络(CNN)在许多计算机视觉任务中取得了重大成功[13,23,24,34,36],包括超分辨率(SR)问题。Dong等人首创了一种称为超分辨率卷积神经网络(SRCNN)的三层深度全卷积网络,以端到端的方式学习LR和HR图像之间的非线性映射[5,6]。从那时起,许多研究已经提出,这些研究通常基于更深的网络和更先进的技术。
随着网络的深入,残差连接已成为缓解深度神经网络优化困难的一种有前途的方法[13]。结合残差学习,Kim等人提出了非常深的卷积网络[20]和深度递归卷积网络(DRCN)[21]。这两个模型显著提高了性能,这表明了SR任务中剩余学习的潜力。Tai等人提出了具有递归块的深度递归残差网络(DRRN)和具有记忆块的深度密集连接网络[37],这进一步证明了残差学习的优越性能。
上述所有方法都适用于插值放大的输入图像。然而,将插值图像直接输入神经网络可能会导致非常高的计算复杂性。为了解决这个问题,提出了一种有效的亚像素卷积层[33]和转置卷积层[7],以便在网络末端将特征图升级到精细分辨率
采用剩余连接的其他方法包括EDSR[27]、SRResNet[25]、SRDenseNet[42]至RDN[47]。然而,剩余连接仅限于LR空间内。这些残差可以增强特征提取的性能,但会给网络的放大和融合部分带来过重的负载。
2.2. Video SR with CNNs
基于图像SR方法并进一步掌握时间一致性,大多数现有方法采用滑动帧窗口[3,18,19,26,39]。为了同时处理时空信息,现有的方法通常使用时间融合技术,例如运动补偿[3,19,26,39]、双向递归卷积网络(BRCN)[14]、长短期存储器网络(LSTM)[10]。Sajjadi等人使用了一种不同的方法,即使用帧递归方法,其中先前估计的SR帧也被重定向到网络中,这鼓励了时间上更一致的结果[32]。学习时空信息的一种更自然的方法是使用3D卷积(C3D),它在视频学习中表现出优异的性能[16,43,44]。Caballero等人[3]提到,慢融合也可以看作C3D。此外,Huang等人[15]使用C3D改进了BRCN,允许模型以自然的方式灵活地访问不同的时间上下文,但网络仍然很浅。在这项工作中,我们的目标是用C3D构建一个深度端到端视频SR网络,并保持高效的计算复杂性。
3. Fast spatio-temporal residual network
3.1. Network structure
在本节中,我们描述了所提出的快速时空残差网络(FSTRN)的结构细节。如图所示,FSTRN主要由四个部分组成:LR视频浅层特征提取网(LFENet)、快速时空残差块(FRB)、LR特征融合和上采样SR网(LSRNet),以及由LR空间残差学习(LRL)和跨空间残差学习(CRL)组成的全局残差学习(GRL)部分。
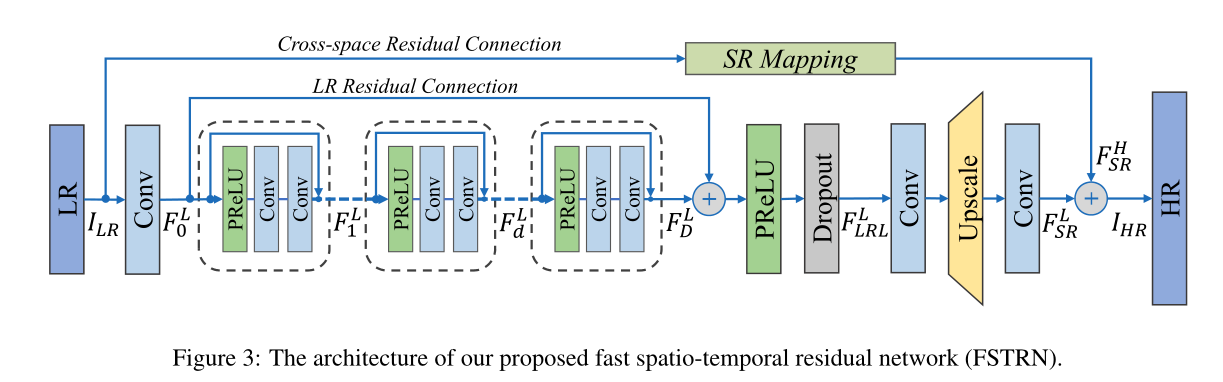
LFENet
简单地使用C3D层从LR视频中提取特征。让我们将FSTRN的输入和输出表示为ILR和ISR以及目标输出IHR,LFENet可以表示为:

FRBs
用于提取LFENet输出上的时空特征。假设使用了D个FRB,第一个FRB对LFENet输出执行,随后的FRB进一步提取前一个FRB输出的特征,因此第D个FRB的输出F Ld可以表示为:
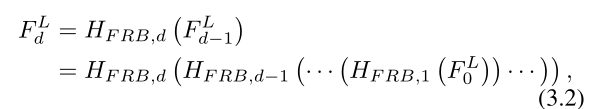
与FRB一起,进行LR空间残差学习(LRL)以进一步改进LR空间中的特征学习。LRL充分利用了前几层的特征,可以通过以下方式获得:
![]()
LSRNet
在对LRL进行有效的特征提取之后,将其应用于获得HR空间中的超分辨率视频。具体而言,我们使用C3D进行特征融合,然后使用反卷积[8]进行放大,再次使用C3D在LSRNet中进行特征图信道调谐。输出F LSR可表示为:
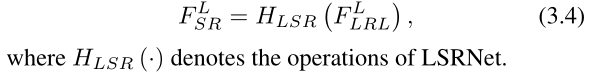
最后,网络输出由来自LSRNet的F LSR和额外的LR到HR空间全局残差组成,形成HR空间中的跨空间残差学习(CRL)。CRL的详细信息也在第3.3节中给出。因此,将从LR空间到HR空间的输入的SR映射表示为F HSR,FSTRN的输出可以获得为:
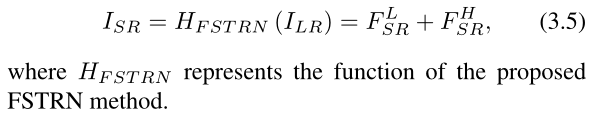
3.2. Fast spatio-temporal residual blocks
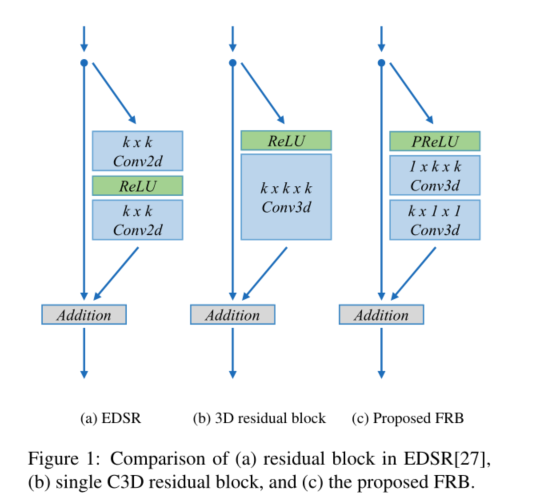
现在,我们介绍了所提出的快速时空残差块(FRB)的细节,如图1所示。残余块已被证明在计算机视觉中表现出优异的性能,尤其是在低级到高级任务中[20,25]。Lim等人[27]通过从SRResNet中的残差块中移除批量归一化层,提出了一种改进的残差块,如图1a所示,这显示了单图像SR任务的极大改进。为了将残差块应用于多帧SR,我们只保留一个卷积层,但将2D滤波器膨胀为3D,这类似于[16]。如图1b所示,k×k平方滤波器被扩展为k×k×k立方滤波器,赋予残差块额外的时间维度。在膨胀之后,随之而来的问题是显而易见的,因为它需要比2D卷积多得多的参数,伴随着更多的计算。为了解决这一问题,我们提出了一种新的快速时空残差块(FRB),通过将上述单个3D残差块上的C3D分解为两步时空C3D,即,我们用1×k×k滤波器替换膨胀的k×k×k立方滤波器,然后是k×1×1滤波器,这已被证明在训练和测试损失方面表现更好[44,46],如图1c所示。此外,我们将整流线性单元(ReLU)[9]更改为其变体PReLU,其中负部分的斜率是从数据而不是预定义的[12]中学习的。因此,FRB可表述为:

3.3. Global residual learning
在本节中,我们描述了在LR和HR空间上提出的全局残差学习(GRL)。对于SR任务,输入和输出高度相关,因此输入和输出之间的剩余连接被广泛使用。然而,先前的工作要么对放大的输入执行残差学习,这将导致高计算成本,要么直接在输入-输出LR空间上执行残差连接,然后对特征融合和放大的层进行放大,这给这些层带来了很大压力。为了解决这些问题,我们提出了LR和HR空间上的全局残差学习(GRL),它主要由两个部分组成:LR空间残差学习(LRL)和跨空间残差学习。
LR space residual learning (LRL) 与LR空间中的FRB一起引入。我们将残差连接应用于后续参数校正线性单元(PReLU)[12]。考虑到输入帧之间的高度相似性,我们还引入了丢弃层[35],以增强网络的泛化能力。因此,LRL的输出F LLRL可通过以下方式获得:
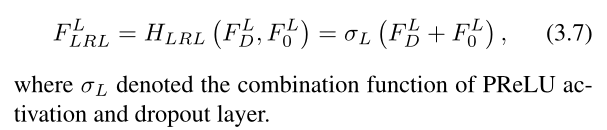
Cross-space residual learning (CRL)使用简单的SR映射将LR视频直接映射到HR空间,然后添加到LSRNet结果F LSR,形成HR空间中的全局残差学习。具体来说,CRL在输出中引入了插值LR,这可以大大减轻LSRNet的负担,有助于改善SR结果。到HR空间的LR映射可以表示为:

3.4. Network learning
......
4. Theoretical analysis
......
5. Experiments
在本节中,我们首先分析了网络的贡献,然后给出了所获得的实验结果,以定量和定性地证明所提出的模型在基准数据集上的有效性
5.1. Settings
Datasets and metrics.为了与现有作品进行公平比较,我们使用了25个YUV格式的基准视频序列作为我们的训练集,这些序列之前在[14,15,28,31,38]中使用过。我们在与[14]相同的基准挑战视频上测试了所提出的模型,设置相同,包括Dancing、Flag、Fan、Treadmill和Turbine视频,其包含具有严重运动模糊和混叠的复杂运动。在[5,41]之后,SR仅应用于亮度通道(YCbCr颜色空间中的Y通道),并使用亮度通道上的峰值信噪比(PSNR)和结构相似性(SSIM)评估性能。
Training settings. 在25 YUV视频序列数据集上执行数据增强。在[14,15]之后,为了扩大训练集,我们通过从训练视频中裁剪多个重叠的体积,以基于体积的方式训练模型。在裁剪过程中,我们将大的空间大小设置为144×144,时间步长设置为5,空间和时间步长分别设置为32和10。此外,受[40]的启发,还考虑了训练卷的翻转和转置版本。具体来说,我们将原始图像旋转了90◦ 并水平和垂直翻转它们。因此,我们可以从原始视频数据集生成13020个卷。之后,训练和测试LR输入生成过程分为两个阶段:用标准偏差为2的高斯滤波器平滑每个原始帧,并使用双三次方法对前一帧进行下采样。此外,为了在测试阶段保持输出帧的数量等于原始视频,在测试视频的头部和尾部应用了帧填充。
在这些实验中,我们专注于高阶因子4的视频SR,这通常被认为是视频SR中最具挑战性和最普遍的情况。FRB的数量和dropout rate 根据经验设置为5和0.3。Adam优化器[22]用于通过标准反向传播最小化损失函数。我们以1e−4的步长开始,然后在训练损失停止下降时将其减少了10倍。批处理大小是根据GPU内存大小设置的。
5.2. Study of FRB
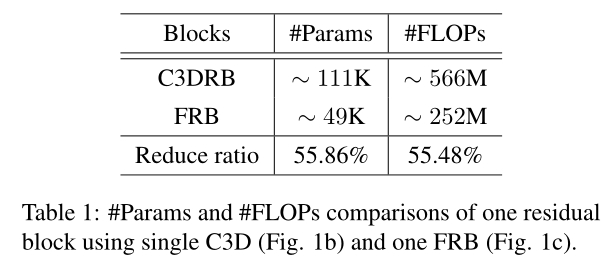
在本节中,我们研究了拟议的FRB对效率的影响。我们分析了与直接使用C3D构建的残差块(C3DRB)相比,FRB的计算效率。假设我们的所有输入和输出特征图大小为64,每个输入由5帧组成,大小为32×32,然后对所提出的FRB和C3DRB总结在表1中。很明显,FRB可以将参数和计算大大减少一半以上。通过这种方式,可以大大降低计算成本,因此我们可以构建一个更大的基于C3D的模型,在有限的计算资源下以更好的性能直接视频SR。
5.3. Ablation investigations
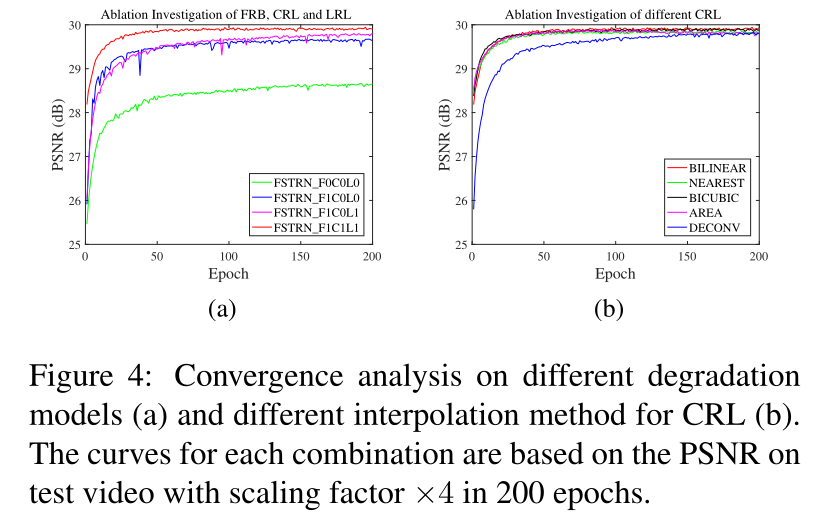
在本节中,我们进行了消融研究,以分析FRB和GRL在不同退化模型下的贡献。图4a显示了退化模型的收敛曲线,包括:1)在没有FRB、CRL和LRL的情况下获得的基线(FSTRN F0C0L0);2) 与FRB整合的基线(FSTRN F1C0L0);3) FRB和LRL基线(FSTRN F1C0L1);4) FRB、CRL和LRL(FSTRN F1C1L1)的所有组件的基线,这是我们的FSTRN。FRB的数量D设置为5,CRL使用双线性插值。
基线收敛缓慢,性能相对较差(绿色曲线),额外的FRB大大提高了性能(蓝色曲线),这可能是由于有效的帧间特征捕获能力。正如预期的那样,LRL进一步提高了网络性能(品红色曲线)。最后,应用CRL的添加(红色曲线),在LR和HR空间上构成GRL。可以清楚地看到,该网络具有更快的收敛速度和更好的性能,这表明了FRB和GRL的有效性和优越性。
基线收敛缓慢,性能相对较差(绿色曲线),额外的FRB大大提高了性能(蓝色曲线),这可能是由于有效的帧间特征捕获能力。正如预期的那样,LRL进一步提高了网络性能(品红色曲线)。最后,应用CRL的添加(红色曲线),在LR和HR空间上构成GRL。可以清楚地看到,该网络具有更快的收敛速度和更好的性能,这表明了FRB和GRL的有效性和优越性。如图4b所示,除反褶积外,不同的插值方法表现几乎相同,原因是反褶积需要一个学习上采样滤波器的过程,而其他方法则不需要。所有不同的插值方法接近于几乎相同的性能,表明FSTRN的性能改进归因于GRL的引入,与CRL中的特定插值方法关系不大。
5.4. Comparisons with state-of-the-art
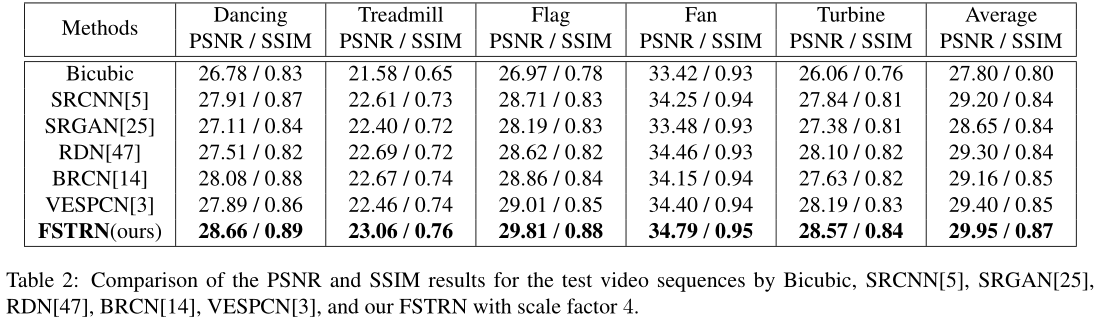
我们将所提出的方法与不同的单图像SR方法和最先进的多帧SR方法进行了定量和定性比较,包括双三次插值、SRCNN[5]、6]、SRGAN[25]、RDN[47]、BRCN[14、15]和VESPCN[3]。在以下比较中,FRB的数量D设置为5,CRL的升级方法设置为双线性插值。表2总结了所有方法的定量结果,其中评估指标为PSNR和SSIM指数。具体而言,与最先进的SR方法相比,所提出的FSTRN显示出显著的改进,平均PSNR和SSIM分别超过了0.55dB和0.2。
除了定量评估外,我们还提供了单帧(图2)和多帧(图5)SR比较的一些定性结果,显示了原始帧和×4 SR结果之间的视觉比较。很容易看出,所提出的FSTRN恢复了最精细的细节,并产生了最令人满意的结果,无论是视觉上还是关于PSNR/SSIM索引。我们的结果显示了更清晰的输出,即使在被公认为SR中最难处理的网格处理中,FSTRN也能很好地处理它,显示出令人满意的性能。
6. Conclusion
在本文中,我们提出了一种用于视频SR问题的快速时空残差网络(FSTRN)。我们还设计了一种新的快速时空残差块(FRB),以同时提取时空特征,同时确保高计算效率。除了在LR空间上使用残差来增强特征提取性能之外,我们还提出了跨空间残差学习,以利用低分辨率(LR)输入和高分辨率(HR)输出之间的相似性。理论分析为泛化能力提供了保证,经验结果验证了所提出方法的优势,并证明所提出的网络显著优于当前最先进的SR方法。

















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









