







前言
文章性质:学习笔记 📖
学习资料:吴茂贵《 Python 深度学习基于 PyTorch ( 第 2 版 ) 》【ISBN】978-7-111-71880-2
主要内容:根据学习资料撰写的学习笔记,该篇主要介绍了注意力机制的基本概念,以及带注意力机制的编码器-解码器架构。
第八章の开篇
注意力机制 Attention Mechanism 在深度学习中发展迅猛,尤其近几年,随着它在自然语言处理、语音识别、视觉处理等领域的应用,更是引起大家的高度关注。如 Seq2seq 引入注意力机制、Transformer 使用自注意力机制,在自然语言处理、视觉处理、推荐系统等任务上刷新记录,取得突破。本章将从多个角度介绍注意力机制,具体包括:
- 注意力机制概述
- 带注意力机制的编码器-解码器架构
- Transformer
- 使用 PyTorch 实现 Transformer
一、注意力机制概述
注意力机制源于对人类视觉的研究,注意力是一种人类不可或缺的复杂认知功能,指人可以在关注一些信息的同时忽略另一些信息的选择能力。注意力机制的逻辑与人类看图像的逻辑类似,当我们看一张图像时,并没有看清它的全部内容,而是将注意力集中在图像的重要部分。重点关注部分,就是通常所说的注意力集中部分,对这部分投入更多注意力资源,以获取更多所关注目标的细节信息,抑制其他无用信息。这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制。人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。
深度学习中也应用了类似注意力机制,通过使用这种机制极大提升了自然语言处理、语音识别、图像处理的效率和性能。
1、两种常见注意力机制
根据 注意力范围 的不同,可以将注意力分为 软注意力 Soft Attention 和 硬注意力 Hard Attention:
1)软注意力:这种方式是对全局进行计算( Global Attention),相当于对所有 key 求权重概率,每个 key 都有一个对应的权重。
这种方式比较理性,它参考了所有 key 的内容,再进行加权,但是计算量可能会比较大。
2)硬注意力:这种方式是直接精准定位到某个键,而忽略其他键,相当于这个 key 的概率是 1 ,其余 key 的概率全部是 0 。
这种方式要求很高,需要一步到位,但实际情况往往包含其他状态,如果没有正确对齐,会带来很大的影响。
2、来自生活的注意力
注意力是人类与环境交互的一种天生的能力。环境中的信息丰富多彩,我们不可能对映入眼帘的所有事物都持有一样的关注度或注意力,而是一般只将注意力引向感兴趣的一小部分信息,这种能力就是注意力。
我们按照对外界的反应将注意力分为 非自住性提示 和 自主性提示 。其中,非自住性提示是基于环境中物体的状态、颜色、位置、易见性等,不由自主地引起我们的注意。如图 8-1 所示,这些活动小动物最初可能都会自动引起小朋友的注意力。

但是经过一段时间后,小朋友可能会重点关注他喜欢的小汽车玩具。此时,他选择小汽车玩具是受到了认知和意识的控制,因此基于兴趣或自主性提示的吸引力更大,也更持久。
3、注意力机制的本质
在注意力机制背景下,我们将自主性提示称为 查询 Query 。对于任何给定查询,注意力机制通过 集中注意力 Attention Pooling 选择 感官输入 Sensory Input ,这些感官输入被称为值 Value 。每个值都与其对应的非自主提示的一个 Key 对应,如图 8-2 所示。
💡 通过集中注意力,为给定的查询(自主性提示)与键(非自主提示)进行交互,从而引导选择偏向值(感官输入)。
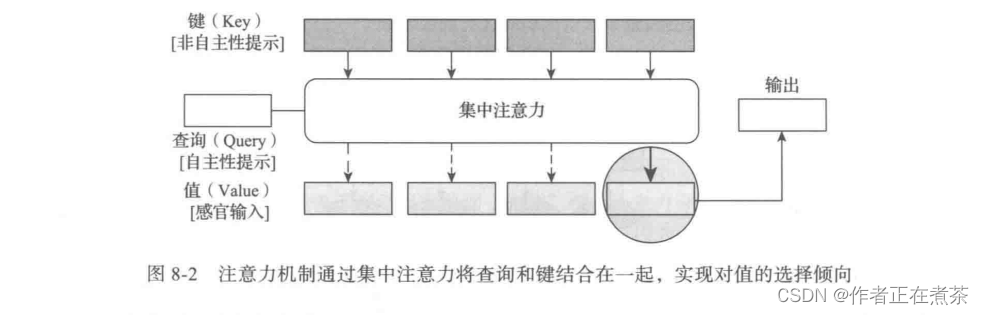
可以对图 8-2 所示的注意力框架进一步抽象,以便更深入地理解注意力机制的本质。
在自然语言处理应用中,把注意力机制看作 输出 Target 句子中某个单词与 输入 Source 句子中每个单词的相关性非常有道理。
目标句子生成的每个单词对应输入句子中的单词的概率分布可以理解为 输入句子的单词与这个目标生成单词的对齐概率 ,这在机器翻译语境下是非常直观的;在传统的统计机器翻译过程中,通常会专门有一个短语对齐的步骤,而注意力模型的作用与此相同,可用图 8-3 进行直观表述。
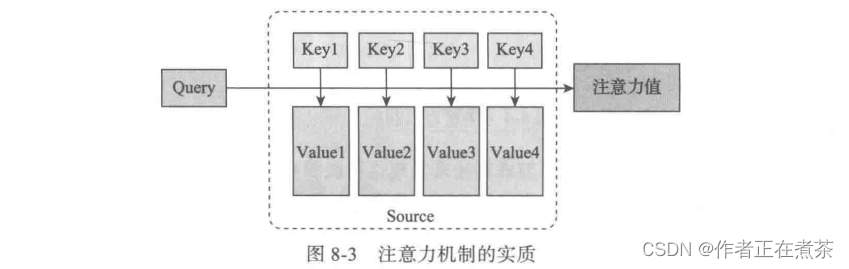
在图 8-3 中,Source 由一系列 <Key, Value> 数据对构成,对于给定 Target 中的某个元素 Query ,通过计算 Query 与各个 Key 的相似性或者相关性,得到每个 Key 对应 Value 的权重系数,然后对 Value 进行加权求和,即得到了最终的注意力值。所以本质上注意力机制是 对 Source 中元素的 Value 进行加权求和 ,而 Query 和 Key 用于计算对应 Value 的权重系数。
可以将上述思想改写为如下公式:
![]()
其中,T 为 Source 的长度。
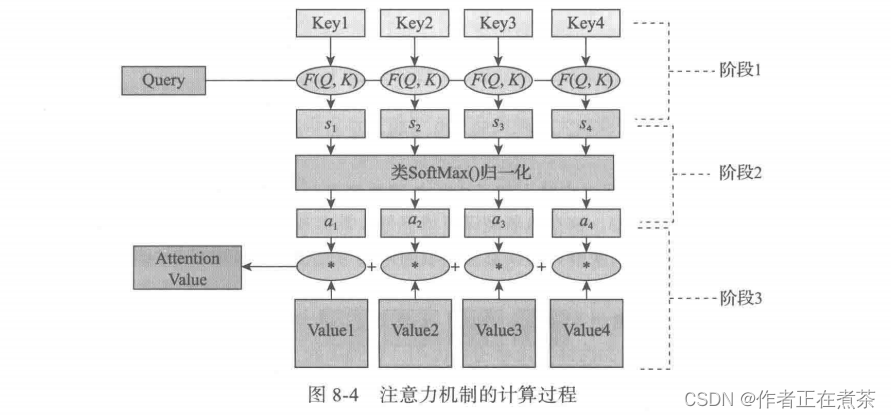
具体如何计算注意力呢?整个注意力机制的计算过程可分为 3 个阶段。
第 1 阶段:根据 Query 和 Key 计算两者的相似性或相关性,最常见的方法包括求两者的向量点积、求两者的向量 Cosine 相似性、通过引入额外的神经网络来求,这里假设求得的相似值为 。
第 2 阶段:对第 1 阶段的值进行归一化处理,得到权重系数。这里使用 softmax 函数计算各权重的值,计算公式为:
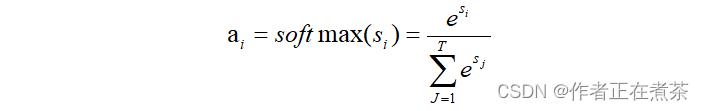
第 3 阶段:用第 2 阶段的权重系数对 Value 进行加权求和,计算公式为:
![]()
如图 8-4 所示,呈现了上述 3 个阶段的计算过程。
那么在深度学习中如何通过模型或算法来实现这种机制呢?接下来我们将介绍如何使用这种模型的方式来实现注意力机制。为了更好地比较,我们先介绍一种不带注意力机制的架构,然后介绍带注意力机制的架构。
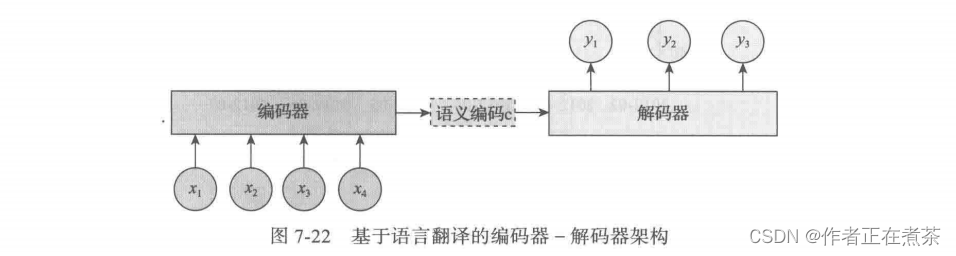
二、带注意力机制的编码器-解码器架构
由图 7-22 可知,在生成目标句子的单词时,不论生成哪个单词,如 、
、
等,使用的句子 X 的语义编码 C 都是一样的,没有任何区别。而语义编码 C 是由句子 X 的每个单词经过编码器编码生成,这意味着不论是生成哪个单词,句子 X 中的任意单词对生成的某个目标单词
来说影响力都是相同的,没有任何区别。
我们用具体例子来说明,用机器翻译(输入英文输出中文)来解释这个分心模型的编码器-解码器架构,例如:
输入英文句子:Tom chase Jerry,通过编码器-解码器架构逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。在翻译 “ 杰瑞 ” 这个中文单词时,分心模型中的每个英文单词对于翻译目标单词 “ 杰瑞 ” 的贡献是相同的,这是不太合理的,因为显然 “ Jerry ” 对于翻译成 “ 杰瑞 ” 更重要,但是分心模型无法体现这一点,这就是为何说它没有引入注意力的原因。
1、引入注意力机制
没有引入注意力机制的模型在输入句子比较短的时候估计问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,会丢失很多细节信息,这也是为何要引入注意力机制的原因。
在上面的例子中,如果引入注意力机制,则应该在翻译 “ 杰瑞 ” 时,体现出不同英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面的一个概率分布值:
(Tom, 0.3) (Chase, 0.2) (Jerry, 0.5)每个英文单词的概率代表了翻译当前单词 “ 杰瑞 ” 时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标单词肯定是有帮助的,因为引入了新的信息。同理,目标句子中的每个单词都应该学会其对应的源语句中单词的注意力分配概率信息。这意味着在生成每个单词 时,原先相同的中间语义表示
会替换成根据当前生成单词而不断变化的
。即由固定的中间语义表示
换成了根据当前输出单词而不断调整成加入注意力模型的变化的
。增加注意力机制的编码器-解码器架构如图 8-5 所示。
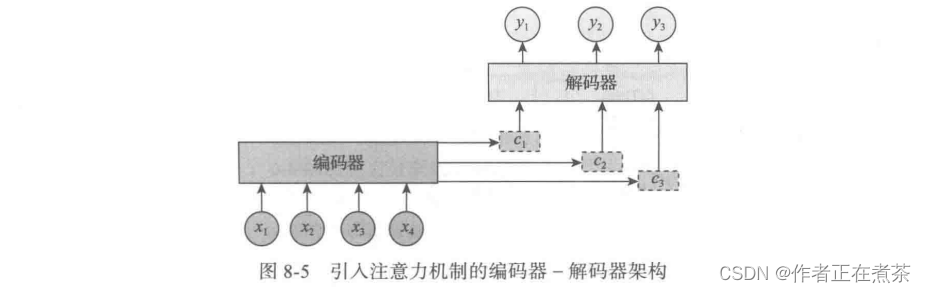
即生成目标句子单词的过程变成如下形式:
而每个 可能对应着不同的源语句中单词的注意力分配概率分布,比如对于上面的英汉翻译而言,其对应的信息可能如下。
注意力分布矩阵:
其中,第 行表示
收到的所有来自输入单词的注意力分配概率。
的语义表示
由这些注意力分配概率与编码器对单词
的转换函数
相乘计算得出,例如:
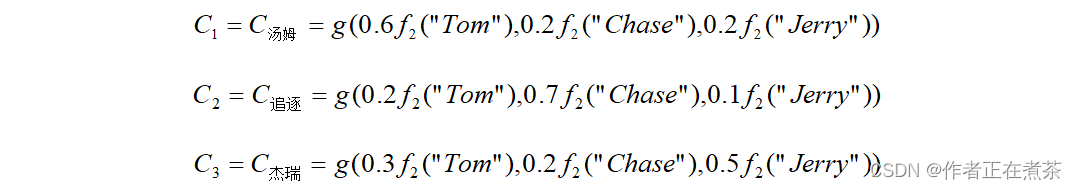
其中, 函数代表编码器对输入英文单词的某种变换函数,比如如果编码器是用 RNN 模型,这个
函数的结果往往是某个时刻输入
后隐含层节点的状态值;
代表编码器根据单词的中间表示合成整个句子中间语义表示的变换函数。通常
函数就是对构成元素加权求和,也就是常常在论文里看到的下列公式:
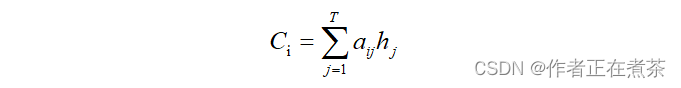
假设 中的
就是上面的 “ 汤姆 ” ,那么
就代表输入句子的长度 3 ,并且:
它们对应的注意力模型权值分别是 0.6 、0.2 、0.2 ,所以 函数就是一个加权求和函数。
更形象一点,翻译中文单词 “ 汤姆 ” 时,数学公式对应的中间语义表示 的生成过程可用图 8-6 所示。
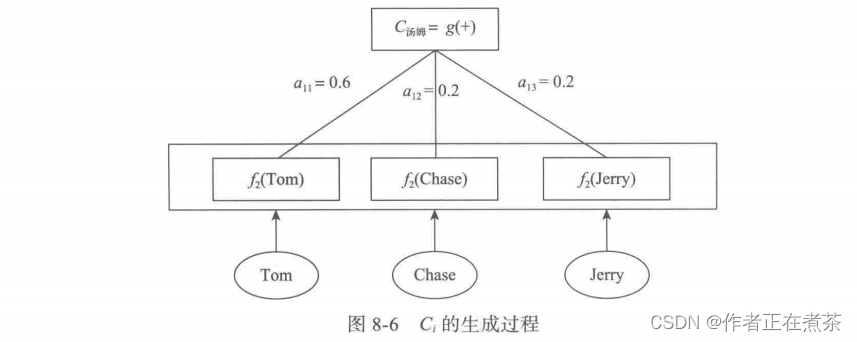
这里还有一个问题:如果需要生成目标句子中的某个单词,比如 “ 汤姆 ” ,我们该如何知道注意力模型所需要的输入句子中单词的注意力分配概率分布值呢?下一节将详细介绍。
2、计算注意力分配概率分布值
如何计算注意力分配概率分布值?为了便于说明,假设对前面图 7-22 的未引入注意力机制的编码器-解码器架构进行细化,编码器采用 RNN 模型,解码器也采用 RNN 模型,这是比较常见的模型配置,如图 8-7 所示。
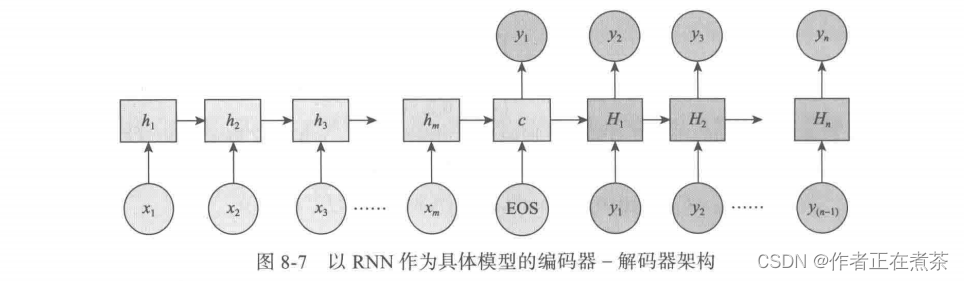
图 8-8 可以较为便捷地说明注意力分配概率分布值的通用计算过程。
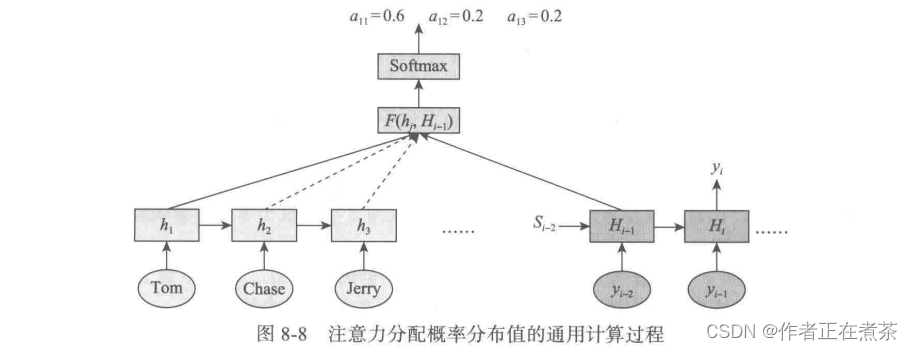
我们的目的是计算生成 时,输入句子中的单词 “ Tom ” “ Chase ” “ Jerry ” 对
的注意力分配概率分布。这些概率可以用目标输出句子
时刻的隐含层节点状态
去逐个与输入句子中每个单词对应的 RNN 隐含层节点状态
进行对比。
换言之,通过对比函数 来获得目标单词与每个输入单词的对齐可能性。函数
在不同的论文里可能会采取不同的方法,该函数的输出经过经过 softmax 激活函数进行归一化后就得到一个 0-1 的注意力分配概率分布值。
绝大多数注意力模型都采取上述计算框架来计算注意力分配概率分布值,区别只是函数 在定义上可能有所不同。
如图 8-9 所示, 值的生成过程。
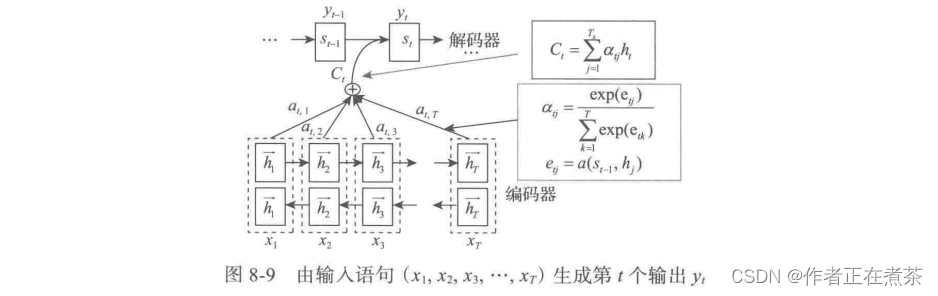
其中:
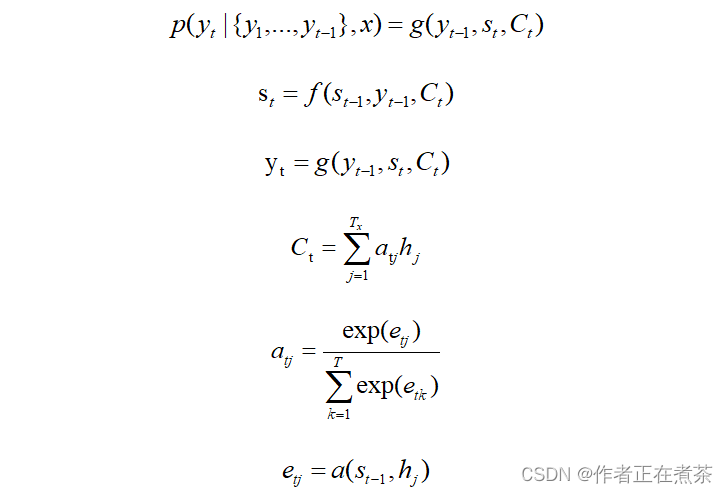
上述内容就是软注意力模型的基本思想,那么该如何理解 注意力模型的物理含义 呢?通常,文献里会把注意力模型看作单词对齐模型,这是非常有道理的。前面提到,目标句子生成的每个单词对应输入句子单词的概率分布 可以理解为 输入句子单词与这个目标生成单词的对齐概率 ,这在机器翻译环境下是非常直观的。当然,从概率上理解的话,把注意力模型理解成 影响力模型 也是合理的。即生成目标单词时,注意力模型表示 输入句子的每个单词对于生成这个单词的影响程度 。这也是理解注意力模型物理意义的方式。
注意力机制除了 软注意力 之外,还有 硬注意力、全局注意力、局部注意力、自注意力 等,它们对原有的注意力架构进行了改进。
到目前为止,在我们介绍的编码器-解码器架构中,构成编码器或解码器的通常是循环神经网络,如 RNN 、LSTM 、GRU 等,这种架构在遇上大语料库时,运行速度将非常缓慢,这主要是由于循环神经网络无法并行处理。那么,考虑到 卷积神经网络 的并行处理能力较强,我们是否可以使用卷积神经网络构建编码器-解码器架构呢?卷积神经网络也存在不足,如无法处理长度不一的语句、对时间序列不敏感等。为了解决这些问题,人们研究出了一种新的注意力架构 —— Transformer 。
















 8176
8176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











