







在昨天的文章中,我复盘了 均值滤波(滑动平均滤波)、中值滤波、指数滤波、高斯滤波 这些基本滤波方法。这些方法虽然简单易用,但在 复杂环境下(如高噪声、动态系统) 可能存在不足。它们有一个共同的问题:
- 只能基于过去的数据进行简单的平滑处理,但无法预测未来。
- 无法区分真实信号和噪声,一旦数据波动较大,它们可能会使信号失真。
今天,我将复盘更高级的滤波方法:卡尔曼滤波(Kalman Filter,KF),它的核心特点是:
✅ 能够预测数据的未来趋势
✅ 结合当前数据进行修正,使预测更加准确
✅ 可以处理动态变化的系统,比如目标跟踪、导航定位等
✅ 能够区分信号和噪声,即使数据被干扰,依然能估计出真实值
在查看网上各种关于卡尔曼滤波的资料时,发现几乎都是通过数学模型带领大家了解学习,因此我在考虑如果通过简单直白的方式,让我同组并没有平差基础的学弟学妹了解卡尔曼滤波,所以下面我会用尽量简单、直白的话语和例子来解释和介绍卡尔曼滤波。
1.卡尔曼滤波的核心思想
卡尔曼滤波的思想其实很简单,就是 不断进行“预测”和“修正”:
- 预测:基于之前的数据,估算当前的值。
- 修正:用传感器或测量数据,对预测值进行调整,使其更加准确。
- 重复上述步骤,不断优化,使误差越来越小。
2.状态变量(State Variables)是什么
在卡尔曼滤波中,我们用一个状态变量 来描述系统的状态。
比如,在定位问题中,状态变量可能包含:
- 仅位置:
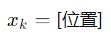
- 位置 + 速度:
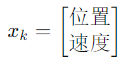
- 位置 + 速度 + 加速度:
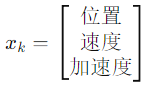
卡尔曼滤波的目标就是估计状态变量
3.下面结合实际,来简单的讲述卡尔曼滤波的公式:
假设一个汽车:
- 当前在 5 米 的位置。
- 速度是 2 米/秒。
- 你想预测它1 秒后的位置。
那么:预测位置=5+2=7 米
这就是卡尔曼滤波的预测阶段:
:预测的状态,在这个情景下表示为
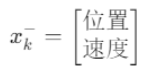
A: 状态转移矩阵,描述状态如何从上一个时刻 k−1 变化到当前时刻 k。(例如速度的影响)
(可以把状态转移矩阵 A理解为一个“时间推进器”,它决定了当前状态如何变化到下一时刻。
例如:
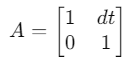
表示:1. 新位置 = 旧位置 + 速度 × 时间 2. 速度保持不变
B: 控制输入对状态的影响程度(控制矩阵)
:控制输入(Control Input),表示 外部施加的影响,例如 加速、刹车、方向调整等。如果没有外部输入,B
这部分可以忽略。
以上就是你预测汽车位置的一个过程,这在卡尔曼滤波中被定义为:预测阶段(Prediction Step),但是现实世界并不是完美的,测量数据会受到噪声影响,所以就还有接下来的过程,被称作修正阶段(Correction Step)
如果你用测距仪器(有误差)发现汽车的位置是 6.5 米,而预测是 7 米,你会怎么办?
👉 你不会完全相信预测值(速度或者位置是有一定偏差的 不是确定的5米初始位置和确定的2米/s的速度),也不会完全相信测量值(因为测量值也有误差),而是取一个折中值!取折中值的方式就是其实就是取一个权重
这个过程称为修正(Correction):
也可以写成:
:测量值(用测量仪测的距离是6.5 米)
:预测值(你自己算出来是7米)
:卡尔曼增益,决定如何在预测和测量之间取折中。其实就相当于一个权重:如果测量值很可靠(传感器误差很小),那么
取较大值,我们更相信测量值。如果测量值噪声较大,那么
取较小值,我们更依赖预测值。
比如我们让=0.75(假设我们认为传感器测量较准确,但也不是说非常非常非常准)
按照公式:汽车真实的位置=0.75⋅6.5+0.25⋅7=6.625 米
上面就是最简单的卡尔曼滤波的过程。
我们刚刚讲的例子里,测量值 和状态变量
都是 位置,所以直接做加权平均即可。但如果测量的不是位置,而是速度,我们该怎么办?
这时候,我们需要引入 观测矩阵 H!
在某些情况中,我们的状态变量不仅仅是位置,还可能包括速度、加速度等多个变量。例如:
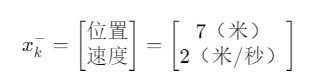
但我们的测量设备可能只能测量其中一部分信息,测量值只有速度,我们不能直接做加权平均,而是要从状态变量中提取出速度信息。那么H矩阵在这时候就定为:
![]()
那么
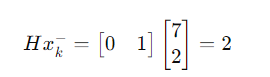
(由于测量值仅包含速度,而状态变量同时包含位置和速度,因此我们通过矩阵 HHH 提取状态变量中对应的速度信息,以确保修正过程仅影响速度,而不会改变位置。)
这样,我们就能正确计算修正值:
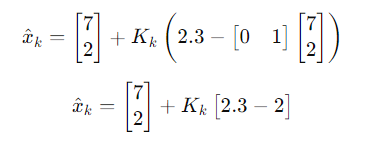
这就是矩阵 H的作用:只让测量到的部分进行修正,不会影响其他状态变量。
以上就是简单的卡尔曼滤波理解了,简单来说,就是先根据上一时刻状态进行预测,然后结合测量值进行修正,不断优化估计结果。
但是理解了以上的过程,也只是刚刚入门卡尔曼滤波的流程,真正的理解卡尔曼滤波,还需要掌握以下几个关键点:
- B 矩阵是什么?
代表什么?
- 卡尔曼增益
的计算过程
4.B 矩阵与是什么?
B 描述控制输入 如何影响状态,不同的系统有不同的 B 形式。
还是刚刚那个汽车直线运动的例子,在这个例子中,状态变量为
在没有外部控制输入的情况下,状态转移方程为:
其中:
也就是说:
表示:
- 新位置 = 旧位置 + 速度 × 时间(x=x0+v0t)。
- 速度保持不变(如果没有加速度作用)。
如果汽车受到了加速度 a的作用,那么:
物理规律:
- 位置变化:
- 速度变化:
那么:
所以控制输入对状态变量的影响:
最终的完整状态预测公式:
这表示:
- 如果没有外部控制,那么状态仅由 AA 矩阵决定(惯性运动)。
- 如果有外部控制,那么加速度会影响位置和速度,并通过 B 矩阵建模。
✅状态预测 = 惯性运动() + 控制输入(
)。
✅ 如果没有外部控制,=0,状态完全由 A 预测。
✅ 如果有加速度 a,那么 让加速度影响位置和速度,状态预测更加精准!
5.卡尔曼增益 的计算过程
在卡尔曼滤波的修正阶段,我们希望在预测值和测量值之间取一个最佳的折中。
- 如果测量值很可靠(误差很小),那么我们更应该信任测量值。
- 如果测量值误差较大,那么我们应该更依赖预测值。
计算 之前,先理解“误差”
在卡尔曼滤波中,我们不仅要估计状态(如位置),还要估计这个状态的误差大小。
我们用误差协方差矩阵来衡量估计的可信度:
- 如果
很大,说明我们的预测值不太可信,误差较大。
- 如果
此外,测量值也有误差,我们用测量噪声协方差 R来衡量测量值的可信度:
- 如果 R 很小,说明测量值很准确。
- 如果 R 很大,说明测量值噪声较大,我们应该更依赖预测值。
为了让估计值更准确,我们希望:
- 如果 预测值不确定性大(
。
- 如果 测量值不确定性大(R 很大),那么
。
这个权重的计算公式如下:
看到这个公式,感觉已经不想学了是吧.....(我刚学到的时候也是:这什么xx东西!)
先不要被公式吓到,我们分步拆解它的意义。(当你有耐心看到这里的时候,你已经无敌了)
首先,我们把这个公式里所有的符号代表的意思整理一下:
-
简单来说,就是用来决定我们到底更相信预测值,还是更相信测量值的。 -
简单理解:- 如果预测越不确定(误差越大),则这个矩阵越“大”。
- 如果预测越准确(误差越小),则这个矩阵越“小”。
-
H:这个叫做测量矩阵,用来把预测状态(比如位置、速度这些东西)变换成测量空间中的值。
通常 H 会告诉我们,“实际测量到的数据”和“预测的状态”之间是怎样一种关系。 -
R:这个是测量噪声协方差矩阵,表示我们测量值中误差(用测距仪器得到的汽车位置)的不确定性。
- 如果测量值越准确(误差越小),则 R 越“小”。
- 如果测量值越不准(误差越大),则 R 越“大”。
-
上标T(
):代表矩阵转置,简单来说,就是把原来矩阵的行和列交换位置
-
上标-1:代表矩阵求逆,我们把它看作类似于除法运算的概念,理解为它能“消除”矩阵的作用。
好了 接下来我们解释公式中的: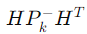
我们有一个预测的结果(例如:你猜测自己走路去了某个位置,但你不确定你是否猜准了),我们要知道这个预测有多大的误差这个误差到底有多大呢?我们把预测的误差表示为。但是,预测误差通常是表示状态的(比如:位置、速度),而我们测量到的值不一定是位置和速度本身,比如可能只是距离或某个间接的测量量。
此时我们需要一个东西,把预测误差从状态空间(例如位置)“映射”或“换算”到 测量空间(你实际测量到的距离)里去。
这个“换算工具”,就是我们说的 H 矩阵。用更简单的话理解:
是告诉你:“我位置可能不准了”
- 乘以 H,变成了
,意思就变成了:“假如位置不准了,那么我这个测量值(比如距离)会不准到什么程度?”
这一步本质上在衡量:“预测状态的不确定性”会导致测量空间里的误差到底有多大。
我们测量得到的数据本身也有误差,叫 R。测量本身也会带来不确定性(仪器不准、噪声干扰等)
所以,我们把预测带来的测量空间误差 和测量本身的误差 R 相加:
这个式子告诉你:“如果我同时考虑预测和测量的不确定性,整体误差到底有多大?”
好了,现在我们知道了两个误差:
- 预测的不确定性(在测量空间):
- 总的误差(预测不确定性+测量误差):
接下来,我们就想知道:
在总的误差里面,预测误差到底占了多大的比重?
用数学表达就是用 除以这个总误差
,得到比例,也就是卡尔曼增益:
那么现在就是如何计算和R了
我们已经知道了:
- R表示的是测量误差协方差矩阵(测量误差)。
接下来我们一个一个详细看:
(一) 如何计算 ?
它的计算公式如下:
别慌,我们再慢慢解释公式中的每个字母:
:状态转移矩阵(State Transition Matrix),简单理解就是告诉你:“状态是怎么从上一步变化到这一步的?”(类比于最上面公式的A)
- 比如汽车从上一秒的位置到这一秒的位置,会根据速度发生变化,
- 比如汽车从上一秒的位置到这一秒的位置,会根据速度发生变化,
:上一时刻(k−1时刻)的误差协方差矩阵(上一步你已经算出来了)。
:过程噪声协方差矩阵,。表示的是过程噪声
的方差:
![]()
其中:
- E[⋅]代表数学期望

这儿就不细讲了,还是需要用到平差里的知识...... 如果感兴趣,后面单独出一章讲吧
(二) 如何计算R?
R 是测量噪声协方差矩阵,表示测量误差大小。你的测量设备(例如GPS、雷达、传感器)本身存在的误差程度。R一般不是计算出来的,而是提前设定的:
因为我们通常事先知道自己用的测量工具大概的误差是多少。
- 比如你买了一个温度计,厂家就告诉你它的误差大约是 ±0.5℃。
- 再比如你使用GPS,GPS厂家或设备说明书可能告诉你,位置测量精度一般在 ±3米 左右。
📌 实际使用中:
- R一般是由设备生产商或者通过实验标定的。
- 如果是多个测量数据组成的测量空间(比如测了距离、速度两个量),那么 RRR 就是个矩阵,每个对角线元素表示各个测量量的不确定性。
这里会有人无法理解几个问题,我这边总结一下,看看有没有你的疑问
1.为什么分子是而不是
啊?
答:是你预测的误差,你的误差在于状态空间维度,还是拿最初的汽车运动举例子,你预测的位置或者速度可能存在误差,但我们的测量数据不一定直接测的是位置或速度,可能测的是距离、角度等其他量(测量空间),你需要通过变化矩阵把误差转换到测量空间维度。
2.为什么一会儿是,一会儿是
啊?
答:
直观地用一个生活化例子说明:
比如你早上出门前先预测今天的气温(预测阶段),你猜大概25℃,但是你也知道可能预测有2℃左右的误差:
- 此时你对温度的不确定性(预测误差)是:25℃ ± 2℃。(这个就是
然后你看了一眼手机的实时温度测量值(测量阶段),它显示现在是24℃,你知道手机的测量误差可能是±1℃:
- 这时候你要修正自己的预测,你一定会根据“自己预测误差(2℃)”和“手机测量误差(1℃)”两个值去综合考虑。
你用的预测误差(2℃)就是 :
- 因为此时你还没真正确定下来最终值(还没更新)。
- 当你综合手机测量值后,修正成更准确的预测值(比如修正成24.5℃)后,你才得到真正更新后的误差(比如 ±0.8℃),这个更新后的误差才是
所以,计算修正(卡尔曼增益)过程中自然只能用预测误差 ,因为此时还没有最终更新值
。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









