










通过将更基本的概率分布(例如高斯分布)进行线性组合的这样的叠加方法,可以被形式化为概率模型,被称为混合模型。通过使用足够多的高斯分布,并且调节它们的均值和方差以及线性组合的系数,几乎所有的连续概率密度都能以任意的精度去近似。
我们考虑K个高斯概率密度的叠加,形式为
p
(
x
)
=
∑
k
=
1
K
π
k
N
(
x
∣
u
k
,
Σ
k
)
p(x)=\sum_{k=1}^{K}\pi_{k}N(x|u_{k},\Sigma_{k})
p(x)=k=1∑KπkN(x∣uk,Σk)这就被称为混合高斯。参数
π
k
\pi_{k}
πk被称为混合系数并且
∑
k
=
1
K
π
k
=
1
\sum_{k=1}^{K}\pi_{k}=1
∑k=1Kπk=1。根据概率的加和规则和乘积规则,边缘概率密度为
p
(
x
)
=
∑
k
=
1
K
p
(
k
)
p
(
x
∣
k
)
p(x)=\sum_{k=1}^{K}p(k)p(x|k)
p(x)=k=1∑Kp(k)p(x∣k)其中我们把
π
k
=
p
(
k
)
\pi_{k}=p(k)
πk=p(k)看成选择第k个成分的先验概率,把密度
N
(
x
∣
u
k
,
Σ
k
)
=
p
(
x
∣
k
)
N(x|u_{k},\Sigma _{k})=p(x|k)
N(x∣uk,Σk)=p(x∣k)看成以k为条件的概率。后验概率
p
(
k
∣
x
)
p(k|x)
p(k∣x)起着一个重要作用,它也被成为责任。根据贝叶斯定理,我们可以写出后验概率
γ
k
(
x
)
=
p
(
k
∣
x
)
=
p
(
k
)
p
(
x
∣
k
)
∑
l
p
(
l
)
p
(
x
∣
l
)
=
π
k
N
(
x
∣
u
k
,
Σ
k
)
∑
l
π
l
N
(
x
∣
u
l
,
Σ
l
)
\gamma_{k}(x)=p(k|x)=\frac{p(k)p(x|k)}{\sum_{l}p(l)p(x|l)}=\frac{\pi_{k}N(x|u_{k},\Sigma_{k})}{\sum_{l}\pi_{l}N(x|u_{l},\Sigma_{l})}
γk(x)=p(k∣x)=∑lp(l)p(x∣l)p(k)p(x∣k)=∑lπlN(x∣ul,Σl)πkN(x∣uk,Σk)很自然地对数似然函数可以表示为
l
n
p
(
X
∣
π
,
u
,
Σ
)
=
∑
n
=
1
N
l
n
{
∑
k
=
1
K
π
k
N
(
x
n
∣
u
k
,
Σ
k
)
}
\mathrm{ln}p(X|\pi,u,\Sigma)=\sum_{n=1}^{N}\mathrm{ln}\left\{ \sum_{k=1}^{K}\pi_{k}N(x_{n}|u_{k},\Sigma_{k})\right\}
lnp(X∣π,u,Σ)=n=1∑Nln{k=1∑KπkN(xn∣uk,Σk)}其中
X
=
{
x
1
,
.
.
.
,
x
n
}
X=\left \{ x_{1},...,x_{n}\right \}
X={x1,...,xn},
π
=
{
π
1
,
.
.
.
,
π
k
}
\pi=\left \{ \pi_{1},...,\pi_{k}\right \}
π={π1,...,πk},
u
=
{
u
1
,
.
.
.
,
u
k
}
u=\left \{ u_{1},...,u_{k}\right \}
u={u1,...,uk},
Σ
=
{
Σ
1
,
.
.
.
,
Σ
k
}
\Sigma=\left \{ \Sigma_{1},...,\Sigma_{k}\right \}
Σ={Σ1,...,Σk}。因为对数中存在一个求和式,这会导致参数的最大似然解不再有一个封闭式的解析解。一个方法就是期望最大化(EM)的强大框架。
我们先来看看高斯混合模型是如何得到的
我们引入一个K维二值随机变量z,这个变量采用了1-of-K表示方法,其中一个特定的元素
z
k
=
1
z_{k}=1
zk=1,其余所有的元素等于0。于是
z
k
z_{k}
zk的值满足
z
k
∈
{
0
,
1
}
z_{k}\in \left\{ 0,1\right\}
zk∈{0,1}。我们根据边缘概率分布
p
(
z
)
p(z)
p(z)和条件概率分布
p
(
x
∣
z
)
p(x|z)
p(x∣z)来定义联合概率分布。z的边缘概率分布根据混合系数
π
k
\pi_{k}
πk进行赋值
p
(
z
k
=
1
)
=
π
k
p(z_{k}=1)=\pi_{k}
p(zk=1)=πk
0
≤
π
k
≤
1
,
∑
k
=
1
K
π
k
=
1
0\leq\pi_{k}\leq1,\sum_{k=1}^{K}\pi_{k}=1
0≤πk≤1,k=1∑Kπk=1由于
z
z
z使用了1-of-K表示方法,因此我们可以将这个概率分布写成
p
(
z
)
=
∏
k
=
1
K
π
k
z
k
p(z)=\prod_{k=1}^{K}\pi_{k}^{z_{k}}
p(z)=k=1∏Kπkzk类似地,给定z一个特定的值,x的条件概率分布是一个高斯分布
p
(
x
∣
z
k
=
1
)
=
N
(
x
∣
u
k
,
Σ
k
)
,
p
(
x
∣
z
)
=
∏
k
=
1
K
N
(
x
∣
u
k
,
Σ
k
)
z
k
p(x|z_{k}=1)=N(x|u_{k},\Sigma_{k}),p(x|z)=\prod_{k=1}^{K}N(x|u_{k},\Sigma_{k})^{z_{k}}
p(x∣zk=1)=N(x∣uk,Σk),p(x∣z)=k=1∏KN(x∣uk,Σk)zkx的边缘概率分布可以通过将联合概率分布对所有可能的z求和的方式得到
p
(
x
)
=
∑
z
p
(
z
)
p
(
x
∣
z
)
=
∑
z
∏
k
=
1
K
(
π
k
N
(
x
∣
u
k
,
Σ
k
)
)
z
k
=
∑
j
=
1
K
∏
k
=
1
K
(
π
k
N
(
x
∣
u
k
,
Σ
k
)
)
I
k
j
=
∑
k
=
1
K
π
k
N
(
x
∣
u
k
,
Σ
k
)
p(x)=\sum_{z}p(z)p(x|z)=\sum_{z}\prod_{k=1}^{K}(\pi_{k}N(x|u_{k},\Sigma_{k}))^{z_{k}}=\sum_{j=1}^{K}\prod_{k=1}^{K}(\pi_{k}N(x|u_{k},\Sigma_{k}))^{I_{kj}}=\sum_{k=1}^{K}\pi_{k}N(x|u_{k},\Sigma_{k})
p(x)=z∑p(z)p(x∣z)=z∑k=1∏K(πkN(x∣uk,Σk))zk=j=1∑Kk=1∏K(πkN(x∣uk,Σk))Ikj=k=1∑KπkN(x∣uk,Σk)因此x的边缘概率分布就是高斯混合分布。另一个起着重要作用的变量是
γ
(
z
k
)
\gamma(z_{k})
γ(zk)表示的是在给定x的条件下z的条件概率
p
(
z
k
=
1
∣
x
)
p(z_{k}=1|x)
p(zk=1∣x)
γ
(
z
k
)
=
p
(
z
k
=
1
∣
x
)
=
p
(
z
k
=
1
)
p
(
x
∣
z
k
=
1
)
∑
j
=
1
K
p
(
z
j
=
1
)
p
(
x
∣
z
j
=
1
)
=
π
k
N
(
x
∣
u
k
,
Σ
k
)
∑
j
=
1
K
π
j
N
(
x
∣
u
j
,
Σ
j
)
\gamma(z_{k})=p(z_{k}=1|x)=\frac{p(z_{k}=1)p(x|z_{k}=1)}{\sum_{j=1}^{K}p(z_{j}=1)p(x|z_{j}=1)}=\frac{\pi_{k}N(x|u_{k},\Sigma_{k})}{\sum_{j=1}^{K}\pi_{j}N(x|u_{j},\Sigma_{j})}
γ(zk)=p(zk=1∣x)=∑j=1Kp(zj=1)p(x∣zj=1)p(zk=1)p(x∣zk=1)=∑j=1KπjN(x∣uj,Σj)πkN(x∣uk,Σk)类似地我们将
π
k
\pi_{k}
πk看成
z
k
=
1
z_{k}=1
zk=1的先验概率,将
γ
(
z
k
)
\gamma(z_{k})
γ(zk)看成观测到x之后,对应的后验概率。正如我们将看到的那样,
γ
(
z
k
)
\gamma(z_{k})
γ(zk)也可以看成是分量k对于解释观测值x的责任。从上面可以看到似然函数为
l
n
p
(
X
∣
π
,
u
,
Σ
)
=
∑
n
=
1
N
l
n
{
∑
k
=
1
K
π
k
N
(
x
n
∣
u
k
,
Σ
k
)
}
\mathrm{ln}p(X|\pi,u,\Sigma)=\sum_{n=1}^{N}\mathrm{ln}\left\{ \sum_{k=1}^{K}\pi_{k}N(x_{n}|u_{k},\Sigma_{k})\right\}
lnp(X∣π,u,Σ)=n=1∑Nln{k=1∑KπkN(xn∣uk,Σk)}根据以往一般的经验,我们接下来需要最大化这个似然函数。在这之前我们需要强调一下由于奇异性造成的应用于高斯混合模型的最大似然框架中的一个大问题。
假设我们有这样一个数据集
X
=
{
x
1
,
.
.
.
,
x
n
}
X=\left \{ x_{1},...,x_{n}\right \}
X={x1,...,xn}N×D的矩阵,其中第n行是
x
n
T
x_{n}^{T}
xnT。对应的隐含变量表示成N×K的矩阵Z,第n行为
z
n
T
z_{n}^{T}
znT。我们考虑这样一个高斯混合模型,它的分量协方差矩阵为
Σ
k
=
σ
k
2
I
\Sigma_{k}=\sigma_{k}^{2}I
Σk=σk2I,
I
I
I是一个单位矩阵。假设混合模型的第j个分量的均值
u
j
u_{j}
uj与某个数据点完全相同即
u
j
=
x
n
u_{j}=x_{n}
uj=xn,这样这个数据点会为似然函数贡献一项
N
(
x
n
∣
x
n
,
σ
j
2
I
)
=
1
(
2
π
)
0.5
1
σ
j
D
N(x_{n}|x_{n},\sigma_{j}^{2}I)=\frac{1}{(2\pi)^{0.5}}\frac{1}{\sigma_{j}^{D}}
N(xn∣xn,σj2I)=(2π)0.51σjD1较为致命的是一旦
σ
j
→
0
\sigma_{j}\rightarrow0
σj→0,那么这一项将会趋于无穷大,因此对数似然函数也会趋向于无穷大。
因此,对数似然函数的最大化不是一个具有良好定义的问题,因为这种奇异性总会出现,会发生在任何一个“退化”到一个具体的数据点上的高斯分量上。而这个问题为什么不会在单一的高斯分布中出现呢,我们注意到如果单一的高斯分布退化到一个数据点上,那么它总会给其他数据点产生的似然函数贡献可乘的因子,这些因子会以指数的速度趋向于零,从而使得整体的似然函数趋向于零而不是无穷大。然而,一旦我们混合概率分布中存在两个分量,其中一个分量会具有有限的方差,因此对所有的数据点都会赋予一个有限的概率值,而另一个分量会收缩到一个具体的数据点,因此会给对数似然函数贡献一个不断增加的值。更一般的,我们可以把这种奇异性当做是最大似然方法中不可避免的过拟合现象。可以参照下图理解,右边的对应着即其中一种分量会收缩到一个具体的数据点,这样会形成一种病态解。

而运用贝叶斯的方法能有效地解决过拟合问题即能解决这种奇异困难。而一般的方法是如果检测到某种分量收缩到一个点时,我们就重新随机设置它的均值,并且将它的方差设置为某个较大的值,再继续优化。
不仅如此,寻找最大似然解还存在另外一种问题,我们想象得到K个高斯分量混合而成的概率分布总共存在K!种等价的解,因为任意交换其中两种分量的解还是会得到和未交换前一样的效果。
总的来说最大化高斯混合模型的对数似然函数很复杂,从公式上体现在求和项出现在对数计算中,所以不会像单一的高斯分布那么好求解。如果我们令其导数为0,也无法得到一个解析解。
一种优雅的并且强大的寻找带有潜在变量的模型的最大似然解的方法被称为期望最大化(EM)
首先我们先使得似然函数关于高斯分量的均值
u
k
u_{k}
uk的导数等于零即
∂
l
n
p
∂
u
k
=
0
→
∑
n
=
1
N
π
k
N
(
x
n
∣
u
k
,
Σ
k
)
∑
j
π
j
N
(
x
n
∣
u
j
,
Σ
j
)
Σ
k
−
1
(
x
n
−
u
k
)
=
0
\frac{\partial \mathrm{ln}p}{\partial u_{k}}=0\rightarrow\sum_{n=1}^{N}\frac{\pi_{k}N(x_{n}|u_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|u_{j},\Sigma_{j})}\Sigma_{k}^{-1}(x_{n}-u_{k})=0
∂uk∂lnp=0→n=1∑N∑jπjN(xn∣uj,Σj)πkN(xn∣uk,Σk)Σk−1(xn−uk)=0其中
N
(
x
n
∣
u
k
,
Σ
k
)
=
1
(
2
π
)
D
2
1
∣
Σ
k
∣
0.5
e
x
p
{
−
1
2
(
x
−
u
)
T
Σ
−
1
(
x
−
u
)
}
N(x_{n}|u_{k},\Sigma_{k})=\frac{1}{(2\pi)^{\frac{D}{2}}}\frac{1}{|\Sigma_{k}|^{0.5}}exp\left\{ -\frac{1}{2}(x-u)^{T}\Sigma^{-1}(x-u) \right\}
N(xn∣uk,Σk)=(2π)2D1∣Σk∣0.51exp{−21(x−u)TΣ−1(x−u)}
π
k
N
(
x
n
∣
u
k
,
Σ
k
)
∑
j
π
j
N
(
x
n
∣
u
j
,
Σ
j
)
=
γ
(
z
n
k
)
\frac{\pi_{k}N(x_{n}|u_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|u_{j},\Sigma_{j})}=\gamma(z_{nk})
∑jπjN(xn∣uj,Σj)πkN(xn∣uk,Σk)=γ(znk)
∑
n
=
1
N
γ
(
z
n
k
)
Σ
k
−
1
(
x
n
−
u
k
)
=
0
→
u
k
=
1
N
k
∑
n
=
1
N
γ
(
z
n
k
)
x
n
\sum_{n=1}^{N}\gamma(z_{nk})\Sigma_{k}^{-1}(x_{n}-u_{k})=0\rightarrow u_{k}=\frac{1}{N_{k}}\sum_{n=1}^{N}\gamma(z_{nk})x_{n}
n=1∑Nγ(znk)Σk−1(xn−uk)=0→uk=Nk1n=1∑Nγ(znk)xn
N
k
=
∑
n
=
1
N
γ
(
z
n
k
)
N_{k}=\sum_{n=1}^{N}\gamma(z_{nk})
Nk=n=1∑Nγ(znk)
我们可以将
N
k
N_{k}
Nk看作是分配到聚类k的数据点的有效数量。均值
u
k
u_{k}
uk通过对数据集里所有的数据点求加权平均的方式得到,其中
x
n
x_{n}
xn的权因子由后验概率
γ
(
z
n
k
)
\gamma(z_{nk})
γ(znk)给出。可以与单一高斯分布的最大似然估计进行对比
u
M
L
=
1
N
∑
n
=
1
N
x
n
u_{ML}=\frac{1}{N}\sum_{n=1}^{N}x_{n}
uML=N1n=1∑Nxn
Σ
M
L
=
1
N
∑
n
=
1
N
(
x
n
−
u
M
L
)
(
x
n
−
u
M
L
)
T
\Sigma_{ML}=\frac{1}{N}\sum_{n=1}^{N}(x_{n}-u_{ML})(x_{n}-u_{ML})^{T}
ΣML=N1n=1∑N(xn−uML)(xn−uML)T
类似地我们先使得似然函数关于高斯分量的协方差矩阵
Σ
k
\Sigma_{k}
Σk的导数等于零
Σ
k
=
1
N
k
∑
n
=
1
N
γ
(
z
n
k
)
(
x
n
−
u
k
)
(
x
n
−
u
k
)
T
\Sigma_{k}=\frac{1}{N_{k}}\sum_{n=1}^{N}\gamma(z_{nk})(x_{n}-u_{k})(x_{n}-u_{k})^{T}
Σk=Nk1n=1∑Nγ(znk)(xn−uk)(xn−uk)T
最后我们对混合系数
π
k
\pi_{k}
πk求导数,同时要考虑它的限制条件
∑
k
=
1
K
π
k
=
1
\sum_{k=1}^{K}\pi_{k}=1
∑k=1Kπk=1,我们使用拉格朗日乘数法,最大化下面这个函数
L
=
l
n
p
(
X
∣
π
,
u
,
Σ
)
+
λ
(
∑
k
=
1
K
π
k
−
1
)
L=\mathrm{ln}p(X|\pi,u,\Sigma)+\lambda(\sum_{k=1}^{K}\pi_{k}-1)
L=lnp(X∣π,u,Σ)+λ(k=1∑Kπk−1)
∂
L
∂
π
k
=
0
→
∑
n
=
1
N
N
(
x
n
∣
u
k
,
Σ
k
)
∑
j
π
j
N
(
x
n
∣
u
j
,
Σ
j
)
+
λ
=
0
\frac{\partial L}{\partial \pi_{k}}=0 \rightarrow \sum_{n=1}^{N}\frac{N(x_{n}|u_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|u_{j},\Sigma_{j})}+\lambda=0
∂πk∂L=0→n=1∑N∑jπjN(xn∣uj,Σj)N(xn∣uk,Σk)+λ=0
∑
n
=
1
N
π
k
N
(
x
n
∣
u
k
,
Σ
k
)
∑
j
π
j
N
(
x
n
∣
u
j
,
Σ
j
)
=
−
λ
π
k
→
∑
n
=
1
N
∑
k
π
k
N
(
x
n
∣
u
k
,
Σ
k
)
∑
j
π
j
N
(
x
n
∣
u
j
,
Σ
j
)
=
−
λ
∑
j
π
k
→
λ
=
−
N
\sum_{n=1}^{N}\frac{\pi_{k}N(x_{n}|u_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|u_{j},\Sigma_{j})}=-\lambda\pi_{k}\rightarrow \sum_{n=1}^{N}\frac{\sum_{k}\pi_{k}N(x_{n}|u_{k},\Sigma_{k})}{\sum_{j}\pi_{j}N(x_{n}|u_{j},\Sigma_{j})}=-\lambda\sum_{j}\pi_{k}\rightarrow \lambda=-N
n=1∑N∑jπjN(xn∣uj,Σj)πkN(xn∣uk,Σk)=−λπk→n=1∑N∑jπjN(xn∣uj,Σj)∑kπkN(xn∣uk,Σk)=−λj∑πk→λ=−N我们最后会得到
π
k
=
N
k
N
\pi_{k}=\frac{N_{k}}{N}
πk=NNk 从而第k个分量的混合系数是那个分量对于解释数据点的“责任”的平均值。
我们可以看到上述这三个参数
u
k
u_{k}
uk,
Σ
k
\Sigma_{k}
Σk,
π
k
\pi_{k}
πk并没有给出一个解析解,因为责任
γ
(
z
n
k
)
\gamma(z_{nk})
γ(znk)也依赖于这些参数。那么知道了
γ
(
z
n
k
)
\gamma(z_{nk})
γ(znk)不就能求出这三个参数了吗。所以我们能使用一种简单的迭代方法来寻找问题的最大似然解。而这个迭代过程就是EM算法应用于高斯混合模型的一个实例。我们先为这三个参数设置一个初始值,然后用上面得到的关系式进行交替更新,被称为E步骤和M步骤。每次进行E步骤和接下来的M步骤都保证了对数似然函数的增大。实际应用中,当对数似然函数的变化量或者参数的变化量低于阈值时,我们就认为算法收敛。通常运行K均值算法找到高斯混合模型的一个合适的初始值,接下来使用EM算法进行调节。协方差矩阵通过K均值算法找到的聚类样本协方差得到,混合系数可以设置为分配到对应类别中的数据点所占比例。算法必须避免似然函数带来的奇异性,即高斯分量退化到一个具体的数据点,并且一般情况下对数似然函数会有多个局部极大值,EM并不能保证找到其中最大的一个。
给定一个高斯混合模型,目标是关于参数(均值,协方差,混合系数)最大化似然函数
- 初始化均值 u k u_{k} uk,协方差 Σ k \Sigma_{k} Σk,混合系数 π k \pi_{k} πk,计算对数似然函数的初始值
- E步骤,使用当前参数计算“责任” γ ( z n k ) = π k N ( x n ∣ u k , Σ k ) ∑ j = 1 K π j N ( x n ∣ u j , Σ j ) \gamma(z_{nk})=\frac{\pi_{k}N(x_{n}|u_{k},\Sigma_{k})}{\sum_{j=1}^{K}\pi_{j}N(x_{n}|u_{j},\Sigma_{j})} γ(znk)=∑j=1KπjN(xn∣uj,Σj)πkN(xn∣uk,Σk)
- M步骤,使用当前的责任更新估计参数
u
k
n
e
w
=
1
N
k
∑
n
=
1
N
γ
(
z
n
k
)
x
n
u_{k}^{new}=\frac{1}{N_{k}}\sum_{n=1}^{N}\gamma(z_{nk})x_{n}
uknew=Nk1n=1∑Nγ(znk)xn
Σ
k
n
e
w
=
1
N
k
∑
n
=
1
N
γ
(
z
n
k
)
(
x
n
−
u
k
n
e
w
)
(
x
n
−
u
k
n
e
w
)
T
\Sigma_{k}^{new}=\frac{1}{N_{k}}\sum_{n=1}^{N}\gamma(z_{nk})(x_{n}-u_{k}^{new})(x_{n}-u_{k}^{new})^{T}
Σknew=Nk1n=1∑Nγ(znk)(xn−uknew)(xn−uknew)T
π
k
n
e
w
=
N
k
N
,
N
k
=
∑
n
=
1
N
γ
(
z
n
k
)
\pi_{k}^{new}=\frac{N_{k}}{N},N_{k}=\sum_{n=1}^{N}\gamma(z_{nk})
πknew=NNk,Nk=n=1∑Nγ(znk)
-计算对数似然函数,看似然函数和参数的变化量是否收敛,没有收敛的话继续进行E步骤和M步骤。 l n p ( X ∣ π , u , Σ ) = ∑ n = 1 N l n { ∑ k = 1 K π k N ( x n ∣ u k , Σ k ) } \mathrm{ln}p(X|\pi,u,\Sigma)=\sum_{n=1}^{N}\mathrm{ln}\left\{ \sum_{k=1}^{K}\pi_{k}N(x_{n}|u_{k},\Sigma_{k})\right\} lnp(X∣π,u,Σ)=n=1∑Nln{k=1∑KπkN(xn∣uk,Σk)}
更一般的EM算法推导如下:
假设我们有n个样本数据 X = { x 1 , . . . , x n } X=\left \{ x_{1},...,x_{n}\right \} X={x1,...,xn},找出样本的模型参数 θ \theta θ极大化模型分布的对数似然函数 θ = a r g m a x θ ∑ i = 1 n l o g P ( x i ; θ ) \theta=arg\underset{\theta}{max}\sum_{i=1}^{n}logP(x_{i};\theta) θ=argθmaxi=1∑nlogP(xi;θ)如果我们有未观测到的隐含数据 Z = { z 1 , . . . , z n } Z=\left \{ z_{1},...,z_{n}\right \} Z={z1,...,zn},那么相应的对数似然函数如下 θ = a r g m a x θ ∑ i = 1 n l o g ∑ z i = 1 n P ( x i , z i ; θ ) \theta=arg\underset{\theta}{max}\sum_{i=1}^{n}log \sum_{z_{i}=1}^{n}P(x_{i},z_{i};\theta) θ=argθmaxi=1∑nlogzi=1∑nP(xi,zi;θ)由于无法直接求解上式,我们需要一种特殊的方法,由于是求的最大值,所以我们可以舍弃一些模型较小的值,所以可以先求出下界 ∑ i = 1 n l o g ∑ z i = 1 n P ( x i , z i ; θ ) = ∑ i = 1 n l o g ∑ z i = 1 n Q i ( z i ) P ( x i , z i ; θ ) Q i ( z i ) ≥ ∑ i = 1 n ∑ z i = 1 n Q i ( z i ) l o g P ( x i , z i ; θ ) Q i ( z i ) \sum_{i=1}^{n}log \sum_{z_{i}=1}^{n}P(x_{i},z_{i};\theta)=\sum_{i=1}^{n}log \sum_{z_{i}=1}^{n}Q_{i}(z_{i})\frac{P(x_{i},z_{i};\theta)}{Q_{i}(z_{i})}\geq\sum_{i=1}^{n} \sum_{z_{i}=1}^{n}Q_{i}(z_{i})log\frac{P(x_{i},z_{i};\theta)}{Q_{i}(z_{i})} i=1∑nlogzi=1∑nP(xi,zi;θ)=i=1∑nlogzi=1∑nQi(zi)Qi(zi)P(xi,zi;θ)≥i=1∑nzi=1∑nQi(zi)logQi(zi)P(xi,zi;θ)这里用了引入了一个新的分布Q,并且用了Jessen不等式求下界,满足等号的情况如下 P ( x i , z i ; θ ) Q i ( z i ) = c , c = 常 数 \frac{P(x_{i},z_{i};\theta)}{Q_{i}(z_{i})}=c,c=常数 Qi(zi)P(xi,zi;θ)=c,c=常数因为Q是一个分布那么很自然地想到 ∑ z i Q i ( z i ) = 1 → ∑ z i P ( x i , z i ; θ ) = c ∑ z i Q i ( z i ) = c \sum _{z_{i}}Q_{i}(z_{i})=1\rightarrow \sum _{z_{i}}P(x_{i},z_{i};\theta)=c\sum _{z_{i}}Q_{i}(z_{i})=c zi∑Qi(zi)=1→zi∑P(xi,zi;θ)=czi∑Qi(zi)=c Q i ( z i ) = P ( x i , z i ; θ ) c = P ( x i , z i ; θ ) ∑ z i P ( x i , z i ; θ ) = P ( x i , z i ; θ ) P ( x i ; θ ) = P ( z i ∣ x i ; θ ) Q_{i}(z_{i})=\frac{P(x_{i},z_{i};\theta)}{c}=\frac{P(x_{i},z_{i};\theta)}{\sum _{z_{i}}P(x_{i},z_{i};\theta)}=\frac{P(x_{i},z_{i};\theta)}{P(x_{i};\theta)}=P(z_{i}|x_{i};\theta) Qi(zi)=cP(xi,zi;θ)=∑ziP(xi,zi;θ)P(xi,zi;θ)=P(xi;θ)P(xi,zi;θ)=P(zi∣xi;θ)此时我们只需要优化 a r g m a x θ ∑ i = 1 n ∑ z i = 1 n Q i ( z i ) l o g P ( x i , z i ; θ ) , 其 中 Q i ( z i ) = P ( z i ∣ x i ; θ ) arg\underset{\theta}{max}\sum_{i=1}^{n}\sum_{z_{i}=1}^{n}Q_{i}(z_{i})logP(x_{i},z_{i};\theta),\quad 其中Q_{i}(z_{i})=P(z_{i}|x_{i};\theta) argθmaxi=1∑nzi=1∑nQi(zi)logP(xi,zi;θ),其中Qi(zi)=P(zi∣xi;θ)上式的前半部分求最大化就是M步骤,E部分就是 先 求 条 件 概 率 分 布 Q i ( z i ) = P ( z i ∣ x i ; θ ) 先求条件概率分布Q_{i}(z_{i})=P(z_{i}|x_{i};\theta) 先求条件概率分布Qi(zi)=P(zi∣xi;θ) 再 求 损 失 函 数 L ( θ ) = ∑ i = 1 n ∑ z i = 1 n Q i ( z i ) l o g P ( x i , z i ; θ ) 再求损失函数L(\theta)=\sum_{i=1}^{n}\sum_{z_{i}=1}^{n}Q_{i}(z_{i})logP(x_{i},z_{i};\theta) 再求损失函数L(θ)=i=1∑nzi=1∑nQi(zi)logP(xi,zi;θ)其中 ∑ z i = 1 n Q i ( z i ) l o g P ( x i , z i ; θ ) \sum_{z_{i}=1}^{n}Q_{i}(z_{i})logP(x_{i},z_{i};\theta) ∑zi=1nQi(zi)logP(xi,zi;θ)可以理解成 l o g P ( x i , z i ; θ ) logP(x_{i},z_{i};\theta) logP(xi,zi;θ)基于条件概率分布 Q i ( z i ) Q_{i}(z_{i}) Qi(zi)的期望。
来个实际例题试试2008年的文章What is the expectation maximization algorithm?
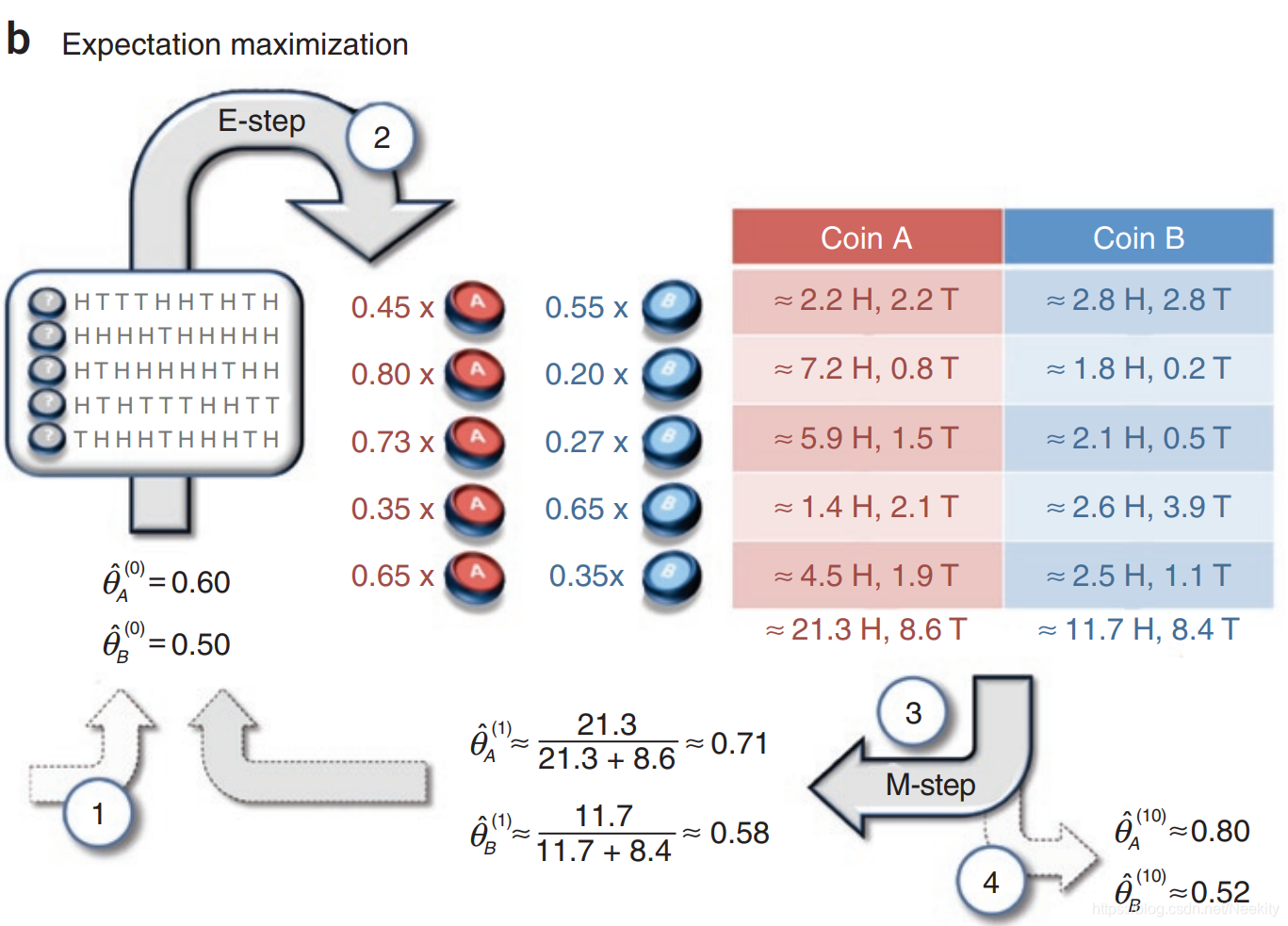

可以看到结果基本相似。














 3974
3974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









