






- YOLOv3理论篇
- YOLOv3实践篇
工程框架:
本文基于YOLOv3大体结构进行实现,采用VOC2028数据集进行测试,一份安全帽和人两个类别的检测数据集,数据总共7581帧图片。工程框架结构如下图所示:
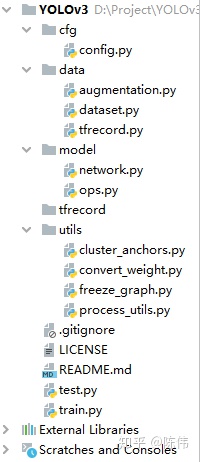
config作为参数文件用于保存训练参数、测试参数、模型参数、路径参数等信息;
data文件夹下保存数据处理相关文件,包括用于数据增广的augmentation.py,用于TFRecord制作和读取的tfrecord.py,图像预处理和真值编码的dataset.py;
model文件夹下保存和网络模型相关文件,包括模型搭建的network.py,子操作实现的ops.py;
utils文件夹下保存周边计算相关文件,包括数据文本操作、anchor生成、权重转换、图结构冻结、网络后处理等文件;
train/test分别是训练代码和预测代码;
数据相关:
本次实例的数据加载方式仍然采用tfrecord结构进行队列读取,create_tfrecord函数将图片和标签信息编码成tfrecord文件,其中为了保证每张图片标签在解码时尺寸唯一,在制作数据文件时,每张图片中bbox个数不足300的用0补齐,详细代码如下:
def create_tfrecord(self):
# 获取作为训练验证集的图片序列
trainval_path = os.path.join(self.data_path, 'ImageSets', 'Main', 'trainval.txt')
tf_file = os.path.join(self.tfrecord_dir, self.train_tfrecord_name)
if os.path.exists(tf_file):
os.remove(tf_file)
writer = tf.python_io.TFRecordWriter(tf_file)
with open(trainval_path, 'r') as read:
lines = read.readlines()
for line in lines:
num = line[0:-1]
image = self.dataset.load_image(num)
image_shape = image.shape
boxes = self.dataset.load_label(num)
if len(boxes) == 0:
continue
while len(boxes) < 300:
boxes = np.append(boxes, [[0.0, 0.0, 0.0, 0.0, 0.0]], axis=0)
boxes = np.array(boxes, dtype=np.float32)
image_string = image.tobytes()
boxes_string = boxes.tobytes()
example = tf.train.Example(features=tf.train.Features(
feature={
'image': tf.train.Feature(bytes_list=tf.train.BytesList(value=[image_string])),
'bbox': tf.train.Feature(bytes_list=tf.train.BytesList(value=[boxes_string])),
'height': tf.train.Feature(int64_list=tf.train.Int64List(value=[image_shape[0]])),
'width': tf.train.Feature(int64_list=tf.train.Int64List(value=[image_shape[1]])),
}))
writer.write(example.SerializeToString())
writer.close()
print('Finish trainval.tfrecord Done')
def parse_single_example(self, serialized_example):
"""
:param serialized_example:待解析的serialized_example文件
:return: 从文件中解析出的单个样本的相关特征,image, y_true_13, y_true_26, y_true_52
"""
features = tf.parse_single_example(
serialized_example,
features={
'image': tf.FixedLenFeature([], tf.string),
'bbox': tf.FixedLenFeature([], tf.string),
'height': tf.FixedLenFeature([], tf.int64),
'width': tf.FixedLenFeature([], tf.int64)
})
tf_image = tf.decode_raw(features['image'], tf.uint8)
tf_bbox = tf.decode_raw(features['bbox'], tf.float32)
tf_height = features['height']
tf_width = features['width']
# 转换为网络输入所要求的形状
tf_image = tf.reshape(tf_image, [tf_height, tf_width, 3])
tf_label = tf.reshape(tf_bbox, [150, 5])
# preprocess
tf_image, y_true_13, y_true_26, y_true_52 = tf.py_func(self.dataset.preprocess_data, inp=[tf_image, tf_label, self.input_height, self.input_width], Tout=[tf.float32, tf.float32, tf.float32, tf.float32])
return tf_image, y_true_13, y_true_26, y_true_52
def create_dataset(self, filenames, batch_num, batch_size=1, is_shuffle=False):
"""
:param filenames: record file names
:param batch_size: batch size
:param is_shuffle: whether shuffle
:param n_repeats: number of repeats
:return:
"""
dataset = tf.data.TFRecordDataset(filenames)
dataset = dataset.map(self.parse_single_example, num_parallel_calls=8)
if is_shuffle:
dataset = dataset.shuffle(batch_num)
dataset = dataset.batch(batch_size)
dataset = dataset.repeat()
dataset = dataset.prefetch(batch_size)
return dataset对tfrecord格式的文件解码时,首先在preprocess_data函数中进行随机数据增广,包括水平翻转,裁剪,平移,颜色抖动等;再去除无效框增加处理速度;最后在preprocess_true_boxes函数中将每个标签尺寸形如[num,5]转换成训练真值[feature_height, feature_width, per_anchor_num, 5 + num_classes],详细代码如下:
def preprocess_data(self, image, boxes, input_height, input_width):
image = np.array(image)
#image, boxes = random_horizontal_flip(image, boxes)
#image, boxes = random_crop(image, boxes)
#image, boxes = random_translate(image, boxes)
#image = random_color_distort(image)
image, boxes = letterbox_resize(image, (input_height, input_width), np.copy(boxes), interp=0)
image_rgb = cv2.cvtColor(np.copy(image), cv2.COLOR_BGR2RGB).astype(np.float32)
image_norm = image_rgb / 255.
# boxes 去除空标签
valid = (np.sum(boxes, axis=-1) > 0).tolist()
boxes = boxes[valid]
y_true_13, y_true_26, y_true_52 = self.preprocess_true_boxes(boxes, input_height, input_width, self.anchors, self.class_num)
return image_norm, y_true_13, y_true_26, y_true_52
def preprocess_true_boxes(self, labels, input_height, input_width, anchors, num_classes):
"""
preprocess true boxes to train input format
:param labels: numpy.ndarray of shape [num, 5]
shape[0]: the number of labels in each image.
shape[1]: x_min, y_min, x_max, y_max, class_index
:param input_height: the shape of input image height
:param input_width: the shape of input image width
:param anchors: array, shape=[9, 2]
shape[0]: the number of anchors
shape[1]: width, height
:param num_classes: the number of class
:return: y_true_13, y_true_26, y_true_52 shape is [feature_height, feature_width, per_anchor_num, 5 + num_classes]
"""
input_shape = np.array([input_height, input_width], dtype=np.int32)
num_layers = len(anchors) // 3
anchors = np.array(anchors)
anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
feature_map_sizes = [input_shape // 32, input_shape // 16, input_shape // 8]
y_true_13 = np.zeros(shape=[feature_map_sizes[0][0], feature_map_sizes[0][1], 3, 5 + num_classes], dtype=np.float32)
y_true_26 = np.zeros(shape=[feature_map_sizes[1][0], feature_map_sizes[1][1], 3, 5 + num_classes], dtype=np.float32)
y_true_52 = np.zeros(shape=[feature_map_sizes[2][0], feature_map_sizes[2][1], 3, 5 + num_classes], dtype=np.float32)
y_true = [y_true_13, y_true_26, y_true_52]
# convert boxes from (min_x, min_y, max_x, max_y) to (x, y, w, h)
boxes_xy = (labels[:, 0:2] + labels[:, 2:4]) / 2
boxes_wh = labels[:, 2:4] - labels[:, 0:2]
true_boxes = np.concatenate([boxes_xy, boxes_wh], axis=-1)
# [N, 1, 2]
valid_mask = boxes_wh[:, 0] > 0
wh = boxes_wh[valid_mask]
wh = np.expand_dims(wh, 1)
boxes_max = wh / 2.
boxes_min = - wh / 2.
anchors_max = anchors / 2.
anchors_min = - anchors / 2.
# [N, 1, 2] & [9, 2] ==> [N, 9, 2]
intersect_mins = np.maximum(boxes_min, anchors_min)
intersect_maxs = np.minimum(boxes_max, anchors_max)
# [N, 9, 2]
intersect_wh = np.maximum(intersect_maxs - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
box_area = wh[..., 0] * wh[..., 1]
anchor_area = anchors[:, 0] * anchors[:, 1]
# [N, 9]
iou = intersect_area / (box_area + anchor_area - intersect_area + 1e-10)
# Find best anchor for each true box [N]
best_anchor = np.argmax(iou, axis=1)
ratio_dict = {1.: 8., 2.: 16., 3.: 32.}
for n, idx in enumerate(best_anchor):
# idx: 0,1,2 ==> 2; 3,4,5 ==> 1; 6,7,8 ==> 0
feature_map_group = 2 - idx // 3
# scale ratio: 0,1,2 ==> 8; 3,4,5 ==> 16; 6,7,8 ==> 32
ratio = ratio_dict[np.ceil((idx + 1) / 3.)]
i = int(np.floor(true_boxes[n, 0] / ratio))
j = int(np.floor(true_boxes[n, 1] / ratio))
k = anchor_mask[feature_map_group].index(idx)
c = labels[n][4].astype('int32')
#print(feature_map_group, '|', j, i, k, c, n, idx, true_boxes[n, 0], true_boxes[n, 1], ratio)
y_true[feature_map_group][j, i, k, 0:4] = true_boxes[n, 0:4]
y_true[feature_map_group][j, i, k, 4] = 1
y_true[feature_map_group][j, i, k, 5 + c] = 1
return y_true_13, y_true_26, y_true_52下面是一些常规数据增广的代码:
def random_horizontal_flip(image, bboxes):
"""
Randomly horizontal flip the image and correct the box
:param image: BGR image data shape is [height, width, channel]
:param bboxes: bounding box shape is [num, 4]
:return: result
"""
if random.random() < 0.5:
_, w, _ = image.shape
image = image[:, ::-1, :]
bboxes[:, [0, 2]] = w - bboxes[:, [2, 0]]
return image, bboxes
def random_vertical_flip(image, bboxes):
"""
Randomly vertical flip the image and correct the box
:param image: BGR image data shape is [height, width, channel]
:param bboxes: bounding box shape is [num, 4]
:return: result
"""
if random.random() < 0.5:
h, _, _ = image.shape
image = image[::-1, :, :]
bboxes[:, [1, 3]] = h - bboxes[:, [3, 1]]
return image, bboxes
def random_expand(image, bboxes, max_ratio=3, fill=0, keep_ratio=True):
"""
Random expand original image with borders, this is identical to placing
the original image on a larger canvas.
:param image: BGR image data shape is [height, width, channel]
:param bboxes: bounding box shape is [num, 4]
:param max_ratio: Maximum ratio of the output image on both direction(vertical and horizontal)
:param fill: The value(s) for padded borders.
:param keep_ratio: If `True`, will keep output image the same aspect ratio as input.
:return: result
"""
h, w, c = image.shape
ratio_x = random.uniform(1, max_ratio)
if keep_ratio:
ratio_y = ratio_x
else:
ratio_y = random.uniform(1, max_ratio)
oh, ow = int(h * ratio_y), int(w * ratio_x)
off_y = random.randint(0, oh - h)
off_x = random.randint(0, ow - w)
dst = np.full(shape=(oh, ow, c), fill_value=fill, dtype=image.dtype)
dst[off_y:off_y + h, off_x:off_x + w, :] = image
# correct bbox
bboxes[:, :2] += (off_x, off_y)
bboxes[:, 2:4] += (off_x, off_y)
return dst, bboxes
def letterbox_resize(image, target_size, bboxes=None, interp=0):
"""
Resize the image and correct the bbox accordingly.
:param image: BGR image data shape is [height, width, channel]
:param bboxes: bounding box shape is [num, 4]
:param target_size: input size
:param interp:
:return: result
"""
origin_height, origin_width = image.shape[:2]
input_height, input_width = target_size
resize_ratio = min(input_width / origin_width, input_height / origin_height)
resize_width = int(resize_ratio * origin_width)
resize_height = int(resize_ratio * origin_height)
image_resized = cv2.resize(image, (resize_width, resize_height), interpolation=interp)
image_padded = np.full((input_height, input_width, 3), 128.0, dtype=np.float32)
dw = int((input_width - resize_width) / 2)
dh = int((input_height - resize_height) / 2)
image_padded[dh:resize_height + dh, dw:resize_width + dw, :] = image_resized
if bboxes is None:
return image_padded
else:
# xmin, xmax, ymin, ymax
bboxes[:, [0, 2]] = bboxes[:, [0, 2]] * resize_ratio + dw
bboxes[:, [1, 3]] = bboxes[:, [1, 3]] * resize_ratio + dh
return image_padded, bboxes
def random_color_distort(image, brightness=32, hue=18, saturation=0.5, value=0.5):
"""
randomly distort image color include brightness, hue, saturation, value.
:param image: BGR image data shape is [height, width, channel]
:param brightness:
:param hue:
:param saturation:
:param value:
:return: result
"""
def random_hue(image_hsv, hue):
if random.random() < 0.5:
hue_delta = np.random.randint(-hue, hue)
image_hsv[:, :, 0] = (image_hsv[:, :, 0] + hue_delta) % 180
return image_hsv
def random_saturation(image_hsv, saturation):
if random.random() < 0.5:
saturation_mult = 1 + np.random.uniform(-saturation, saturation)
image_hsv[:, :, 1] *= saturation_mult
return image_hsv
def random_value(image_hsv, value):
if random.random() < 0.5:
value_mult = 1 + np.random.uniform(-value, value)
image_hsv[:, :, 2] *= value_mult
return image_hsv
def random_brightness(image, brightness):
if random.random() < 0.5:
image = image.astype(np.float32)
brightness_delta = int(np.random.uniform(-brightness, brightness))
image = image + brightness_delta
return np.clip(image, 0, 255)
# brightness
image = random_brightness(image, brightness)
image = image.astype(np.uint8)
# color jitter
image_hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV).astype(np.float32)
if np.random.randint(0, 2):
image_hsv = random_value(image_hsv, value)
image_hsv = random_saturation(image_hsv, saturation)
image_hsv = random_hue(image_hsv, hue)
else:
image_hsv = random_saturation(image_hsv, saturation)
image_hsv = random_hue(image_hsv, hue)
image_hsv = random_value(image_hsv, value)
image_hsv = np.clip(image_hsv, 0, 255)
image = cv2.cvtColor(image_hsv.astype(np.uint8), cv2.COLOR_HSV2BGR)
return image
def mix_up(image_1, image_2, bbox_1, bbox_2):
"""
Overlay images and tags
:param image_1: BGR image_1 data shape is [height, width, channel]
:param image_2: BGR image_2 data shape is [height, width, channel]
:param bbox_1: bounding box_1 shape is [num, 4]
:param bbox_2: bounding box_2 shape is [num, 4]
:return:
"""
height = max(image_1.shape[0], image_2.shape[0])
width = max(image_1.shape[1], image_2.shape[1])
mix_image = np.zeros(shape=(height, width, 3), dtype='float32')
rand_num = np.random.beta(1.5, 1.5)
rand_num = max(0, min(1, rand_num))
mix_image[:image_1.shape[0], :image_1.shape[1], :] = image_1.astype('float32') * rand_num
mix_image[:image_2.shape[0], :image_2.shape[1], :] += image_2.astype('float32') * (1. - rand_num)
mix_image = mix_image.astype('uint8')
# the last element of the 2nd dimention is the mix up weight
bbox_1 = np.concatenate((bbox_1, np.full(shape=(bbox_1.shape[0], 1), fill_value=rand_num)), axis=-1)
bbox_2 = np.concatenate((bbox_2, np.full(shape=(bbox_2.shape[0], 1), fill_value=1. - rand_num)), axis=-1)
mix_bbox = np.concatenate((bbox_1, bbox_2), axis=0)
mix_bbox = mix_bbox.astype(np.int32)
return mix_image, mix_bbox
def random_crop(image, bboxes):
if random.random() < 0.5:
h, w, _ = image.shape
max_bbox = np.concatenate([np.min(bboxes[:, 0:2], axis=0), np.max(bboxes[:, 2:4], axis=0)], axis=-1)
max_l_trans = max_bbox[0]
max_u_trans = max_bbox[1]
max_r_trans = w - max_bbox[2]
max_d_trans = h - max_bbox[3]
crop_xmin = max(0, int(max_bbox[0] - random.uniform(0, max_l_trans)))
crop_ymin = max(0, int(max_bbox[1] - random.uniform(0, max_u_trans)))
crop_xmax = max(w, int(max_bbox[2] + random.uniform(0, max_r_trans)))
crop_ymax = max(h, int(max_bbox[3] + random.uniform(0, max_d_trans)))
image = image[crop_ymin: crop_ymax, crop_xmin: crop_xmax]
bboxes[:, [0, 2]] = bboxes[:, [0, 2]] - crop_xmin
bboxes[:, [1, 3]] = bboxes[:, [1, 3]] - crop_ymin
return image, bboxes
def random_translate(image, bboxes):
"""
translation image and bboxes
:param image: BGR image data shape is [height, width, channel]
:param bbox: bounding box_1 shape is [num, 4]
:return: result
"""
if random.random() < 0.5:
h, w, _ = image.shape
max_bbox = np.concatenate([np.min(bboxes[:, 0:2], axis=0), np.max(bboxes[:, 2:4], axis=0)], axis=-1)
max_l_trans = max_bbox[0]
max_u_trans = max_bbox[1]
max_r_trans = w - max_bbox[2]
max_d_trans = h - max_bbox[3]
tx = random.uniform(-(max_l_trans - 1), (max_r_trans - 1))
ty = random.uniform(-(max_u_trans - 1), (max_d_trans - 1))
M = np.array([[1, 0, tx], [0, 1, ty]])
image = cv2.warpAffine(image, M, (w, h))
bboxes[:, [0, 2]] = bboxes[:, [0, 2]] + tx
bboxes[:, [1, 3]] = bboxes[:, [1, 3]] + ty
return image, bboxes网络模型:
YOLOv3网络结构分为三块,Backbone特征提取模块采用darknet53网络;Neck特征增强模块采用FPN结构;Head检测头部分在三个不同尺度的特征图上卷积直接回归位置信息和置信度信息、类别信息。其中堆叠residual_block以降低深层网络t梯度回传弥散问题,输出层通道数为3 * (self.class_num + 5),3表示每张特征图含有3个不同长宽比的anchor,5表示(x,y,w,h,confidence):
def darknet53(self, inputs):
"""
定义网络特征提取层
:param inputs:待输入的样本图片
:return: 三个不同尺度的基础特征图输出
"""
net = conv2d(inputs, 32, 3, strides=1)
net = conv2d(net, 64, 3, strides=2)
for i in range(1):
net = residual_block(net, 32)
net = conv2d(net, 128, 3, strides=2)
for i in range(2):
net = residual_block(net, 64)
net = conv2d(net, 256, 3, strides=2)
for i in range(8):
net = residual_block(net, 128)
route_1 = net
net = conv2d(net, 512, 3, strides=2)
for i in range(8):
net = residual_block(net, 256)
route_2 = net
net = conv2d(net, 1024, 3, strides=2)
for i in range(4):
net = residual_block(net, 512)
route_3 = net
return route_1, route_2, route_3
def detect_head(self, route_1, route_2, route_3):
input_data = conv2d(route_3, 512, 1)
input_data = conv2d(input_data, 1024, 3)
input_data = conv2d(input_data, 512, 1)
input_data = conv2d(input_data, 1024, 3)
input_data = conv2d(input_data, 512, 1)
conv_lobj_branch = conv2d(input_data, 1024, 3)
conv_lbbox = slim.conv2d(conv_lobj_branch, 3 * (self.class_num + 5), 1, stride=1, normalizer_fn=None, activation_fn=None, biases_initializer=tf.zeros_initializer())
conv_lbbox = tf.identity(conv_lbbox, name='conv_lbbox')
input_data = conv2d(input_data, 256, 1)
input_data = upsample(input_data, method=self.upsample_method)
input_data = tf.concat([input_data, route_2], axis=-1)
input_data = conv2d(input_data, 256, 1)
input_data = conv2d(input_data, 512, 3)
input_data = conv2d(input_data, 256, 1)
input_data = conv2d(input_data, 512, 3)
input_data = conv2d(input_data, 256, 1)
conv_mobj_branch = conv2d(input_data, 512, 3)
conv_mbbox = slim.conv2d(conv_mobj_branch, 3 * (5 + self.class_num), 1, stride=1, normalizer_fn=None, activation_fn=None, biases_initializer=tf.zeros_initializer())
conv_mbbox = tf.identity(conv_mbbox, name='conv_mbbox')
input_data = conv2d(input_data, 128, 1)
input_data = upsample(input_data, method=self.upsample_method)
input_data = tf.concat([input_data, route_1], axis=-1)
input_data = conv2d(input_data, 128, 1)
input_data = conv2d(input_data, 256, 3)
input_data = conv2d(input_data, 128, 1)
input_data = conv2d(input_data, 256, 3)
input_data = conv2d(input_data, 128, 1)
conv_sobj_branch = conv2d(input_data, 256, 3)
conv_sbbox = slim.conv2d(conv_sobj_branch, 3 * (5 + self.class_num), 1, stride=1, normalizer_fn=None, activation_fn=None, biases_initializer=tf.zeros_initializer())
conv_sbbox = tf.identity(conv_sbbox, name='conv_sbbox')
return conv_lbbox, conv_mbbox, conv_sbbox
def build_network(self, inputs, reuse=False, scope='yolo_v3'):
"""
定义前向传播过程
:param inputs:待输入的样本图片
:param scope: 命名空间
:return: 三个不同尺度的检测层输出
"""
batch_norm_params = {
'decay': self.batch_norm_decay,
'epsilon': 1e-05,
'scale': True,
'is_training': self.is_train,
'fused': None, # Use fused batch norm if possible.
}
with slim.arg_scope([slim.conv2d, slim.batch_norm], reuse=reuse):
with slim.arg_scope([slim.conv2d],
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params,
biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=0.1),
weights_regularizer=slim.l2_regularizer(self.weight_decay)):
with tf.variable_scope('darknet53'):
route_1, route_2, route_3 = self.darknet53(inputs)
with tf.variable_scope('yolov3_head'):
conv_lbbox, conv_mbbox, conv_sbbox = self.detect_head(route_1, route_2, route_3)
return conv_lbbox, conv_mbbox, conv_sbbox函数reorg_layer是对输出解码的过程,网络输出的坐标是相对于特征图尺寸的网格偏移及anchor长宽缩放,所以将anchor缩放到特征图空间:rescaled_anchors = [(anchor[0] / ratio[1], anchor[1] / ratio[0]) for anchor in anchors] ;将预测的中心点通过Sigmoid函数算出网格内部偏移量在加上特征图上网格个个数,即为特征图空间中的实际位置,最后乘以缩放比例还原到原图空间,详细代码如下:
def reorg_layer(self, feature_maps, anchors):
"""
解码网络输出的特征图
:param feature_maps:网络输出的特征图
:param anchors:当前层使用的anchor尺度 shape is [3, 2]
:return: 预测层最终的输出 shape=[batch_size, feature_size, feature_size, anchor_per_scale, 5 + num_classes]
"""
feature_shape = feature_maps.get_shape().as_list()[1:3]
ratio = tf.cast(self.input_size / feature_shape, tf.float32)
anchor_per_scale = self.anchor_per_sacle
# rescale the anchors to the feature map [w, h]
rescaled_anchors = [(anchor[0] / ratio[1], anchor[1] / ratio[0]) for anchor in anchors]
# 网络输出转化——偏移量、置信度、类别概率
feature_maps = tf.reshape(feature_maps, [tf.shape(feature_maps)[0], feature_shape[0], feature_shape[1], anchor_per_scale, self.class_num + 5])
# 中心坐标相对于该cell左上角的偏移量,sigmoid函数归一化到0-1
xy_offset = tf.nn.sigmoid(feature_maps[:, :, :, :, 0:2])
# 相对于anchor的wh比例,通过e指数解码
wh_offset = tf.clip_by_value(tf.exp(feature_maps[:, :, :, :, 2:4]), 1e-9, 50)
# 置信度,sigmoid函数归一化到0-1
conf_logits = feature_maps[:, :, :, :, 4:5]
# 网络回归的是得分,用softmax转变成类别概率
prob_logits = feature_maps[:, :, :, :, 5:]
# 构建特征图每个cell的左上角的xy坐标
height_index = tf.range(feature_shape[0], dtype=tf.int32)
width_index = tf.range(feature_shape[1], dtype=tf.int32)
x_cell, y_cell = tf.meshgrid(width_index, height_index)
x_cell = tf.reshape(x_cell, (-1, 1))
y_cell = tf.reshape(y_cell, (-1, 1))
xy_cell = tf.concat([x_cell, y_cell], axis=-1)
xy_cell = tf.cast(tf.reshape(xy_cell, [feature_shape[0], feature_shape[1], 1, 2]), tf.float32)
bboxes_xy = (xy_cell + xy_offset) * ratio[::-1]
bboxes_wh = (rescaled_anchors * wh_offset) * ratio[::-1]
bboxes_xywh = tf.concat([bboxes_xy, bboxes_wh], axis=-1)
return xy_cell, bboxes_xywh, conf_logits, prob_logits损失函数:
损失函数与之前v2的文章基本相同,只是本例中对分类损失引入了focal loss解决类别不平衡性,同时引入label smooth,最后将三个不同尺度特征图上的损失分别求和:
def loss_layer(self, logits, y_true, anchors):
'''
calc loss function from a certain scale
:param logits: feature maps of a certain scale. shape: [N, 13, 13, 3*(5 + num_class)] etc.
:param y_true: y_ture from a certain scale. shape: [N, 13, 13, 3, 5 + num_class + 1] etc.
:param anchors: shape [9, 2]
'''
feature_size = tf.shape(logits)[1:3]
ratio = tf.cast(self.input_size / feature_size, tf.float32)
# ground truth
object_coords = y_true[:, :, :, :, 0:4]
object_masks = y_true[:, :, :, :, 4:5]
object_probs = y_true[:, :, :, :, 5:]
# shape: [N, 13, 13, 5, 4] & [N, 13, 13, 5] ==> [V, 4]
valid_true_boxes = tf.boolean_mask(object_coords, tf.cast(object_masks[..., 0], 'bool'))
# shape: [V, 2]
valid_true_box_xy = valid_true_boxes[:, 0:2]
valid_true_box_wh = valid_true_boxes[:, 2:4]
# predicts
xy_cell, bboxes_xywh, pred_conf_logits, pred_prob_logits = self.reorg_layer(logits, anchors)
pred_box_xy = bboxes_xywh[..., 0:2]
pred_box_wh = bboxes_xywh[..., 2:4]
# calc iou 计算每个pre_boxe与所有true_boxe的交并比.
# valid_true_box_xx: [V,2]
# pred_box_xx: [13,13,5,2]
# shape: [N, 13, 13, 5, V],
iou = self.broadcast_iou(valid_true_box_xy, valid_true_box_wh, pred_box_xy, pred_box_wh)
# shape : [N,13,13,5]
best_iou = tf.reduce_max(iou, axis=-1)
# get_ignore_mask shape: [N,13,13,5,1] 0,1张量
ignore_mask = tf.expand_dims(tf.cast(best_iou < self.iou_threshold, tf.float32), -1)
# shape: [N, 13, 13, 3, 1]
box_loss_scale = 2. - (1.0 * y_true[..., 2:3] / tf.cast(self.input_size[1], tf.float32)) * (1.0 * y_true[..., 3:4] / tf.cast(self.input_size[0], tf.float32))
true_xy = y_true[..., 0:2] / ratio[::-1] - xy_cell
pred_xy = pred_box_xy / ratio[::-1] - xy_cell
true_tw_th = y_true[..., 2:4] / anchors
pred_tw_th = pred_box_wh / anchors
true_tw_th = tf.where(condition=tf.equal(true_tw_th, 0), x=tf.ones_like(true_tw_th), y=true_tw_th)
pred_tw_th = tf.where(condition=tf.equal(pred_tw_th, 0), x=tf.ones_like(pred_tw_th), y=pred_tw_th)
true_tw_th = tf.log(tf.clip_by_value(true_tw_th, 1e-9, 1e9))
pred_tw_th = tf.log(tf.clip_by_value(pred_tw_th, 1e-9, 1e9))
xy_loss = tf.square(true_xy - pred_xy) * object_masks * box_loss_scale
wh_loss = tf.square(true_tw_th - pred_tw_th) * object_masks * box_loss_scale
# shape: [N, 13, 13, 3, 1]
conf_pos_mask = object_masks
conf_neg_mask = (1 - object_masks) * ignore_mask
conf_loss_pos = conf_pos_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=object_masks, logits=pred_conf_logits)
conf_loss_neg = conf_neg_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=object_masks, logits=pred_conf_logits)
conf_loss = conf_loss_pos + conf_loss_neg
#focal_loss
alpha = 1.0
gamma = 2.0
focal_mask = alpha * tf.pow(tf.abs(object_masks - tf.sigmoid(pred_conf_logits)), gamma)
conf_loss = conf_loss * focal_mask
#label smooth
delta = 0.01
label_target = (1 - delta) * object_probs + delta * 1. / self.class_num
#shape: [N, 13, 13, 3, 1]
class_loss = object_masks * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_target, logits=pred_prob_logits)
xy_loss = tf.reduce_mean(tf.reduce_sum(xy_loss, axis=[1, 2, 3, 4]))
wh_loss = tf.reduce_mean(tf.reduce_sum(wh_loss, axis=[1, 2, 3, 4]))
conf_loss = tf.reduce_mean(tf.reduce_sum(conf_loss, axis=[1, 2, 3, 4]))
class_loss = tf.reduce_mean(tf.reduce_sum(class_loss, axis=[1, 2, 3, 4]))
return xy_loss, wh_loss, conf_loss, class_loss训练代码:
训练程序先加载COCO的预训练模型,冻结darknet53特征提取部分不做更新,只更新检测模块的参数,同时由于COCO数据集有80类,而本例只有2类,故在加载权重时排除 ['yolov3/yolov3_head/Conv_14', 'yolov3/yolov3_head/Conv_6', 'yolov3/yolov3_head/Conv_22']这三层;训练时对学习率采用预热的余弦退火形式,否则容易梯度爆掉,同时加入梯度裁剪的代码保证训练稳定性,具体代码如下:
def train():
start_step = 0
restore = solver_params['restore']
pre_train = solver_params['pre_train']
checkpoint_dir = path_params['checkpoints_dir']
checkpoints_name = path_params['checkpoints_name']
tfrecord_dir = path_params['tfrecord_dir']
tfrecord_name = path_params['train_tfrecord_name']
log_dir = path_params['logs_dir']
batch_size = solver_params['batch_size']
num_class = len(model_params['classes'])
# 配置GPU
gpu_options = tf.GPUOptions(allow_growth=True)
config = tf.ConfigProto(gpu_options=gpu_options)
# 解析得到训练样本以及标注
data = tfrecord.TFRecord()
train_tfrecord = os.path.join(tfrecord_dir, tfrecord_name)
data_num = total_sample(train_tfrecord)
batch_num = int(math.ceil(float(data_num) / batch_size))
dataset = data.create_dataset(train_tfrecord, batch_num, batch_size=batch_size, is_shuffle=True)
iterator = dataset.make_one_shot_iterator()
inputs, y_true_13, y_true_26, y_true_52 = iterator.get_next()
inputs.set_shape([None, 416, 416, 3])
y_true_13.set_shape([None, 13, 13, 3, 5+num_class])
y_true_26.set_shape([None, 26, 26, 3, 5+num_class])
y_true_52.set_shape([None, 52, 52, 3, 5+num_class])
y_true = [y_true_13, y_true_26, y_true_52]
# 构建网络
with tf.variable_scope('yolov3'):
model = network.Network(len(model_params['classes']), model_params['anchors'], is_train=True)
logits = model.build_network(inputs)
# 计算损失函数
loss = model.calc_loss(logits, y_true)
l2_loss = tf.losses.get_regularization_loss()
restore_include = None
restore_exclude = ['yolov3/yolov3_head/Conv_14', 'yolov3/yolov3_head/Conv_6', 'yolov3/yolov3_head/Conv_22']
update_part = ['yolov3/yolov3_head']
saver_to_restore = tf.train.Saver(var_list=tf.contrib.framework.get_variables_to_restore(include=restore_include, exclude=restore_exclude))
update_vars = tf.contrib.framework.get_variables_to_restore(include=update_part)
global_step = tf.Variable(float(0), trainable=False, collections=[tf.GraphKeys.LOCAL_VARIABLES])
learning_rate = tf.train.exponential_decay(solver_params['lr'], global_step, solver_params['decay_steps'], solver_params['decay_rate'], staircase=True)
optimizer = tf.train.MomentumOptimizer(learning_rate=learning_rate, momentum=0.9)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
gvs = optimizer.compute_gradients(loss[0] + l2_loss, var_list=update_vars)
clip_grad_var = [gv if gv[0] is None else [tf.clip_by_norm(gv[0], 100.), gv[1]] for gv in gvs]
train_op = optimizer.apply_gradients(clip_grad_var, global_step=global_step)
tf.summary.scalar("learning_rate", learning_rate)
tf.summary.scalar('total_loss', loss[0])
tf.summary.scalar('loss_xy', loss[1])
tf.summary.scalar('loss_wh', loss[2])
tf.summary.scalar('loss_conf', loss[3])
tf.summary.scalar('loss_class', loss[4])
# 配置tensorboard
summary_op = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter(log_dir, graph=tf.get_default_graph(), flush_secs=60)
save_variable = tf.global_variables()
saver_to_restore = tf.train.Saver(save_variable, max_to_keep=50)
with tf.Session(config=config) as sess:
sess.run([tf.global_variables_initializer(), tf.local_variables_initializer()])
if restore == True:
ckpt = tf.train.get_checkpoint_state(checkpoint_dir)
if ckpt and ckpt.model_checkpoint_path:
stem = os.path.basename(ckpt.model_checkpoint_path)
restore_step = int(stem.split('.')[0].split('-')[-1])
start_step = restore_step
sess.run(global_step.assign(restore_step))
saver_to_restore.restore(sess, ckpt.model_checkpoint_path)
print('Restoreing from {}'.format(ckpt.model_checkpoint_path))
else:
print("Failed to find a checkpoint")
if pre_train == True:
saver_to_restore.restore(sess, os.path.join(path_params['weights_dir'], 'yolov3.ckpt'))
summary_writer.add_graph(sess.graph)
for epoch in range(start_step + 1, solver_params['total_epoches']):
train_epoch_loss, train_epoch_xy_loss, train_epoch_wh_loss, train_epoch_confs_loss, train_epoch_class_loss = [], [], [], [], []
for index in tqdm(range(batch_num)):
_, summary_, loss_, xy_loss_, wh_loss_, confs_loss_, class_loss_, global_step_, lr = sess.run([train_op, summary_op, loss[0], loss[1], loss[2], loss[3], loss[4], global_step, learning_rate])
train_epoch_loss.append(loss_)
train_epoch_xy_loss.append(xy_loss_)
train_epoch_wh_loss.append(wh_loss_)
train_epoch_confs_loss.append(confs_loss_)
train_epoch_class_loss.append(class_loss_)
summary_writer.add_summary(summary_, global_step_)
train_epoch_loss, train_epoch_xy_loss, train_epoch_wh_loss, train_epoch_confs_loss, train_epoch_class_loss = np.mean(train_epoch_loss), np.mean(train_epoch_xy_loss), np.mean(train_epoch_wh_loss),np.mean(train_epoch_confs_loss), np.mean(train_epoch_class_loss)
print("Epoch: {}, global_step: {}, lr: {:.8f}, total_loss: {:.3f}, xy_loss: {:.3f}, wh_loss: {:.3f},confs_loss: {:.3f}, class_loss: {:.3f}".format(epoch, global_step_, lr, train_epoch_loss, train_epoch_xy_loss, train_epoch_wh_loss, train_epoch_confs_loss, train_epoch_class_loss))
saver_to_restore.save(sess, os.path.join(checkpoint_dir, checkpoints_name), global_step=epoch)
sess.close()
测试代码:
采用单帧进行测试,网络输出结构需要进行nms过滤然后可视化输出。
def predict_image():
image_path = "XXX"
image = cv2.imread(image_path)
image_size = image.shape[:2]
input_shape = [model_params['input_height'], model_params['input_width']]
image_data = preporcess(image, input_shape)
image_data = image_data[np.newaxis, ...]
input = tf.placeholder(shape=[1, input_shape[0], input_shape[1], 3], dtype=tf.float32)
model = Network(len(model_params['classes']), model_params['anchors'], is_train=False)
with tf.variable_scope('yolov3'):
logits = model.build_network(input)
output = model.inference(logits)
checkpoints = "/home/chenwei/HDD/Project/YOLOv3/weights/yolov3.ckpt"
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, checkpoints)
bboxes, obj_probs, class_probs = sess.run(output, feed_dict={input: image_data})
bboxes, scores, class_max_index = postprocess(bboxes, obj_probs, class_probs, image_shape=image_size, input_shape=input_shape)
resize_ratio = min(input_shape[1] / image_size[1], input_shape[0] / image_size[0])
dw = (input_shape[1] - resize_ratio * image_size[1]) / 2
dh = (input_shape[0] - resize_ratio * image_size[0]) / 2
bboxes[:, [0, 2]] = (bboxes[:, [0, 2]] - dw) / resize_ratio
bboxes[:, [1, 3]] = (bboxes[:, [1, 3]] - dh) / resize_ratio
img_detection = visualization(image, bboxes, scores, class_max_index, model_params["classes"])
cv2.imshow("result", img_detection)
cv2.waitKey(0)模型检测的是face和hat两类,没有安全帽的图片,就找了张公司活动的照片检测人脸了。嘿嘿,这里没有小编。

其他相关:
从官网下载的COCO预训练权重是weights后缀格式,这里weights_to_ckptz转换成tensorflow使用的ckpt:
def weights_to_ckpt():
num_class = 80
image_size = 416
anchors = [[676,197], [763,250], [684,283],
[868,231], [745,273], [544,391],
[829,258], [678,316, 713,355]]
weight_path = '../weights/yolov3.weights'
save_path = '../weights/yolov3.ckpt'
model = Network(num_class, anchors, False)
with tf.Session() as sess:
inputs = tf.placeholder(tf.float32, [1, image_size, image_size, 3])
with tf.variable_scope('yolov3'):
feature_maps = model.build_network(inputs)
saver = tf.train.Saver(var_list=tf.global_variables(scope='yolov3'))
load_ops = load_weights(tf.global_variables(scope='yolov3'), weight_path)
sess.run(load_ops)
saver.save(sess, save_path=save_path)
print('TensorFlow model checkpoint has been saved to {}'.format(save_path))
load_weights函数是将预训练权重中的参数根据名称逐个赋值给当前网络的参数权重:
def load_weights(var_list, weights_file):
"""
loads and converts pre-trained weight,the first 5 values correspond to
major version (4 bytes)
minor version (4 bytes)
revision (4 bytes)
images seen (8 bytes)
:param var_list: list of network variables
:param weights_file: name of the binary file
:return:
"""
with open(weights_file, 'rb') as fp:
# skip first 5 values
np.fromfile(fp, dtype=np.int32, count=5)
weights = np.fromfile(fp, dtype=np.float32)
ptr = 0
i = 0
assign_ops = []
while i < len(var_list) - 1:
var1 = var_list[i]
var2 = var_list[i + 1]
if 'Conv' in var1.name.split('/')[-2]:
# check type of next layer
if 'BatchNorm' in var2.name.split('/')[-2]:
# load batch norm params
gamma, beta, mean, var = var_list[i + 1:i + 5]
batch_norm_vars = [beta, gamma, mean, var]
for var in batch_norm_vars:
shape = var.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape(shape)
ptr += num_params
assign_ops.append(tf.assign(var, var_weights, validate_shape=True))
# we move the pointer by 4, because we loaded 4 variables
i += 4
elif 'Conv' in var2.name.split('/')[-2]:
# load biases
bias = var2
bias_shape = bias.shape.as_list()
bias_params = np.prod(bias_shape)
bias_weights = weights[ptr:ptr + bias_params].reshape(bias_shape)
ptr += bias_params
assign_ops.append(tf.assign(bias, bias_weights, validate_shape=True))
# we loaded 1 variable
i += 1
# we can load weights of conv layer
shape = var1.shape.as_list()
num_params = np.prod(shape)
var_weights = weights[ptr:ptr + num_params].reshape((shape[3], shape[2], shape[0], shape[1]))
# remember to transpose to column-major
var_weights = np.transpose(var_weights, (2, 3, 1, 0))
ptr += num_params
assign_ops.append(tf.assign(var1, var_weights, validate_shape=True))
i += 1
return assign_ops














 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









