






近期工作上基于YOLOv3做项目并且需要测试TI开发板对OD模型的友好程度,所以想写个YOLO系列的专题,本文就从2015年的v1版本《You Only Look Once: Unified, Real-Time Object Detection》开始讲起。(文章比较老,旨在总结,大牛误喷)
- YOLOv1理论篇
- YOLOv1实践篇
背景介绍:
YOLO的训练和检测均在一个端到端的网络中进行,将物体检测作为回归问题求解,输入图像经过一次Inference,便能得到图像中所有物体的位置和其所属类别及相应置信概率。这种直接选用整图训练模型的架构可以更好的区分目标和背景区域,相比于proposal的方法更少把背景区域误检为目标。
网络模型:
YOLO网络结构由24个卷积层与2个全链接层构成,卷积层用来提取图像特征,全链接层用来预测图像位置和类别概率,网络结构借鉴了GoogleNet分类网络,大量使用1×1和3×3卷积层。网络入口为448×448,图片进入网络之前需要经过resize,网络的输出的张量维度是:S × S ×(B × 5 + C)。
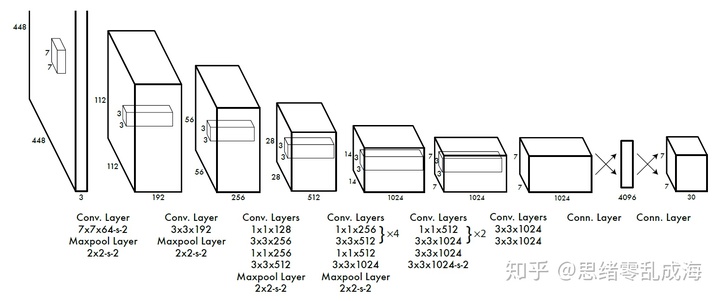
网络的输出是一个7×7×30的Tensor,7×7表示特征图划分的网格数,如下图所示:
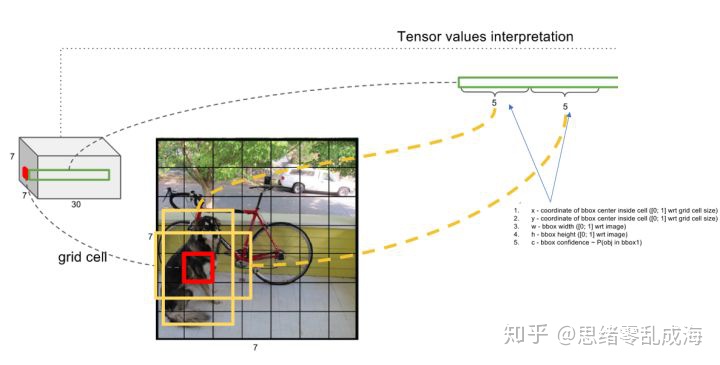
(1)每个小格会对应B个边界框,每个bbox预测5个值: x, y, w, h, 置信度。(x, y)是bbox的中心在对应格子里的相对位置,范围[0,1]。(w, h)是bbox相对于全图的的长宽,范围[0,1]。x, y, w, h的4个gt值可以算出来。
(2)每个边界框都有一个置信度,反映当前bounding box是否包含物体以及物体位置的准确性:
其中,若bounding box包含物体,则P(object)=1,否则P(object)=0。IOU为预测bounding box与物体真实区域的交集面积。如果格子内有物体,则Pr(Object)=1,此时置信度等于IOU。如果格子内没有物体,则Pr(Object)=0,此时置信度为0。
(3)每个小格会对应C个概率值,找出条件概率对应的类别P(Class|object),表示该单元格存在物体且属于第i类的概率。
(4)在测试的时候,每个网格预测的类别信息和bounding box预测的confidence信息相乘,就得到每个boundig box的类别置信度,然后根据阈值过滤掉得分低的boxes,再对剩余的进行NMS处理得到最终检测结果:
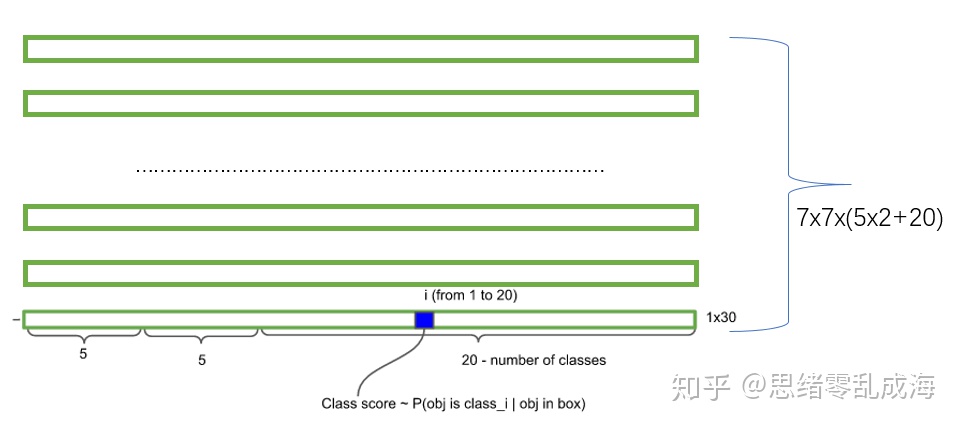
注:class信息是针对每个网格的,confidence信息是针对每个bounding box的。
损失函数:
YOLO使用均方误差作为损失函数来优化模型参数,即网络输出的S×S×(B×5+C)维向量与真实图像对应S×S×(B×5+C)维向量的均方和误差,设计目的就是让coord,confidence,classification这三个方面达到很好的平衡。
但是粗暴的采用均方和误差作为优化目标会存在几点不足:
1. 定位误差(x,y,w,h)和分类误差同等重要并不合理,需给定位损失赋予较大的loss weight。
2.置信度误差针对网格中有object和没有object同等重要会导致不平衡问题,需给没有object的置信度损失赋予较小的loss weight。
3.对于大的物体,小的偏差对于小的物体影响较大,为了减少这个影响,所以对bbox的宽高都开根号。
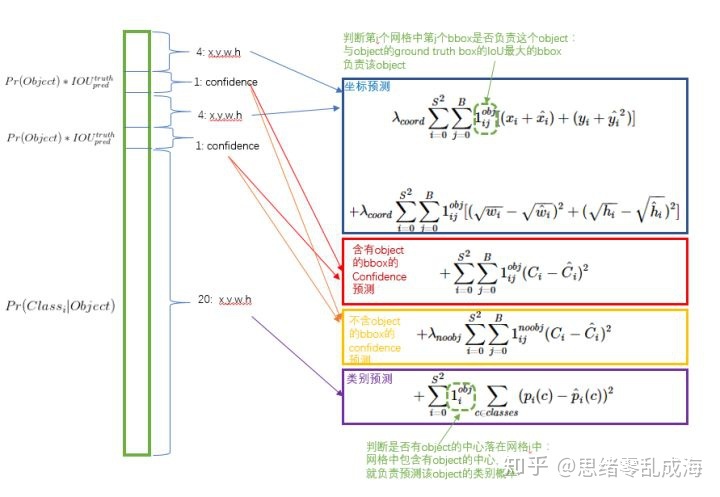
在 YOLO中,每个栅格预测多个bounding box,但在网络模型的训练中,希望每一个物体最后由一个bounding box predictor来负责预测。因此,当前哪一个predictor预测的bounding box与ground truth box的IOU最大,这个 predictor就负责 predict object。这会使得每个predictor可以专门的负责特定的物体检测。随着训练的进行,每一个 predictor对特定的物体尺寸、长宽比的物体的类别的预测会越来越好。
预测流程:
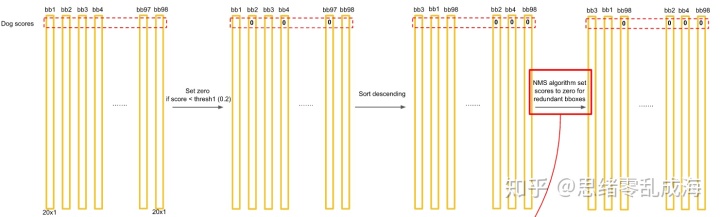
1. 类别置信度的过滤:根据类别置信度的计算可以得到一个20*(7*7*2)=20*98的score矩阵,括号里面是bounding box的数量,20代表类别。将20个类别轮流进行:在某个类别中(即矩阵的某一行),将得分少于阈值(0.2)的设置为0,然后再按得分从高到低排序。
2. 非极大值抑制过滤:用NMS算法去掉重复率较大的bounding box(NMS:针对某一类别,选择得分最大的bounding box,然后计算它和其它bounding box的IOU值,如果IOU大于0.5,说明重复率较大,该得分设为0,如果不大于0.5,则不改;这样一轮后,再选择剩下的score里面最大的那个bounding box,然后计算该bounding box和其它bounding box的IOU,重复以上过程直到最后)。
3. 每个Bbox的score过滤:每个bounding box的20个score取最大的score,如果这个score大于0,那么这个bounding box就是这个socre对应的类别(矩阵的行),如果小于0,说明这个bounding box里面没有物体,跳过即可。
模型缺点:
(1)每个网格只能预测一类物体且对小物体检测效果差:当一个小格中出现多于两个小物体或者一个小格中出现多个不同物体时效果不佳。虽然B表示每个小格预测边界框数,但YOLO默认同格子里所有边界框为同类物体,并且最终只选择IOU最高的bounding box作为输出。
(2)网络最后采用全连接层,不仅参数量大而且限制了图片的输入尺寸,在进入网络前需resize为448×448,降低检测速度。
(3)识别物体位置精准性差,
相关问题:
YOLO的每个cell有两个检测器,每个检测器分别预测一个bounding box的xywh和相应的confidence。但分类部分的预测是共享的,由于这个原因,同一个cell是没办法预测多个目标的。
1. 假设类别预测不是共享的,cell中两个检测器都有各自的类别预测,这样能否在一个cell中预测两个目标?
不可以。如果一个cell要预测两个目标,那么这两个检测器要怎么分工预测?谁负责谁很难确定。所以后续算法采用anchor机制,根据anchor和ground truth的IOU大小来安排anchor负责预测哪个物体,解决同个cell不能预测多个目标的问题。
2. 既然一个cell只能预测一个目标,为什么要预测两个bounding box?
两个检测器一个预测,然后网络选择预测的好的哪个检测器(IOU大的)来进行预测。换句话说就是找一堆人干同一件事,最后选个干的最好的。














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









