






AM3D是来自于ICCV 2019年的一篇单目做3D检测的文章《Accurate Monocular 3D Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving》
文章链接:https://arxiv.org/abs/1903.1144
核心思想:
算法首先获取到深度信息和二维目标位置先验之后,将二维深度信息映射到三维空间,以点云数据形式进行后续处理。在三维姿态估计过程中算法基于Attention机制提出了多信息融合策略,将点云空间信息,像素RGB信息以及目标局部特征聚合在一起,并设计了点云分割模块来去除目标区域的背景无关信息。
框架结构:
整个算法框架分为两个模块:3D数据生成和3D边框估计。
- 3D数据生成部分首先采用两个CNN网络分别对RGB图像做2D检测和深度估计,得到2D Box和深度图像;然后深度图像根据相机参数转换成三维点云;
- 3D边框估计部分首先对三维点云利用2D Box对其中的目标区域进行前景分割;然后采用注意力机制嵌入有效的RGB信息;最后使用PointNet回归3D Box。
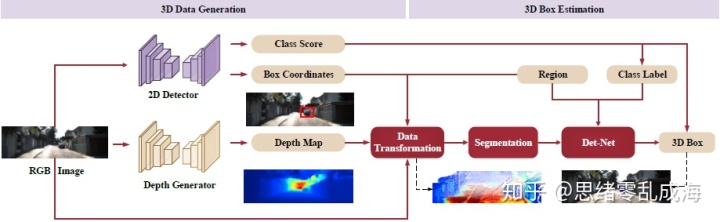
整个框架基于2D驱动3D的感知,类似于F-PointNet。在三维数据生成阶段,训练两个深度CNNs进行中间任务(2D检测和深度估计)来获取位置和深度信息。将生成的深度转换为点云,这是一种更好的3D检测表示,然后使用2D边界框来获得关于感兴趣区域位置的先验信息。最后,提取每个RoI中的点作为后续步骤的输入数据。在三维边框估计阶段,为了改进最后的任务,分别设计了背景点分割和RGB信息聚合两个模块。然后使用PointNet作为骨干网络来预测每个RoI的3D位置、维度和方向。
实现细节:
1、3D数据生成
采用现有的方法(文章重点在于使用而非获取数据,所以具体方法未公布)训练两个深度CNN来生成深度图和2D边界框来提供空间信息和位置先验; 利用camera calibration文件将给定二维图像空间深度的像素坐标(u,v)转换为三维坐标(x,y,z),计算如下:
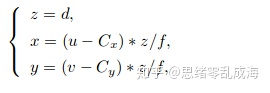
注意:可以使用Point Cloud编码器-解码器网络来学习从(u,v,d)到(x,y,z)的映射,因此在测试阶段可以不再需要标定文件(因为在点云生成阶段引入的误差远远小于深度图本身包含的噪声)。
2、3D边框估计
经过3D数据生成阶段后,将输入数据编码为点云。但是这些数据中有许多背景点,为了准确地估计目标的位置,这些背景点应该被丢弃。本文采用一种基于深度的分割方法。首先计算每个二维边界框的深度均值,得到RoI的近似位置,并将其作为阈值。所有z通道值大于此阈值的点都被视为背景点。嵌入点集可表示为:
然后使用轻量级网络预测RoI的中心δ , 用它来更新点云:
然后,我们选择PointNet作为3D检测骨干网估计3D对象的编码中心(x, y, z),大小(h、w、l)和航向角θ。最后,我们将二维边界盒的置信度分数赋值给相应的三维检测结果。
3、RGB信息融合
RGB信息融合这一步的目的是为了提高算法的可靠性。将补充的RGB信息聚合到点云,通过公式5将信息添加到生成的点云中:
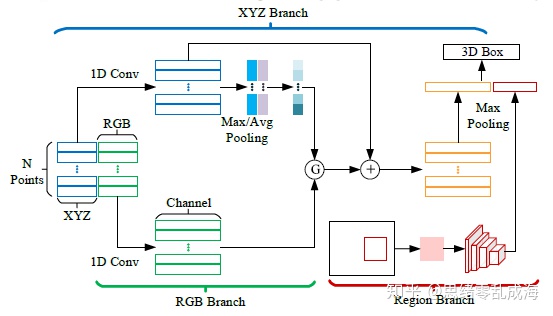
其中D为输出对应输入点RGB值的函数。这样,这些点被编码为6D向量:[x,y,z,r,g,b]。但是通过简单的concat来添加RGB信息是不可行的。因此本文引入了一个融合任务的注意机制,利用注意机制来引导空间特征和RGB特征之间的信息传递。由于传递的信息流并不总是有用的,注意力可以作为一个门函数来控制信息流,当我们将RGB消息传递到它对应的点时,首先从XYZ分支生成的特征图F中生成一个attention map G,如下图所示:
f是非线性函数,σ是sigmoid函数。然后获得权重占比传递消息,注意力机制如下:
除了点级特征融合之外,我们还引入了另一个分支来提供对象级RGB信息。特别是,我们首先裁剪RGB图像的RoI,并将其调整为128×128。然后我们使用CNN提取对象级特征映射Fobj,从融合模块获得的最终特征映射集F为:F←concat(Fxyz,Fobj),其中concat表示连接操作。
4、优化细节
整个培训过程分为两个阶段。在第一阶段,我们只根据原始论文的训练策略对中间网络进行优化。之后,我们利用多损失丢失函数,同时优化两个网络进行三维检测:
其中L loc为轻量级定位网络的损失函数(仅为中心),L det为三维检测网络(中心、大小和航向角),L corner为角点损失,首先将输出目标解码成定向的3D Box,然后根据ground truth在8个Box的(x, y, z)坐标上直接计算平滑的L1损失。
预处理:
RGB图像归一化(/255.0)
RGB图像标准化(标准正态分布)
网络结构:
depth estimation(任意)
2D Detection(任意)
3D Detection:PointNet
Fusion:半通道的ResNet-34和全局池化,得到1×1×256个特征图
超参数设计:
batch_size:32
epoch:200
lr_init:0.001
20个epoch,lr减少一半
dropout:0.7(除最后一层fc)
要点分析:
1.单目三维感知的关键
基于图像3D感知中的数据表示问题:采用Front view这样的2D图像去直接回归3D坐标或者无脑叠加RGB和Depth Map无法得到有效的三维空间信息。所以需要针对不同的任务和维度,找到一种合理方式显示表达数据的原始分布。
该文的解决方法:将2D图像进行深度估计再结合相机参数生成伪点云,得到三维空间信息,最后采用常规的点云目标检测方法在三维空间做检测。
将深度图转换为点云的好处如下:
(1)点云数据显式地显示空间信息,这使得网络更容易学习从输入到输出的非线性映射。
(2)由于某些特定的空间结构只存在于三维空间中,网络可以学习到更丰富的特征。
(3)点云深度分析的重大进展为我们提供了一种更加有效的三维检测结果估计方法。
2.多模态信息的融合
不同与F-PointNet和Pseudo-LiDAR,AM3D为了进一步提高三维检测精度,在伪点云中额外加入RGB信息。参考之前的多模态信息融合方法,分别处理点云的空间信息和图像的颜色信息,然后将提取到的特征拼接起来经过全连接做预测。这种硬连接的方式既没有统一不同模态信息的隐空间,也没有让两者之间进行有效交互。所以需要针对不同模态的数据找到一种融合的方法。
该文的解决方法:引入带注意力机制的融合方式,先通过max pooling和average pooling得到点云空间信息的feature map,然后学习出attention map并乘上点云颜色信息的feature map,以有效指导RGB特征到坐标特征的信息传递。
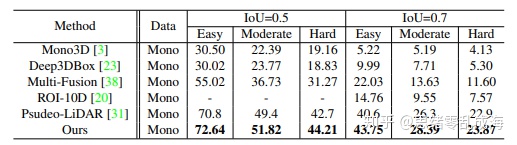
思考与展望:
如果用2D的图像做3D的检测,数据的表示和交互形式是关键点。采用端到端的框架(提供一份数据,希望得到某种输出),由于CNN内部不同特征之间的隐式关系或间隙巨大,会限制神经网络的学习能力。所以需要分解和细化网络模型的功能,递进式学习。盲目的叠加不同数据或者特征并不是一种好的方式:比如图像与深度图直接concat,或者点云特征和图像特征直接concat。本篇文章的主要思想是找到一个更好的输入表达式,而特征的提取,检测器方面采用较为传统的方法,所以从精度上从检测算法入手。














 1127
1127











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









