







这篇笔记用来描述 2025年 发表在arxiv上的一篇有关 VLA 领域的论文。主要是贡献了一个跨度非常广泛的数据集,单训练集就达到了 800GB,可以直接从HuggingFace中下载,就目前来看(2025年04月03日)还没有几篇论文提出的模型打过这个榜。
写在最前面
为了方便你的阅读,以下几点的注意事项请务必了解:
- 该系列文章每个字都是我理解后自行翻译并写上去的,可能会存在笔误与理解错误,如果发现了希望读者能够在评论区指正,我会在第一时间修正错误。
- 阅读这个系列需要你有基础的 VLA, LLM, VLM 相关基础知识,有时候我会直接使用英文名词,因为这些词汇实在不容易找到符合语境的翻译。
- 原文可能因为版面限制存在图像表格与段落不同步的问题,为了更方便阅读,我会在博文中重新对图像表格进行排版,并做到引用图表的文字下方就能看到被引用的图表。因此可能会出现一张图片在博客中多处位置重复出现的情况。
- 对于原文中的图像,我会在必要时对图像描述进行翻译并附上我自己的理解,但如果图像描述不值得翻译我也不会强行写上去。
Basic Information
- 论文标题:VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
- 原文链接: https://arxiv.org/abs/2412.18194
- 发表时间:2024年12月24日
- 发表平台:arxiv
- 预印版本号:[v1] Tue, 24 Dec 2024 06:03:42 UTC (43,062 KB)
- 作者团队:Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, Xipeng Qiu
- 院校机构:
- Fudan University;
- 项目链接: https://vlabench.github.io
- GitHub仓库: https://github.com/OpenMOSS/VLABench
Abstract
通用具身agent旨在理解用户的自然指令或意图并精确地完成通用任务。近期,基于基础模型尤其是VLA的方法已显示出解决语言条件操作 (Language-conditioned manipulation, LCM) 任务方面的巨大潜力。然而现有的基准测试不能充分满足 VLA 和相关算法的需求。为了在更好地定义通用任务并推进 VLA 的研究,作者提出了 VLABench,一个用于评估 LCM 任务的开源基准测试数据集。VLABench 提供了 100 个任务类别,每个任务类别都具有很强的随机性,涉及 2000 多个对象。 VLABench 在四个关键方面超越了之前的基准测试:1)需要世界常识转移的任务;2)具有隐含意图的自然语言指令;3)需要多步推理的长期任务;4)对行动策略和语言模型能力的评估。基准测试评估包括对网格和纹理的理解、空间关系、语义指令、物理定律、知识转移和推理等。为了支持下游模型微调,作者提供了结合启发式技能和先验信息的自动化框架采集到的高质量训练数据。实验结果表明,当前预训练的SOTA VLA 和基于 VLM 模型在这个基准测试中都有提升空间。
1. Introduction
语言条件控制是具身智能的一项基本挑战,也是迈向通用人工智能的基础。此类任务需要智能体掌握多种能力:解释自然语言指令、理解复杂环境、做出决策、制定计划、执行精确操作。LLM和VLM的快速发展以其在语义理解、编码、规划、推理方面的能力彻底改变了该领域。强大的泛化能力启发了语言控制的两种主要方法:使用大规模机器人数据预训练VLA,如 RT-2 和 Palm-E ;将基础模型集成到agent工作流中,如 Vox-Poser 和 Copa 将 LLM/VLM 输出与抓握预测和运动规划算法相结合。
虽然现实世界的机器人实验提供了重要参考,但其复杂性和环境多变性往往会对可重复性提出挑战。仿真评估已成为一种公平而实用的替代方案。现有的基准测试如 RLBench、Calvin 和 LIBERO 提供了多样化的任务集,但未能满足基于基础模型的要求,应包含对用户意图的语义理解、常识知识的整合、解释各种视觉场景的强大能力,并进行复杂的多步推理。这类任务需要多模态理解整合,以有效地解释和响应复杂现实世界环境。例如,RT-2 中的一项任务是“将可乐罐移到Taylor Swift身边”,而 CoPA 中的另一项任务是“给我泡一杯手冲咖啡”。第一项任务要求机器人运用常识来识别Taylor,这是以前的策略难以实现的知识转移能力。第二项任务进一步加大了难度,要求机器人将任务分解为子任务并执行操作咖啡机,这类任务对以前单一策略模型而言很难完成。
为了更好地定义适合基础模型的语言指令操作任务类型,并提供标准化评估来推进机器人研究,作者推出引入了 VLABench。VLABench 是一个开源基准测试平台,专门为基于基础模型的方法设计。VLABench 中的任务被分为几个维度,包括 1)掌握常识和世界知识,2)理解网格和纹理,3)理解语义丰富的指令,4)空间理解,5)掌握物理规则,6)逻辑推理能力。VLABench 提供了 100 个任务类别,内涵超过 2000 个 3D 对象和场景。通过多种技能的学习来评估泛化能力,提供涵盖视觉、语言、规划、知识转移、行动维度的全面评估。
为了确保公平的比较和评估,作者开发了一个自动化数据采集框架,为每个任务构建标准化数据集,支持模型训练和微调。在这个数据集上作者进行了大量实验,以评估三种不同类型的模型能力:1)预训练的 VLA;2)集成基础模型的工作流;3)VLM。实验结果表明,现有的 VLA 在该数据集上没有表现出大型模型应有的泛化能力或“涌现”现象。本文的主要贡献总结如下:
- 提出了 VLABench,第一个旨在全面评估 VLA 和 VLM 在机器人操作任务中能力的基准测试,涵盖技能、视觉、语言、任务执行、世界常识、推理等多个维度;
- 在标准化评估框架内根据基础模型的能力定义了 100 个 LCM 任务。这些任务需要对语义、视觉、空间推理、物理定律有深入的理解,并能够进行长期规划、将世界常识转化为任务执行的能力;
- 提供了一个可扩展的数据构建框架和一个标准化的评估数据集。自动化数据构建方法有助于未来对预训练机器人数据的研究;
- 实验表明,目前预训练的 VLA 尚未表现出 LLM 应有的强大泛化能力,现有的 SOTA VLM 在具体场景中也存在局限性;
2. Related Works
Benchmarks and Datasets.
先前已经有许多基准测试(如 RLBench 和 LIBERO )用于评估现实物理环境中基于语言的操纵策略。Table. 1提供了这些基准测试的比较。但其中大多数都 侧重于技能学习,未能充分解决长期规划能力问题。同时,一些基准测试对标的是室内房间尺度上的移动操纵任务,需要长期记忆或推理能力。然而,这些交互通常 通过接口而不是直接物理操作,限制了在现实世界场景中的可迁移性。此外,虽然另一些基准测试在任务格式、难度、规模方面取得了较大进步,但这些基准测试在很大程度上 忽视了语言在任务中的指导作用,依赖于明确的动作指令模版。 VLABench 首次将自然人机交互、隐式目标导向语义、基于常识要求等特性引入机器人操作任务,如 Fig.2 所示。在泛化评估方面,以前的研究通常在同一类别的实例级别评估模型,这限制了它们评估跨不同对象类别或同一技能集内不同任务的泛化的能力。相比之下,VLABench 是第一个评估跨任务、对象类型、任务类别的泛化能力基准,为模型的多功能性提供了更全面的评估。
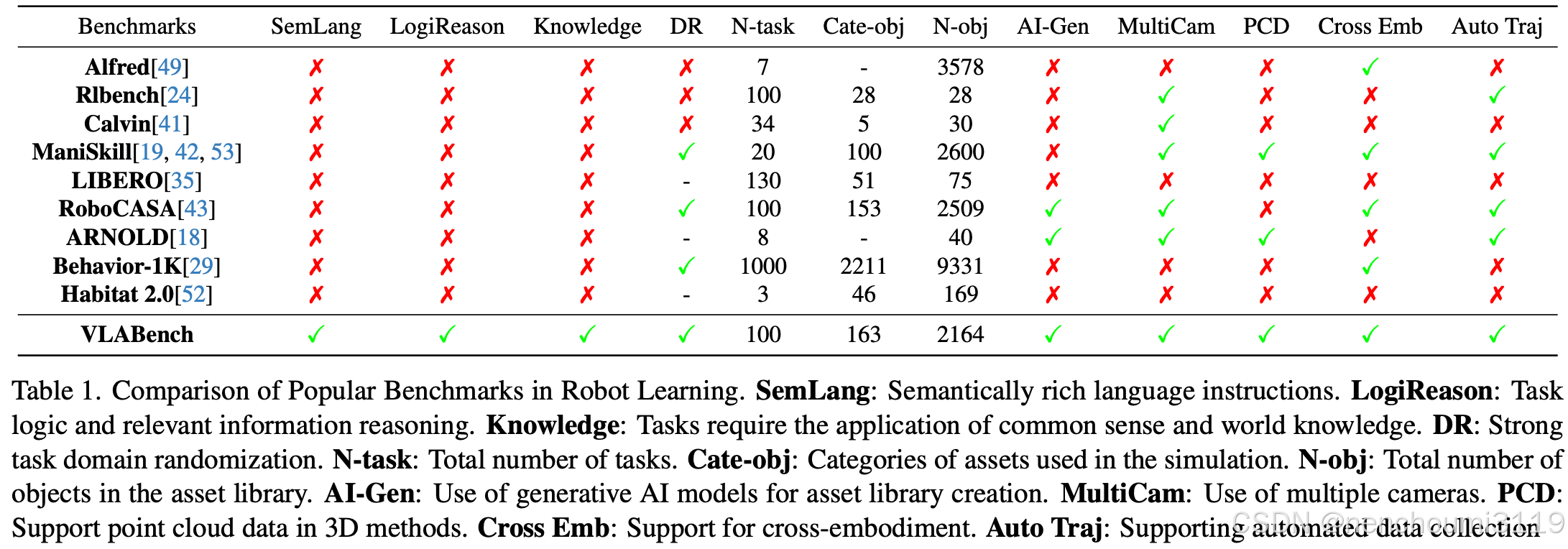

学者们已经在真实和仿真中建立了大规模数据集用于大模仿学习以进行操控。然而,真实世界的数据面临可扩展性方面的挑战,很难大规模采集足够的数据。仿真数据集虽然更具可扩展性,但场景和任务的多样性往往有限,并且仍然需要远程操作来采集数据。VLABench 通过提供与现实世界条件更紧密相关的任务来解决这些限制,涵盖视觉、语言、任务、技能的各个方面。此外,还引入了一种高效而强大的仿真数据自动生成过程,大大增强了任务多样性和可扩展性。
Pretrained Vision-Language-Action Models
多模态模型的兴起以及操作数据集的构建,已将VLA整合到语言条件操作任务中。虽然 VLA 一词通常指结合视觉和语言输入进行策略学习的模型,但本文重点关注预训练的模型方法。多项研究对预训练VLM进行了微调,以实现语言条件操作。这些模型对未曾遇到的物体和任务表现出了可观的泛化能力,但控制精度在一定程度上受到动作离散化的限制。为了解决这个限制,一些方法使用扩散模型作为策略网络或使用扩散解码器。基于扩散的预训练模型在改进连续空间分布方面表现出了良好的进展。VLABench选取了上述几个代表性方法进行综合评估。
Framework Utilizing Foundation Models
预训练语言模型和视觉语言模型已展示出强大的泛化和多功能性。一些研究人员将这些预训练模型的一般感知和认知能力与传统规划和控制算法相结合,以创建agent工作流。这些框架允许机器人执行复杂的zero-shot操作任务而无需额外的训练。为了利用基础模型进行操作的能力,一些工作利用LLM 的代码理解生成能力结合运动规划优化算法来解决基本的操作任务。此外,还有一些方法利用大型模型将长期任务分解为子任务,然后集成感知和轨迹生成模块来构建整个操作流程。然而,大多数此类zero-shot方法严重依赖于即时设计、每个模块的准确性,甚至调用模型的特定参数。虽然这些方法都表现出很强的泛化能力,但往往面临准确性方面的挑战。VLABench 提供了一个zero-shot评估框架来评估此类工作流的性能,并提供了对其有效性的度量。
3. VLABench
3.1. Task Description
VLABench 由 60 个基本任务和 40 个复合任务组成,按任务难度和所需时间步长分类。这些任务旨在涵盖丰富的技能与充足的视觉语言语义信息。对于技能学习,VLABench 中的 100 个任务涵盖范围广泛包括: 1) 拾取和放置、2) 打开和关闭门、3) 打开和关闭抽屉、4) 将物体挂在墙上、5) 使用工具(例如锤子钉子)、6) 按下按钮、7) 插入、8) 倒出、9) 扭转、 10) 探索。此外,VLABench 更加注重现实场景和日常基本任务,以及更多交互式语言指令、更广泛的任务设置、常识和社会知识融合等需要逻辑规划的长期任务,如Fig.3 所示。VLABench 对任务泛化采用了更严格的定义。
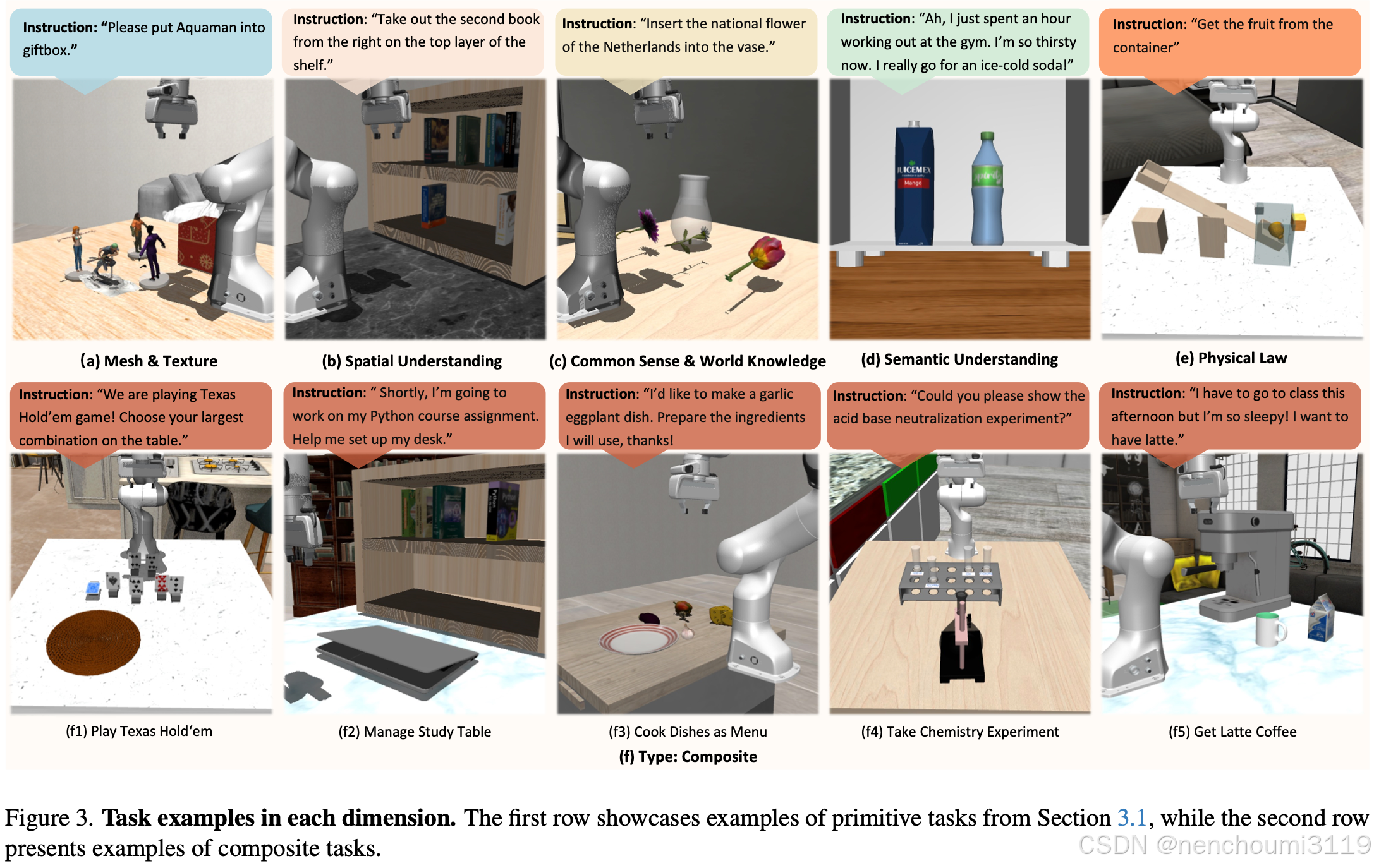
Primitive Tasks
原始任务分为五个维度,每个维度对应一个特定能力维度的评估。
- Mesh&Texture Understanding:这类任务需要模型识别不同的网格、理解各种纹理特征。以
Fig.3(a)所示的SelectToy任务为例,机器人需要直接将特定玩具(例如 Aquaman)放入容器中。模型必须具备强大的视觉能力,才能准确识别如此复杂的网格和纹理; - Spatial Understanding:空间理解任务涉及各种空间关系,如第 n 个左/右位置、容器内/外、第 m 行第 n 列、近/远、特定物体旁等,代表相对位置关系。
Fig.3 (b)显示了PullBook中的一个任务案例。复杂的相对位置关系对模型的多模态理解提出了极高的要求; - Common Sense & World Knowledge:与常识相关的任务需要将预训练阶段获得的知识迁移到解决问题中。
Fig3.(c)所示的任务要求不仅从视觉信息中识别不同类型的花朵,还利用世界知识确定“郁金香是荷兰的国花”; - Semantic Understanding:这类任务强调语言指令的复杂性、微妙性、自然交互性。任务目标通常涵盖在自然对话中的隐含表达。为了在
GetDrink任务中表现出色(Fig.3(d)),模型必须从冗长的指令中捕捉到隐含的请求:从冰箱中取出一瓶冰镇可乐; - Physical Law:这种类型的任务要求机器人整合视觉信息,并根据物理原理和实时观察采取正确的行动。在
Fig.3 (e)中的UseSeesaw任务中,机器人被命令抓住一个无法直接拿到的物体。agent必须应用杠杆原理,通过足够的重量来举起另一端的目标物体;
Composite Tasks
VLABench 中的复合任务涉及多种技能组合、长期任务规划、来自指令与场景甚至游戏规则的多步逻辑推理。Fig.3(f)展示了各种复杂任务。复合任务的轨迹明显更长,平均情节长度超过 500 个时间步长,远远超过原始任务的平均 120 个时间步长。在Fig.3 (f2)中,模型不仅需要从视觉信息中正确识别所有扑克牌,并使用扑克规则的世界知识来选择最佳牌,还必须翻转面朝下的牌以获取完整信息。这种类型的任务需要有意识地满足先决条件,以前从未被纳入到数据集中。复合任务还需要从自然对话中提取用户的隐性需求。Fig.3 f(2)中的需要将 Python textbook 放在桌子上并打开笔记本电脑。
3.2 Benchmark
Evaluation
VLABench 将评估分为三个主要类别:预训练或微调的VLA模型评估、将基础模型与各种算法相结合的启发式工作流程、VLM的多维评估。
- Generalization Ability of VLAs:对于训练好的VLA模型,
VLABench中的评估包括两种设置:见过的物体和未见过的物体。见过的物体评估与训练集的数据分布紧密相关,主要测试模型的技能学习能力。同时,未见过的物体对评估提出了更大的挑战,要求模型表现出强大的泛化能力。与之前的基准测试不同,VLABench将未见过的物体定义为完全不同的类别。例如,在PickFruit任务中,见过的目标物体包括苹果、香蕉、梨和橙子,而未见过的物体包括猕猴桃、芒果、草莓、柠檬和其他不同的水果。这种设置不仅要求模型表现出强大的视觉泛化能力,还要求模型能够处理与不同类别物体截然不同的常识性知识,以及处理带有不熟悉标记的长指令的挑战。 - Zero-shot Transfer Ability of Heuristic Workflow:零训练的方法在单一设置下进行评估,但评估内容涉及多个能力维度。除了上面提到的原始任务能力点外,评估还范围扩大到各种技能和长期任务,以评估工作流的整体能力和执行稳健性;
- Comprehensive Evaluation of VLMs’ Capabilities:与启发式工作流类似,VLM 的评估也很全面。由于 VLM 缺乏内在的行动能力,因此组织了一个技能库并将其集成到领域特定语言 (DSL) 中,利用带注释的信息作为先验知识。此 DSL 充当 VLM 可调用的简单 API,从而实现高效的交互。
Metric
评估侧重于泛化能力,但任务成功率指标(限制为 0 或 1 分)更直接的评估技能学习能力。因此,引入了进度分数 (PS) 作为分级指标,以进行更细致的评估。PS 的计算公式为:
P S = α n c o r r e c t N + ( 1 − α ) ⋅ m d o n e M \begin{equation} PS=\alpha\frac{n_{correct}}{N} + (1-\alpha)\cdot\frac{m_{done}}{M} \end{equation} PS=αNncorrect+(1−α)⋅Mmdone
其中 N N N 表示目标物体和容器的总数, n c o r r e c t n_{correct} ncorrect 表示正确选择的数量。 M M M 表示任务中的子步骤总数, m d o n e m_{done} mdone 表示已完成的子步骤数。这里, α \alpha α 是分配给正确决策的权重,默认设置为 0.2,而 1 − α 1-\alpha 1−α 表示分配给任务进度的权重。对于 VLM 的评估,这里采用了更详细的评分方法,指标包括技能回忆率、参数回忆率、技能和参数回忆率、精确匹配率。
3.3 Simulation
Simulator
VLABench 基于 Mujoco 及其控制套件 dm control 构建。作者选择 Mujoco 作为基准测试的核心模拟平台,因为它设计轻量、性能高、物理真实感强。这些优点使得对各种算法的评估变得方便、快速。VLABench 框架高度模块化,意味着可以灵活地组合各种对象实体,以创建大规模和多样化的任务和场景。
Assets
为了满足多样化任务和能力评估的需求,作者围绕多个任务主题构建了资产库。从 Robocasa 继承了一些带注释的数据,并从 Objaverse 中获取了大量 3D 模型。对于新颖的任务,如围绕玩具主题创建的一系列任务,从在线 3D 模型网站收集了各种高质量的角色模型。然后使用 obj2mjcf 工具将这些模型转换为 MJCF 格式。使用生成式 AI 模型扩展了常见简单对象的数据集。利用 Tripo.aI 的文本转 3D 和图像转 3D 功能构建了其他 3D 对象,并利用 Runaway.ai 生成了多种材质纹理。最终,构建的资产库包含 163 类对象,共计 2164 个项目。
Robots
为了确保多功能性和广泛适用性,作者集成了一系列实例类型,包括但各种型号的 6 轴和 7 轴机械臂、双臂机器人、人形机器人等。在标准评估过程中,VLABench 采用配备平行夹持器的 7 自由度 Franka Emika Panda 机械手,使用 3D 坐标表示位置,使用四元数表示方向,在欧几里得空间 R3 中表示机器人末端执行器的位置和方向。然后,使用逆运动学,将这些末端执行器姿势解析为七个关节的相应旋转角度。
3.4. Dataset Construction
Domain Randomization
为了确保数据的多样性和丰富性,作者实现了各种类型的域随机化。这些随机化包括对象位置和方向、网格比例、场景布局、背景、对象纹理(如墙壁、地板和桌面)以及照明参数。
Trajectory Generation
由于真人遥操作耗时且不可扩展,作者基于自定义技能库开发了一种高效、可扩展的自动化数据收集流程。数据采集框架利用了先前的信息,包括环境点云、实体的抓取点、当前步骤的目标实体等。数据采集框架包括多个特定于任务的运动规划器。这些运动规划器根据当前任务进度调用技能库中的技能,并通过结合先验信息确定参数。随后选定的技能使用 RRT 生成轨迹,通过球面线性插值(Spherical Linear Interpolation, SLERP)实现四元数插值。使用贝塞尔曲线平滑最终轨迹以优化路径质量。为了提高数据采集的效率,设置了拒绝采样和故障触发的提前终止。
Instruction Augmentation
这里使用 GPT-4 生成包含目标特定特征和交互指令的描述,描述涵盖各种上下文信息和意图。
4. Experiments
按照第 3.2 节的内容,围绕预训练的 VLA 模型、包含多个算法模块的工作流程、各种 VLM 进行了实验。本节的其余部分详细介绍了实验设置。
4.1. Generalization Ability of VLAs
经过预训练的 VLA 有望具有与 LLM 类似的强大泛化能力和多功能性。实验旨在对 预训练的VLA 提出以下问题:
- 是否对未知类别的物体表现出更强的通用能力;
- 能否将通用知识和行为能力迁移到类似但未知的任务上;
- 能否理解用户交互中隐含的目标要求;
- 是否有潜力将其世界通识迁移到相关任务上;
- 现有的 VLA 架构能否准确支持长期任务;
Experiment Setup
作者在高质量数据集上对各种预训练的 VLA 架构进行了微调,包括 OpenVLA、Octo 、 RDT-1B。复合任务要求跨语言、视觉、常识和长远推理进行泛化,从而需要整合多种技能。为了评估泛化能力,作者选择原始任务作为评估基础,在每一类原始任务中,网格和基础纹理任务、世界知识任务以及语义任务使用相似的配置和轨迹。因此,选择在每个任务类别上对基础数据和常识数据进行联合训练,并在不同的设置下进行评估。在微调阶段,从每个任务类别中抽取 100 条轨迹,总共得到 1,600 条轨迹,以确保在任务之间的均衡表示。对于复杂的任务,在每个任务的领域内分别进行微调,并独立进行评估。
Result and Analysis
在评估阶段采用不同的任务设置来涵盖多种泛化能力。在Table.2 (s)中,通过评估可见和不可见物体类别,展示了视觉和常识泛化能力。实验结果表明,当前大规模预训练 VLA 并未表现出预期的对下游任务的快速适应能力。微调模型在原始任务中表现不佳,尤其是涉及 Pick&Place 的任务时。受离散化过程和单帧输入架构的限制,OpenVLA 的技能学习能力低于 RDT-1B。然而 OpenVLA 在涉及不可见物体的常识任务上取得了比 RDT-1B 更高的分数。作者认为,尽管 OpenVLA 在预训练期间仅拟合轨迹数据,但由于其backbone是 Llama2-7B 为其提供了更大的泛化潜力。
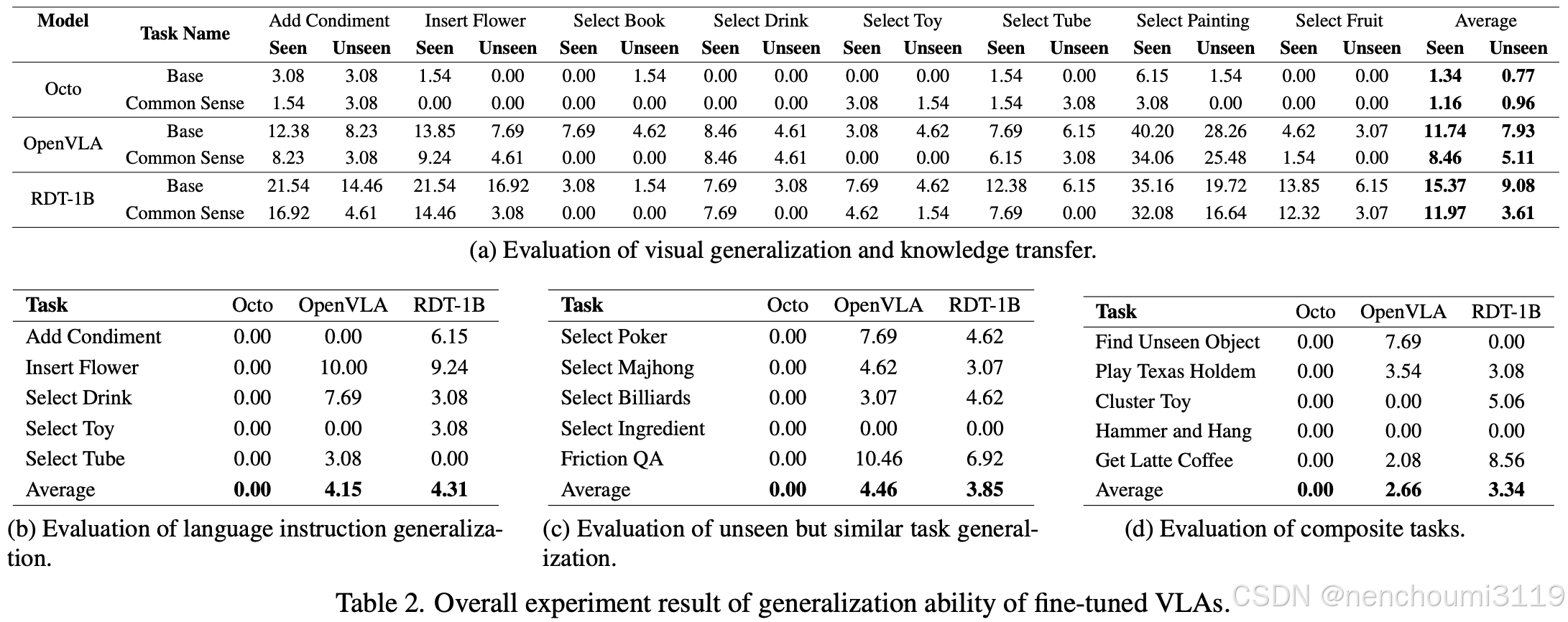
在Table.2 (b),(c),(d) 中,评估分别对任务领域以外语义的命令、未见过但相似的任务、复合任务展开测试。实验结果表明,当前的架构和预训练方法不足以使 VLA 模型具备更强的语义理解、技能迁移、长期规划能力。类似于 GPT-3 时代大型语言模型中预训练-微调的经典范式,仍然很难确定 VLA 在仅有几百万个稀缺样本、质量参差不齐的数据集上进行预训练获能获得多少能力。类比大型语言模型的发展轨迹,VLA 的现状还远未达到与 GPT-2 相当的水平。进一步的消融研究和分析在第 10.1 节中介绍。
4.2. Performance of Workflow Utilizing Foundation Model
为了评估基于基础模型的算法,作者选择了两个SOTA框架,Voxposer 和 CoPA ,比较结果如Fig.4 所示。鉴于 Voxposer 对LLM的依赖,作者评估了 Voxposer 在具备和不具备视觉感知能力的情况下的性能。虽然 Voxposer 在基本任务上表现良好,并取得了 30-40 的得分,但它由于其对 LLM 驱动的运动规划依赖经常导致抓取失败,因为有效抓取规划的信息有限,尤其是在非视觉环境中解释旋转时,因此总体得分较低。
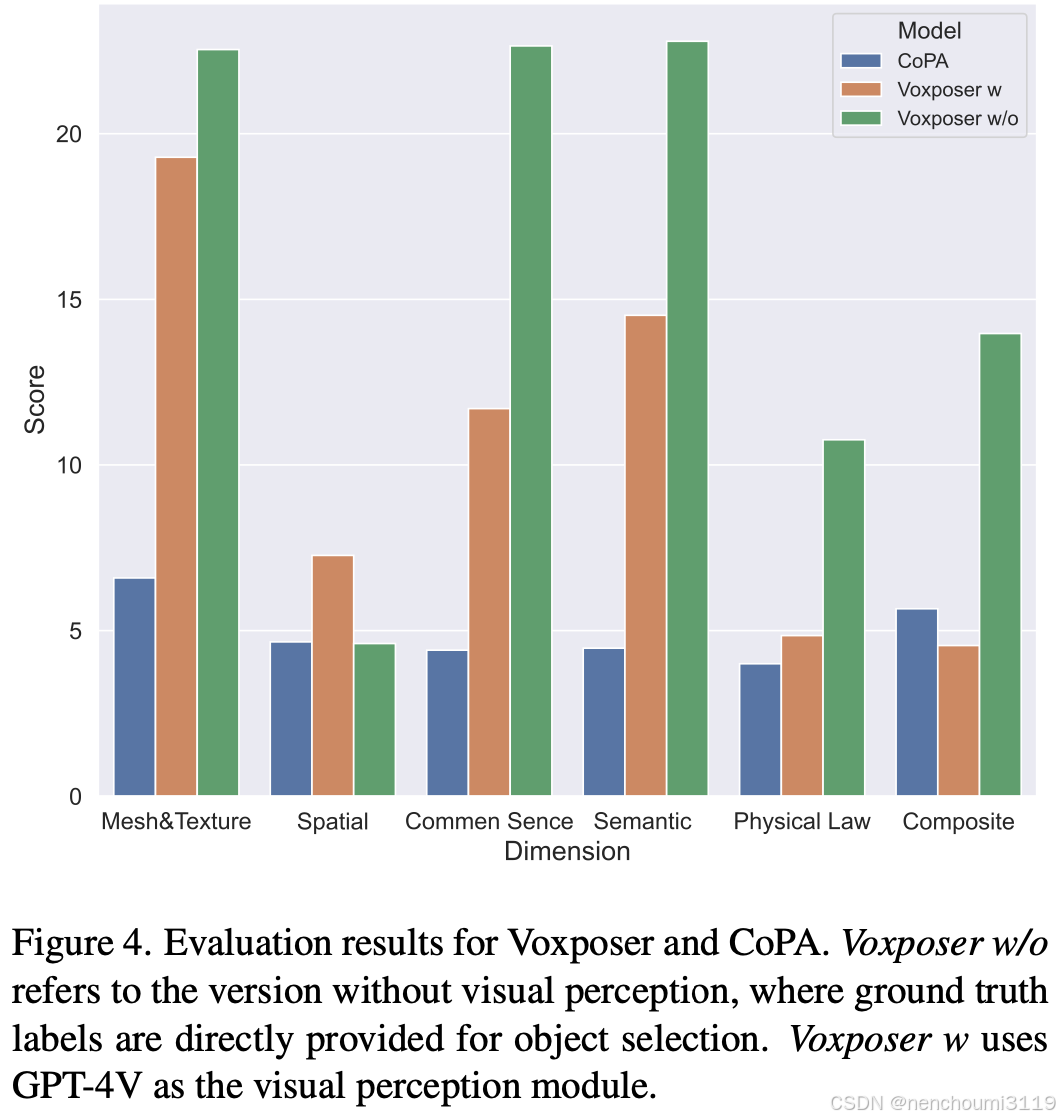
然而在没有视觉输入的情况下,LLM 单独在语义理解和推理任务中保持相对稳定的分数;增加视觉感知会略微降低语意理解能力但显著提高了空间推理能力,而由于缺乏空间信息,仅有LLM的设置难以实现空间准确性。
缺乏闭环反馈限制了这些模型执行物理推理任务的能力,特别是涉及动态交互的任务时得分较低。这两种模型在高复杂度任务上都表现不佳,虽然在物体识别方面取得成功,但在长期任务中表现不佳。该现象意味着需要推动基础模型框架解决复杂推理的发展要求。虽然上述方法强调了zero-shot能力和对新场景的泛化,但模块化设计往往限制了它们性能的上限。关于这一点的更详细讨论可以在第 10.2 节中找到。
4.3. Comprehensive Ability of VLMs
作者参考了 OpenCompass 提供的多个VLM的评测结果,并从不同系列中选取了几个整体表现优异的模型。这些模型包括:GPT-4-turbo-2024-0409、GPT-4o-2024-08-06、GLM-4V-9B 、MiniCPM-V2.6 、Qwen2-VL-7B、InterVL2-8B 和 LLaVA-NeXT 。作者使仿真环境中自带信息的数据集来评估这些模型的综合性能。数据集包含一组复杂的任务,旨在评估 VLM 视觉感知和理解口头指令的能力。VLM 的评估方法有两种:交互式和非交互式。下面将对这两种方法进行详细介绍。
Non-interactive Evaluation
Fig.6 说明了 VLABench 中为 VLM 专门设计的简化评估流程。首先,通过初始化一系列任务场景来生成评估数据集,每个任务场景都与两个四视图图相关联:一个带有掩码和标签注释用来识别不同的实体段,另一个没有注释的用作参考图像。如Fig.6 的数据制作模块所示。从 GPT4 中随机选择的与任务相关的语言指令伴随这些图表,形成视觉语言模型 (VLM) 的输入。
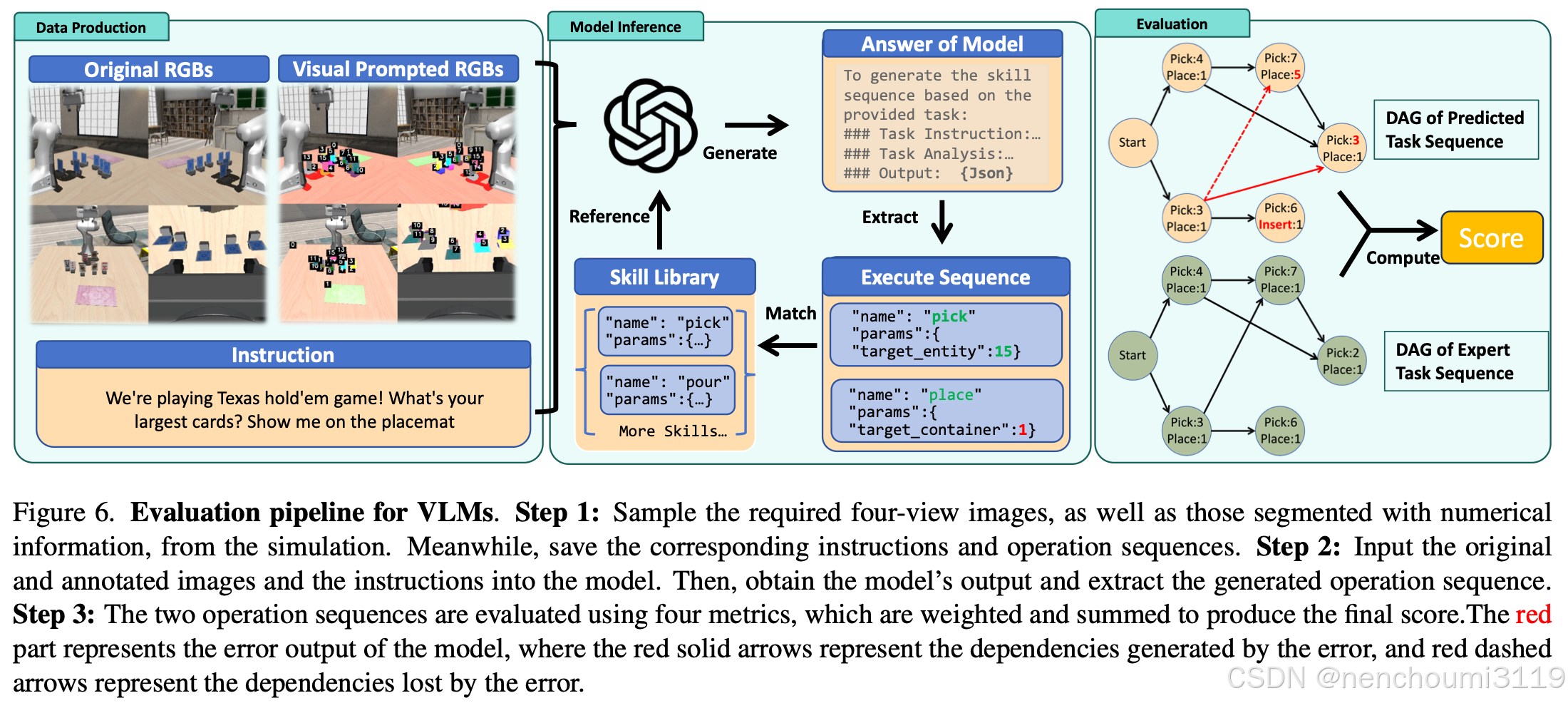
在推理期间,作者提供了技能库的详细描述、输出格式要求以及不同设置中的几个小样本示例。这些元素共同构成了查询 VLM 的系统提示。VLM 需要生成由一系列技能组成的 DSL 输出,其中每个技能都包含一个名称和相关参数,符合预定义的模式以实现系统评估。
然后,根据生成的技能序列的逻辑依赖关系,将其构建成有向图。将这些 DAG 与参考 DAG 进行匹配,并根据四个指标进行评分。最后,使用加权聚合将分数合并,以计算每个模型的总分。有关更详细的指标计算,请参阅补充材料中的第 9.3 节。
Interactive Evaluation
交互式评估根据与环境的交互计算任务进度分数。VLABench 提供了一个控制器将 VLM 输出的 DSL 动作序列解析为可执行动作,然后将其应用于模拟环境以与现实世界对象交互。这种方法是评估机器人操作任务的关键指标之一。与非交互式方法相比,它更耗时,而且其评估维度相对有限,因为它无法区分技能选择中的错误和参数生成中的错误。
Performance Comparison and Analysis
根据上一节概述的评估框架,作者从任务绩效的六个维度对模型进行了评估。Fig.5总结了 1-shot 设置下每个 VLM 模型的结果。
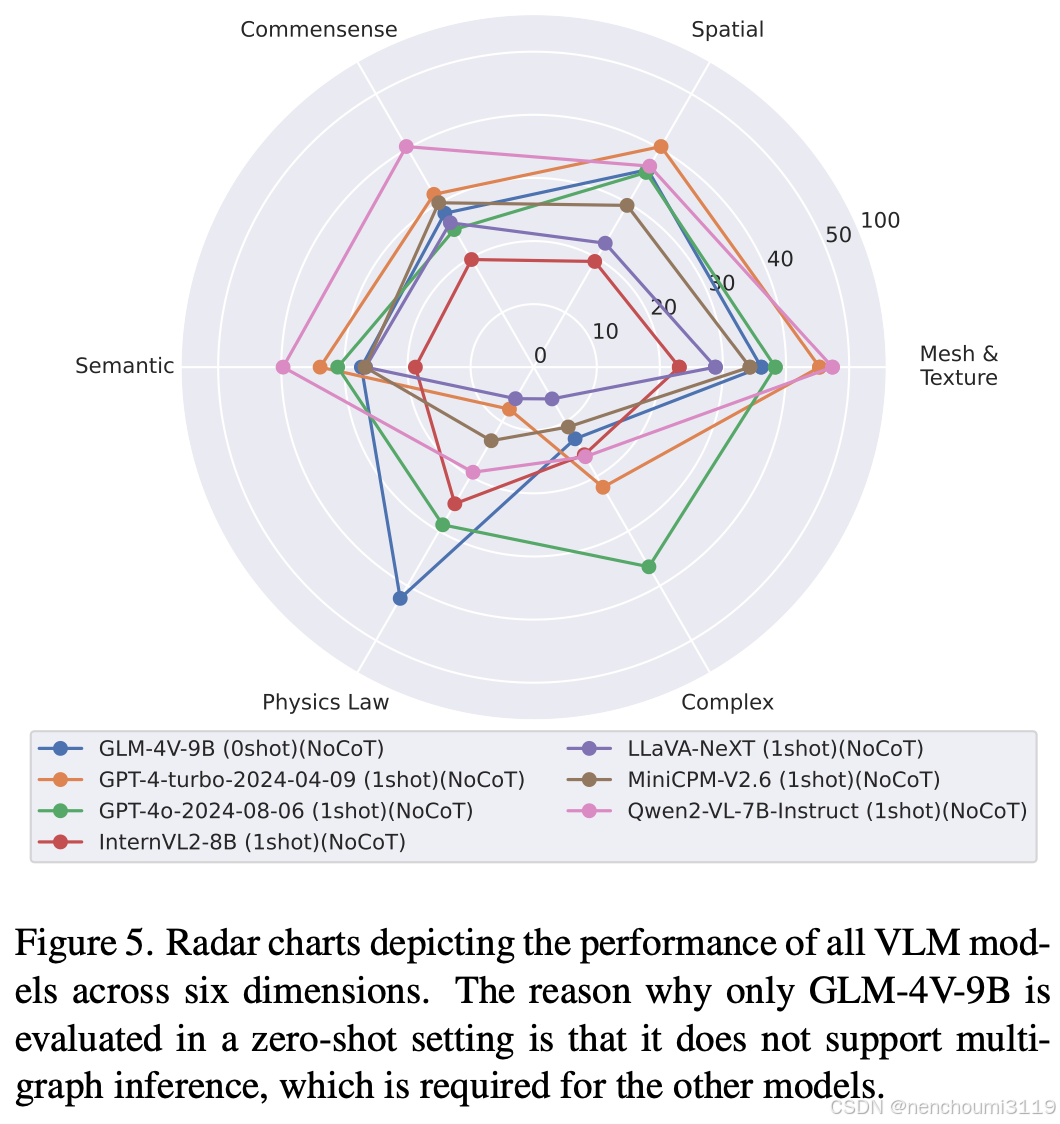
尽管这些 VLM 在大多数多模态任务甚至一些具身任务上表现良好,但它们的性能(包括 GPT-4o 的性能)在面对更复杂的场景、指令和更具挑战性的任务时就显得不足了。我们惊讶地发现,开源模型 Qwen2-VL-7B-Instruct 表现出色,在某些维度上超越了 GPT-4-turbo-2024-04-09。然而,所有模型在复杂任务方面都表现不佳,尤其是那些需要长期任务分解和逻辑推理的任务。只有 GPT-4o 在推理维度上的得分与其他维度相当,而其他模型的得分都在 20 分左右。此外,当语言指令从直接语义转变为抽象含义时,性能会显著下降,如语义维度所示。不同的模型似乎有不同的专业领域,例如LLaVA-NeXT 的空间感知能力较弱,GLM-4V-9B 在空间甚至物理定律维度上表现出色,但在语义理解方面落后。更多论述和讨论见第 10.3 节。总体而言,虽然这些模型表现出了良好的能力,但它们在具体环境中的理解和规划仍然有限,这凸显了进一步改进的必要性。
5. Conclusion
作者提出的 VLABench 是一个专为长期和多维推理任务而设计的大规模基准测试,包括从视觉到预训练阶段获得的知识、隐含语义中提取目标的能力、结合需求和交互场景做出合理决策、逻辑推理和制定长期计划的能力。作者最重要的贡献之一是通过提供 100 个标准化任务设置,对具有真正认知能力的智能代理应具备的能力及其应能够执行的任务提供积极的定义。此外,VLABench 构建了一个可扩展更大规模的自动数据采集框架,以及一个公平比较 VLA 能力的标准化数据集。实验表明,当前的 VLA 和 VLM 在该bench中的表现仍然有提升空间,并且在机器人扩展研究中仍然存在很大的不确定性。

















 844
844

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









