







这篇文章是来自中科院深圳先进院乔宇老师,ICCV2017年的oral文章《RPAN:An End-to-End Recurrent Pose-Attention Network for Action Recognition in Videos》。这篇文章的出发点是当前行为识别的一大流行方向:RNN。与之前的video-level category 训练RNN不相同。这篇文章提出了引入pose-attention的RNN。文章总结共有以下几个贡献点:
- 不同于之前的pose-related action recognition,这篇文章是端到端的RNN,而且是spatial-temporal evolutionos of human pose
- 不同于独立的学习关节点特征(human-joint features),这篇文章引入的pose-attention机制通过不同语义相关的关节点(semantically-related human joints)分享attention参数,然后将这些通过human-part pooling层联合起来
- 视频姿态估计,通过文章的方法可以给视频进行粗糙的姿态标记。(这个方法还挺不错)。
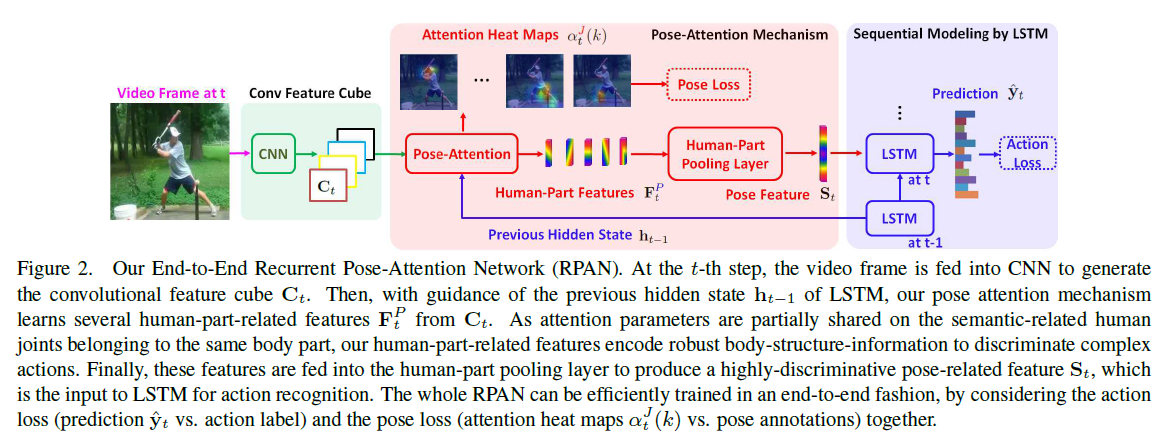
一、网络结构
整个网络框架可以分成三个大的部分:
- 特征生成部分:Conv Feature cube from CNN
- 姿态注意机制:Pose-Attention Mechanism
- LSTM:RNN网
下面是整体网络结构图。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3119
3119











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









