







 本文深入探讨了正态分布数据的贝叶斯决策理论,从单变量到多变量正态分布,解析其特点。通过理论推导,设计了一个基于最小欧式距离的贝叶斯分类器,并逐步弱化假设,引入马氏距离。文章揭示了在正态分布假设下,决策面是通过均值点连线中点的垂直线,形成了最小欧式距离分类器。
本文深入探讨了正态分布数据的贝叶斯决策理论,从单变量到多变量正态分布,解析其特点。通过理论推导,设计了一个基于最小欧式距离的贝叶斯分类器,并逐步弱化假设,引入马氏距离。文章揭示了在正态分布假设下,决策面是通过均值点连线中点的垂直线,形成了最小欧式距离分类器。
贝叶斯是非常传统,理论简单,但是非常有效的一种机器学习方法。经过大量实验表明,贝叶斯方法是极具鲁棒性的。至今为止仍然有很多人在研究贝叶斯的基础理论,而且发现许多算法都可以由贝叶斯推导而来,所以贝叶斯是具有极大的研究价值的理论。
这一章节我们就来扯一扯正态分布数据的贝叶斯决策理论,看看我们能搞点什么事情出来。自己多多推导,没准能发现新的大陆。许多优秀的算法,比如SVM等等往往就是这样诞生的。
这一节因为推导的东西比较多,可能很枯燥。所以先搞个大纲出来,看看我们接下来要搞点什么事情。
- 正态分布
- 单变量正态分布
- 多变量正态分布
- 正态分布的特点
- 贝叶斯分类器设计
- 理论推导
- 简化case1:最小欧式距离
- 简化case2:马氏距离
- General
主要就是这样一个构架了,谈正态分布的贝叶斯决策,显然我们得谈谈正态分布,然后由此出发,我们从最简单的case(增加各种假设条件,得到一个最简单的模型),然后依次General。
闲话少说,开始我们的旅程吧。
一、正态分布
这里不是将概率论,详情请看我们写的数学系列教程。这里我们从需求出发,简单阐述单变量正态分布、多变量正态分布,最重要的是阐述一下正态分布的特点。
1.1 单变量正态分布
首先,搞个热身运动。下面是最简单的单变量正态分布。
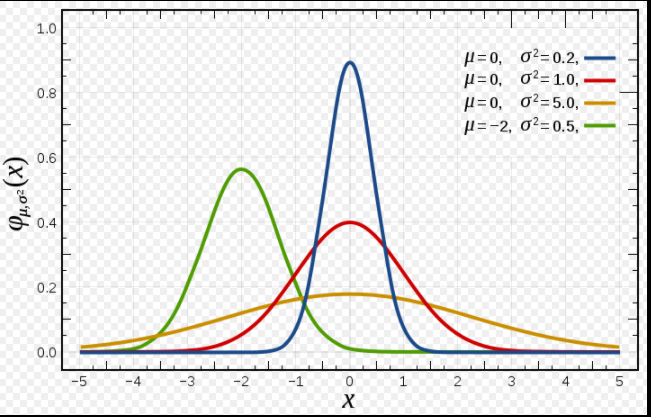
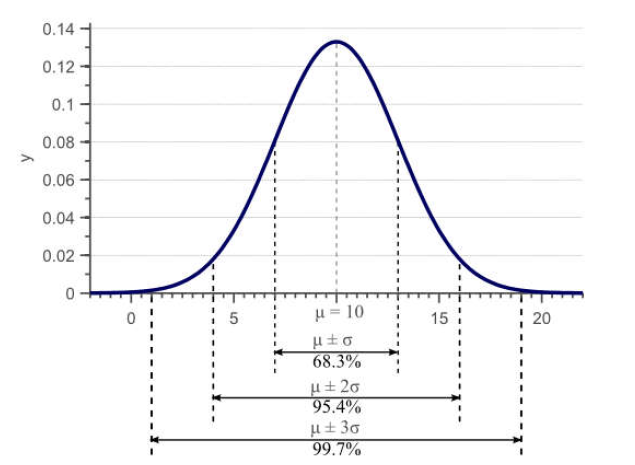
其中:
- Pdf(单变量概率密度函数)
p(x)=12π−−√σe{
−12(x−μσ)2} p ( x ) = 1 2 π σ e { − 1 2 ( x − μ σ ) 2 }
- Mean Vector (均值)
μ=E{
x}=∫xp(x)dx μ = E { x } = ∫ x p ( x ) d x
- Variance(方差)
σ2=E{
(x−u)2}=∫(x−μ)2p(x)dx σ 2 = E { ( x − u ) 2 } = ∫ ( x − μ ) 2 p ( x ) d x
- 数学表达式
p(x) N(μ,σ2) p ( x ) N ( μ , σ 2 )
1.2 多变量正态分布
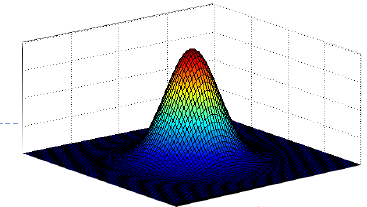
- 多变量pdf表达
p(x)=1(2π)1/2|∑|1/2exp{
−12(x−μ)T∑−1(x−μ)},x∈Rl p ( x ) = 1 ( 2 π ) 1 / 2 | ∑ | 1 / 2 exp { − 1 2 ( x − μ ) T ∑ − 1 ( x − μ ) } , x ∈ R l
- Mean Vector(均值)
μ=E[x]=E[x1,x2,.....,xl] μ = E [ x ] = E [ x 1 , x 2 , . . . . . , x l ]
- Convariance matrix (协方差矩阵)
∑=E[(x−μ)(x−μ)T](1) (1) ∑ = E [ ( x − μ ) ( x − μ ) T ]
=⎡⎣⎢⎢⎢⎢⎢⎢σ211σ221⋮σ2l1σ212σ222⋮σ2l2⋯⋯⋱⋯σ21lσ22l⋮σ2ll⎤⎦⎥⎥⎥⎥⎥⎥ = [ σ 11 2 σ 12 2 ⋯ σ 1 l 2 σ 21 2 σ 22 2 ⋯ σ 2 l 2 ⋮ ⋮ ⋱ ⋮ σ l 1 2 σ l 2 2 ⋯ σ l l 2 ]
- 数学表达
p(x) N(μ,Σ) p ( x ) N ( μ , Σ )
1.3 正态分布的特点
- K K 个参数(均值和方差)决定 的正态分布
K=l+l (l+1)/2 K = l + l ( l + 1 ) / 2
- 超椭球面(super-ellipsoid)上点概率值相等
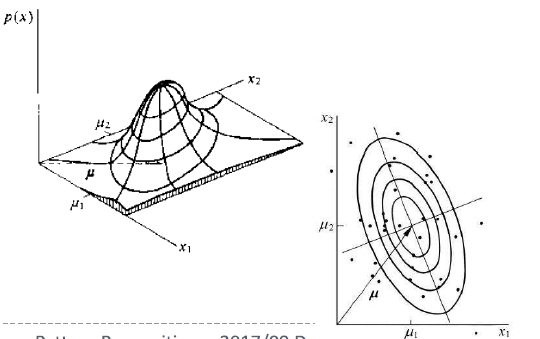
- 协方差矩阵的特征向量决定主轴,而且主轴的长度和协方差矩阵的特征向量是成比例的。
- 对于正态分布来说,不相关和独立是相等的
- 如果x是独立的,那么协方差矩阵是对角矩阵
二、贝叶斯分类器设计
这一小节的目的是:在输入 x x 是正态分布的前提下(假设输入的变量是服从正态分布的),设计一个最小误差MPE贝叶斯分类器。
2.1 理论推导
这里,我们考虑每个类别数据都是服从正态分布的。同样的,我们判决函数用 函数,那么我们能得到如下的决策函数。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1340
1340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









