






Published in 2023-06-26
Proceedings of the AAAI Conference on Artificial Intelligence
论文地址: Compressing Transformers: Features Are Low-Rank, but Weights Are Not!
Author
Hao Yu, Jianxin Wu*
State Key Laboratory for Novel Software Technology, Nanjing University, China
Abstract
Transformer及其变体在CV和NLP中表现良好,但高昂的计算成本和对大型训练数据集的依赖限制了它们在资源受限环境中的部署。模型权值的低秩近似在压缩CNN模型中是有效的,但其在Transformer中的应用研究较少,效果也较差。现有的方法需要完整的数据集来微调压缩模型,这既耗时又需要大量数据。本文揭示了特征(即激活)是低秩的,但令人惊讶的是模型权重不是低秩的。因此,提出了自适应确定压缩模型结构的AAFM算法,该算法局部压缩每个线性层的输出特征,而不是模型权值。第二阶段,GFM,从整体上优化整个压缩网络。AAFM和GFM都只使用少量无标签的训练样本,即few shot、无监督、快速、有效。例如,在只有2K张没有标签的图像时,DeiT-B中删除了33%的参数,相对吞吐量(throughput)增加了18.8%,而ImageNet识别的准确率仅下降了0.23%。所提出的方法也成功地应用于自然语言处理中的语言建模任务。此外,few shot压缩模型在下游任务中泛化良好。
Background
大多数基于transformer的结构都存在模型size大、运存消耗大和计算成本高的问题,这使得模型无法部署到资源受限的平台上。因此,压缩transformer变得吸引关注。
低秩近似(Low-rank approximation)可以打破模型accuracy与size之间的平衡,一些NLP的工作对模型权重因式分解(factorization),确实减小了模型尺寸并加速推理,但是accuracy掉的比较大,因此需要用整个训练集来fine-tuning许多epochs来补回accuracy,然而为了数据隐私或者尽快部署,只能使用原始模型和少量samples,但fine-tuning一个大的模型却只用有限数据,容易导致过拟合,并且这些方法只是压缩了transformer本身,没有探索压缩模型怎样在下游任务上起作用。
最后,自动确定每一层的压缩比是低秩分解的主要难点之一,但在这方面的努力还很少。
Motivation
我们需要一个在CV和NLP都能应用的模型压缩方法,且该方法只需要较少的样本和较短的压缩时间,可以自适应地确定压缩模型结构,并能很好地推广到下游任务。
Contributions
- 作者发现,即使在transformer的线性层中权重矩阵几乎满秩(不适合分解),但是features(像activations)总体低秩,因此,提出了Atomic Feature Mimicking (AFM) 来局部代替传统的weight approximation方法。并且,因为不同的层有不同的压缩敏感性,设计了一种自适应搜索方法Adaptive AFM (AAFM)来确定压缩模型结构;但是随着深度的增加,approximation的误差也在累积,因此提出了Global Feature Mimicking (GFM)来只使用少量的无lable数据来fine-tune压缩模型;
- 压缩模型参数少、吞吐量高,但能达到跟原始模型相当的accuracy;
- 框架是few-shot、无监督的、快速的,给定预先设定的压缩目标和少量未标记的样本,我们的方法可以快速确定子模型架构并微调压缩模型。不引入额外的超参数
- 压缩模型可推广到多个下游任务,即使是few-shot的设置,也能达到对压缩模型的很好泛化。
Method
preliminaries
如果使用奇异值分解,将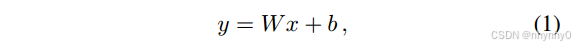
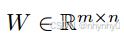
分解为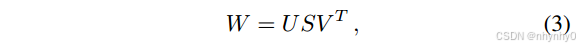
并且只使用奇异值中最大的k项,则得到的矩阵是lower rank k < n 的对W的最优逼近,
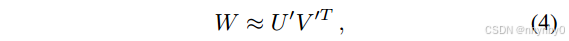
并且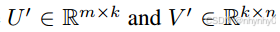
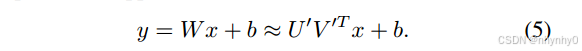
参数量确实由O(mn)下降为了O(k(m+n)),但是在transformer及其变体中,W几乎满秩,所以如果我们把一个FC层变为两个,要么选用小一点的k然后掉很多accuracy,要么使用较大的k但是要增大模型尺寸。
Atomic Feature Mimicking (AFM)
介于上述思考,作者决定不分解模型权重,而是分解输出特征,由于仅在一个单独的层里面模拟特征并没有牵扯到其他层,因此是atomic。
把输出特征的
R
m
×
c
\mathbb{R}^{m \times c}
Rm×c当作c个随机的特征向量
y
y
y,每个都是
R
m
\mathbb{R}^{m}
Rm,然后计算它们的协方差矩阵,
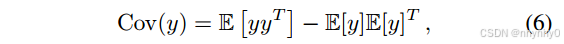
因为
C
o
v
(
y
)
Cov(y)
Cov(y)是 positive semi-definite(半正定的),因此其特征分解为
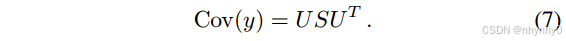
拿出k个最大的奇异值,并把
U
∈
R
m
×
m
U\in \mathbb{R}^{m \times m}
U∈Rm×m拿出前k列,变成
U
k
∈
R
m
×
k
U_k\in \mathbb{R}^{m \times k}
Uk∈Rm×k,并且
U
k
U
k
T
≈
I
U_kU_k^T \approx I
UkUkT≈I,因此
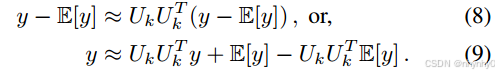
然后一个线性层就可以拆成两个
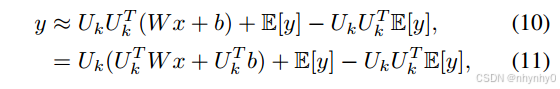
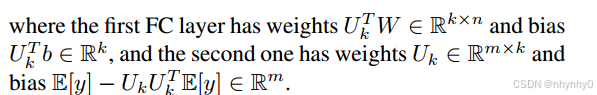
为了计算协方差矩阵,从训练数据集中随机选择了少量样本来建立起一个代理数据集
D
D
D,只在一次前向中,我们就可以聚集输出特征来计算所有FC层中的协方差矩阵,并且分解FC层。并且以streaming的方式而不是储存所有输出特征来更新
E
[
y
y
T
]
\mathbb E[yy^T]
E[yyT]和
E
[
y
]
\mathbb E[y]
E[y]。

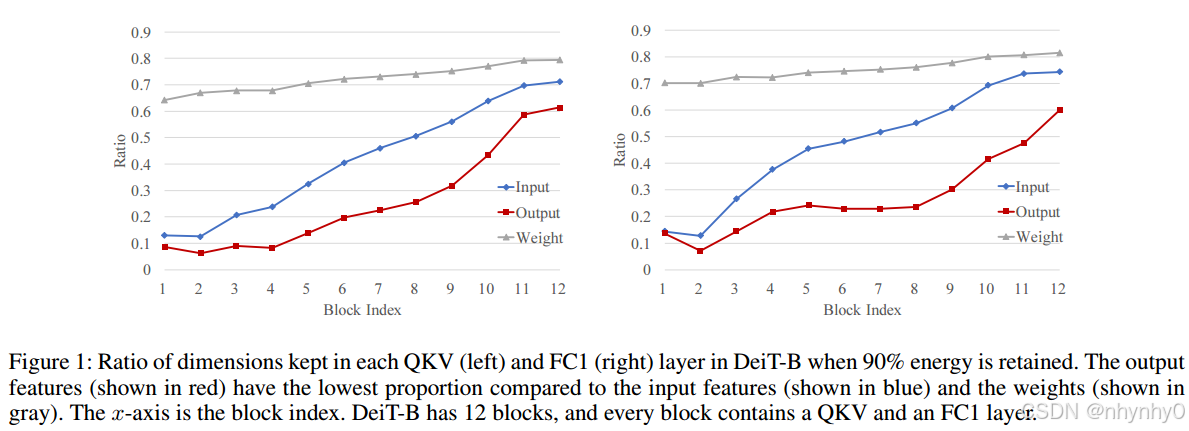
在下图中,我们把Image-Net-1k的validation set输入DeiT-B,收集每个block中QKV和FC1层的输入和输出特征,分别计算这些特征的协方差矩阵和特征值,并通过SVD分解QKV和FC1的权重,查看要达到90%的energy,要保持的特征或者奇异向量的的百分比,如Fig 1所示,当保持90%energy的时候,输出特征要求的维度比输入特征和权重要少,也就说明输出特征相比于模型权重更低秩。
其中,DeiT-B包括attention layer和Feed-Forward Network (FFN)两个主要组分,每个组分包括两个FC 层,把attention layer的FC叫做QKV 和 PROJ,把FFN中的叫做FC1 和FC2。
Adaptive Atomic Feature Mimicking (AAFM)
这里的adaptive主要指找到不同的层所对应的rank k的值,基本思路是保持更高的rank k或者不压缩那些比较敏感的层,给那些不太敏感的层压缩程度更大。
为了衡量不同层的敏感性,应用上文中的代理数据集
D
D
D,拆出原始模型
M
M
M的输出logits,然后在一单独的层里面评价使用AFM前后的表现变化,为最大化GPU利用率、降低搜索开销,将 k 固定为32的倍数,然后在是否使用AFM的两个模型之间给每层单独计算sensitive score(KL散度),
S
i
(
k
)
S_i(k)
Si(k)指第i层在rank 为 k时的sensitive score,
w
i
(
k
)
w_i(k)
wi(k)指压缩模型在第i层rank 为k时的权重,
S
i
(
k
)
S_i(k)
Si(k)越大,压缩模型与原始模型的差异越大,也就说明越敏感。
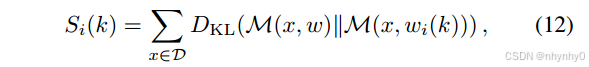
在获得不同 rank k的sensitive score之后,给定一个目标模型尺寸
P
t
a
r
P_{tar}
Ptar,最小化所有层的sensitive score的总和
S
S
S,
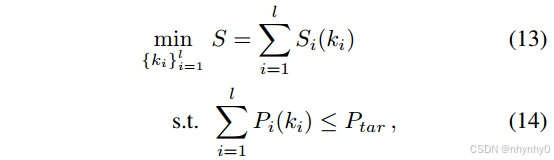
P
i
(
k
i
)
P_i(k_i)
Pi(ki)是rank 为
k
i
k_i
ki时第i层的参数数量,
l
l
l是所有linear layer的总数。该AAFM是通用的,可以根据给定的不同
P
t
a
r
P_{tar}
Ptar从一个训练好的large model中产生多个子网络。
因为
k
i
k_i
ki是整数,因此这是一个整数规划问题,通过一个贪心策略来近似地解决,作出一个简化假设:某一层的sensitivity与其他层所选择的rank 无关。该贪心算法不能保证找到最优解,但可以加速搜索,从所有可能的rank的配置中找到全局最优解太耗时了。
Global Feature Mimicking (GFM)
AAFM在每一层都有一些小的error,逐层累计,于是使用GFM来在AAFM后去除这些error。
GFM使用代理数据集
D
D
D来作为few-shot examples,在GAP之前的倒数第二层模拟输出特征,使用均方误差MSE来衡量差距,
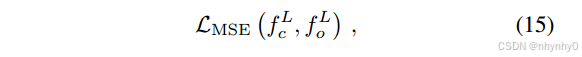
其中
f
c
f_c
fc和
f
o
f_o
fo分别指压缩模型和原始模型,
L
L
L指被模拟输出特征的那一层,在ViTs中,
f
L
f^L
fL指最后的LN层输出的feature map,在语言模型中,指在最后一个block之后但是softmax之前。GFM是不包括分类的FC层的。
Method Summary
首先使用AAFM确定子模型架构,即在满足模型尺寸的前提下,找到使得所有层的sensitive score总和最小的所有k的取值,即此时压缩模型与原始模型的差异最小,然后基于AFM中的方式对feature map进行特征分解,最后使用GFM来fine-tuning整个压缩模型。只利用了无label的数据集
D
D
D,是few-shot并且快速的,只需要预定义好模型尺寸即
P
t
a
r
P_{tar}
Ptar就好,不引入其他超参数。
下述是我自己写的一个伪代码:

Experiments
首先在ImageNet-1k的分类任务上压缩DeiT和Swin ViT,接着在小规模分类和目标检测的下游任务上进行验证。所有的实验都是通过Pytorch实现的。
Datasets and Metrics
Classification
使用ImageNet-1k数据集,包括1.28 million训练数据,50k 的validation,共有1k个类别,图片有不同的空间分辨率,ImageNet-1k常作为模型压缩的benchmark。
Objection Detection & Segmentation
使用MSCOCO-2017数据集,包括80个类别,118K训练图片,5K验证samples,使用mean Average Precision (mAP)来衡量accuracy.
Language Modeling
在WikiText-103数据集上评估,由打乱的Wikipedia文章组成,训练集包括28K篇文章和100M个tokens,接近260K个词汇,测试集包括245K个tokens和4358个句子,使用perplexity(困惑度)来评价模型表现,困惑度越低说明效果预测效果越好。
Compressing DeiT & Swin
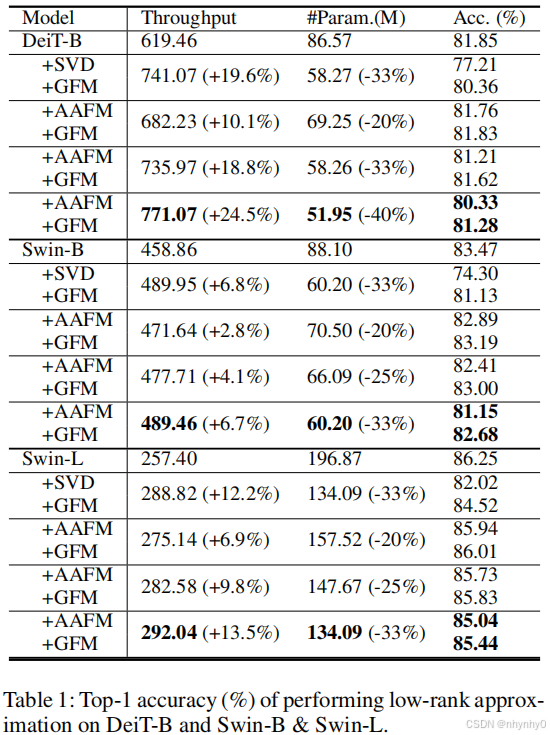
从ImageNet-1k的训练集中拿出2k张图片来组成代理数据集 D D D,由于模型越大参数冗余越多,因此在DeiT-B和Swin-B & L上测试AAFM和GFM的表现效果。
Implementation details
应用AAFM时,采用不同的压缩比例,Swin-B & Swin-L中1/5,1/4, or 1/3的参数被移去,DeiT-B中1/5,
1/3, or 2/5的参数被移去,只压缩block中的4个FC层,用8个3090 GPU来计算sensitive score,对去除了40%的DeiT-B进行AAFM压缩用了0.6h,为对比,还对原始transformer模型进行了SVD作为baseline,即保留了transformer块中每个FC层的一半奇异值。
然后使用GFM在代理数据集上fine-tuning子模型,对DeiT-B,学习率8e-5,batch size 512,Swin-B & Swin-L学习率3e-5,batch size 256,使用AdamW优化器和余弦衰减调度,训练1000个epoch,数据增强有Random horizontal flipping, color jittering, Mixup and CutMix,由于强正则化会恶化后续训练中的模型表现,于是去除了random erasing, Rand-Augment and layer dropout。
Results
在ImageNet-1K validation dataset上测试,短边通过双线性插值成256,然后224x224的中心crop,报告最后一个epoch的accuracy,和512batch size的的3090吞吐量。
在DeiT-B中移除40%的参数,吞吐量提高24.5%,减少0.57%accuracy。对Swin-B有类似的效果,证明AAFM比传统的SVD表现更好,并且即使是在大数据集 ImageNet-21K上预训练的Swin-L也效果良好。
Transferring Ability
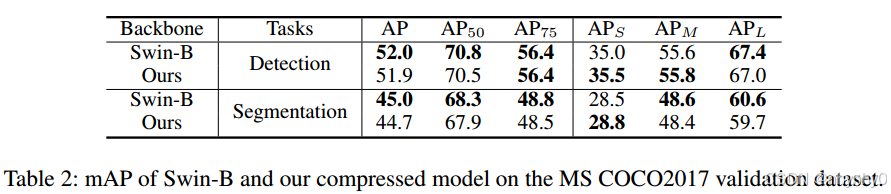
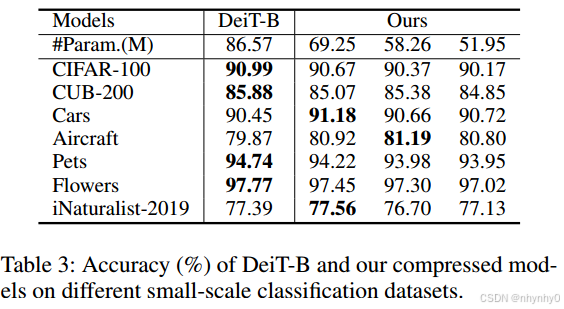
在下游任务上测试性能,在MS COCO2017 detection and segmentation上探索Swin-B的mAP,在小规模分类数据集上测试压缩后DeiT-B的accuracy。
Implementation details
把原始的Swin-B和移除33%参数的Swin-B作为Cascade Mask R-CNN的backbone,按Swin Transformer论文中的training设置。
Results
压缩后的Swin-B与原模型mAP相当。
压缩模型与DeiT-B的accuracy相似,在某些数据集上,甚至比原模型效果更好。
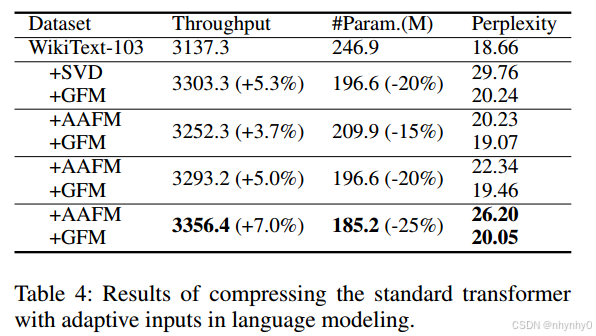
Compressing Transformer for NLP Tasks
在WikiText-103数据集上压缩标准transformer,困惑度与原始模型相当。
Implementation details
原始的transformer架构是Baevski and Auli (2018)中的,包括16个decoder block和正弦位置编码。采样4000个句子构成代理数据集,分别减少15%,20%,25%的参数量。
线性warm up然后退火的使用余弦调度,
Results
效果仍与原始模型相当。
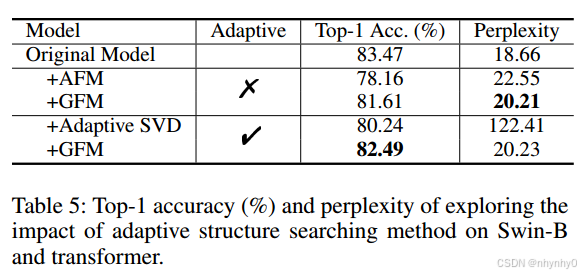
Analyses
1. The influence of AAFM
使用Swin-B 和在WikiText-103上训练的transformer,分别去除33%和20%的参数。
第一个使用AFM,同时保留模型块中每个FC层的一半维度,而第二种方法利用AAFM搜索的模型结构,但使用SVD初始化子模型,称其为adaptive SVD,结果如下图,与Table 1 结合对比,AFM效果比SVD更好,但比AAFM差,并且找到的模型结构泛化性良好,Adaptive SVD比传统SVD效果好。
2. Knowledge distillation
使用Swin-B和transformer分别移除33%和25%的参数,比较fine-tuning子模型时的不同蒸馏方式:
- Soft distillation
q是教师模型softmax之后的输出,p是压缩后的子模型输出,y是真正的label,软蒸馏的目标是:
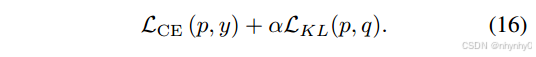
- Soft distillation without label
损失函数是 L K L ( p , q ) L_{KL}(p,q) LKL(p,q) - Hard distillation
y ( t ) = a r g m a x ( q ) y(t)=arg max(q) y(t)=argmax(q)作为教师的hard decision,硬标签蒸馏的损失函数是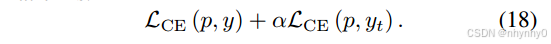
- Hard distillation without label
损失函数是 L C E ( p , y t ) L_{CE}(p,y_t) LCE(p,yt) - GFM with labels
把label信息加入GFM。
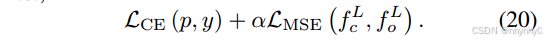
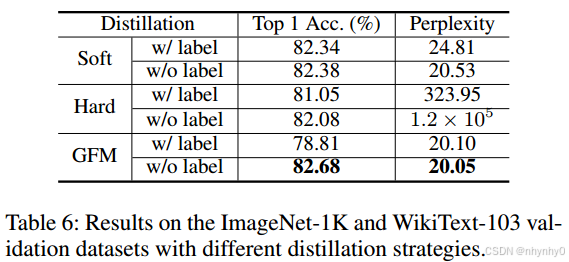
将 α \alpha α设为了1.0,结果如下图,在few-shot的时候,包括label信息来训练压缩模型很容易导致过拟合,但是GFM效果仍然好。
3.The proxy dataset size
使用Swin-B移除33%的参数进行实验,将代理数据集
D
D
D的尺寸分别设为1K,2K,5K,10K,100K和整个训练集,连续应用AAFM和GFM。结果如下所示,表明该算法不需要利用太多无label样例,尽管随着数据集增大效果提高,但提高有限。

Future Work
由于低秩分解把一个线性层分成了两个,故并未显著提高吞吐量,未来可以考虑如何应用低秩分解来加速推理。并且,代理数据集是随机选择样本产生的,可以探索代理数据集中数据分布的影响。此外,该方法理论上可以应用于各种深度学习模型,例如cnn,可以继续扩展。
Questions
-
compress(压缩)
模型压缩目标:
(1)减少模型显存占用;
(2)加快推理速度;
(3)减少精度损失。模型压缩算法分类(如何降低权重和激活成本):
(1)模型量化(quantization):旨在通过减少模型参数的表示精度来降低模型的存储空间和计算复杂度;
(2)参数剪枝(pruning):旨在通过删除模型中的不重要连接或参数来减少模型的大小和计算量;
(3)知识蒸馏(knowledge distillation):指通过构建一个轻量化的小模型,利用性能更好的大模型的监督信息,来训练这个小模型,以期达到更好的性能和精度;
(4)低秩分解(low-rank factorization):旨在通过将模型中的大型矩阵分解为低秩的子矩阵,从而减少模型参数的数量和计算复杂度。在低秩分解中,矩阵被分解为两个或多个低秩矩阵的乘积形式。模型压缩通常处于机器学习模型训练和生产部署之间的阶段。它在模型训练完成后,准备将模型部署到目标环境之前进行。
-
SVD(Singular Value Decomposition)
矩阵分解的一种方式,将一个mxn阶矩阵 M M M,分解为 M = U ∑ V ∗ M=U\sum V^* M=U∑V∗,其中U为mxm阶酉矩阵(共轭转置恰为其逆矩阵),V为nxn阶酉矩阵, ∑ \sum ∑为对角矩阵对角线上的元素即为M的奇异值。
对称矩阵的奇异值分别为其特征值的平方根。
谱分解,是说任何实对称矩阵都可被正交矩阵对角化, A = Q Λ Q T = Q Λ Q − 1 A=Q\Lambda Q^T=Q\Lambda Q^{-1} A=QΛQT=QΛQ−1,是奇异值分解的特殊情况 -
FWSVD (Hsu et al.2022) 引入的 Fisher information
费雪信息量用来估计参数的重要性,信息量越大,对参数的估计越准确,但是要求大量的有label数据来fine-tune压缩模型 -
为什么在Eq.3 只使用最大k个奇异值的话就可以变成Eq.4 ,而且为什么是rank k < n的最优近似?
通过奇异值分解,可以得到最优r秩近似,这里应该就是这样的过程,但是为什么会写成这个样子呢,按照Eckart-Young-Mirsky定理的话,不是应该得到下式吗?

-
Eq.7怎么得到的
C o v ( y ) Cov(y) Cov(y)是一个半正定矩阵,半正定矩阵首先是对称矩阵,且对任何非零向量z,都有 z T M z ⩾ 0 z^TMz \geqslant 0 zTMz⩾0,因为它是对称矩阵,所以可以采用谱分解将其对角化,即 C o v ( y ) = U S U T Cov(y)=USU^T Cov(y)=USUT -
Eq.7之后为什么 U k U k T ≈ I U_kU_k^T \approx I UkUkT≈I
因为特征分解中使用的U是正交矩阵,而正交矩阵有 U T = U − 1 U^T=U^{-1} UT=U−1,故 U U T = U U − 1 = I UU^T=UU^{-1}=I UUT=UU−1=I,其中 I I I是单位阵,故挑选出来前k个特征值的矩阵与其转置相乘,对角线上的元素肯定也为1,但是因为少了其他特征值所在行的影响,非对角线元素不一定全为0,因此近似为单位阵 -
Fig 1中所保持的energy指什么,是说accuracy吗?
Fig 1想强调的是说相比于权重,特征更加低秩,因此选择使用特征模拟更便于进行特征分解,感觉像是在模型参数量压缩为原来的90%,然后才能查看特征里面谁更低秩,如果是accuracy的话,首先维持accuracy是原来的90%就比较难,需要不断进行实验然后根据accuracy结果调整模型,很难完成这个对比实验。 -
KL散度
也叫相对熵,两个分布之间的差异程度越大,散度越大 -
mAP
AP与AUC相似,计算Precision为纵轴Recall为横轴时曲线下的面积,在目标检测任务中,通过设置不同的IOU阈值,通过置信度确定预测结果是否正确,从而找到不同的Precision和Recall的对应关系,从而绘制出图像,通过计算所有类别的AP再求平均,得到mAP -
warm up 、退火、余弦退火
warm up 最早是在 ResNet 论文中提出来的,用于优化学习率,刚开始训练时,由于模型权重是随机初始化的,使用较大学习率容易导致模型振荡,因此选用较小学习率,使模型慢慢趋于稳定,随着迭代次数增大,学习率按照1/warmup_steps 线性增大,迭代 warmup_steps 次后,学习率为初始预定学习率,接着学习率进行衰减,衰减率为1/(total-warmup_steps),再进行微调。退火算法包含两个部分即Metropolis算法和退火过程,,分别对应内循环和外循环。外循环就是退火过程,将固体达到较高的温度,然后按照降温系数alpha使温度按照一定的比例下降,当达到终止温度时,冷却结束,即退火过程结束。Metropolis算法是内循环,即在每次温度下,对旧解添加随机扰动得到新解,并按一定规则接受新解。当新解优于旧解时,接受新解,当新解差于旧解时,按照一定概率接受新解,防止陷入局部最小值。
余弦退火是指在 warm up 过程中学习率到达初始预定后衰减的过程中,按照余弦函数的方式来降低学习率,先缓慢下降,再加速下降,再缓慢下降,如下图所示;

-
保留模型块中每个FC层的一半维度是什么意思,起什么作用
个人理解,这里的保留一半维度是作为压缩的一种方式,因为在 Analyses 1 中,作为探究AAFM的影响的对比实验,采用AFM只是对 feature 进行模拟而没有对权重模拟,但是仍然没有进行压缩过程,这里的保留一半维度应该指将其 feature 的维度调整为之前的一半,应该不会是直接删除一半维度吧 ,可能有别的一些什么方法。’
补充: 又读了一遍之后,这里的压缩一半维度是作为AFM或者SVD不采用AAFM的一种对比方式,用来减少模型大小,形成对比,应该是直接使用一半的奇异值进行最优近似,没有像AAFM那样对不同层采用不同的rank。 -
软蒸馏、硬蒸馏
蒸馏的过程是训练出教师模型,然后教师模型来指导训练学生模型,基于真实 label 同时更新教师模型和学生模型。
这里的软蒸馏是指教师模型产生的标签是软标签,硬蒸馏指教师模型产生的标签是硬标签,软标签是各个分类的概率,硬标签就是分类,教师模型是根据真实label来优化自己的输出标签,学生模型是既要去模拟教师模型也要去模拟真实label,损失由两部分组成。 -
GFM本来fine-tuning没有加入label吗?
GFM本来训练过程中,是利用原始模型对代理数据集 D D D的输出特征来指导压缩模型学习输出特征,并没有使用label,而在 Analyses 2 知识蒸馏的对比实验中,加入 label 指导训练后,压缩模型效果反而下降。
Preferences
- 大模型学习路线(5)—— 大模型压缩(量化、剪枝、蒸馏、低秩分解),推理(vllm)
- 奇异值分解
- SVD近似
- Fisher Information
- 正定矩阵与半正定矩阵
- KL散度详解
- warm up
- 退火算法
- 模拟退火算法
- 余弦退火
- 软蒸馏、硬蒸馏
Summary
这篇文章的突出点在于对特征进行分解,而不是对权重分解,没有主动地去删除一些层,只有根据不同层的敏感情况来确定其压缩程度,再通过AFM方式进行压缩,结果证明对特征分解的方式效果较好,且可以泛化到不同的任务上去,个人感觉可以将其作为低秩近似的一种方式,与其他压缩的方式进行结合。但是感觉它可能不太容易控制压缩尺寸,因为它这个k值是事先给定一系列的k,然后在满足 P t a r P_{tar} Ptar的条件下通过AAFM找到的一组k值,使得此时每层的sensitive score 最小,由于未考虑不同层之间的影响,模型架构不一定是当前的最优架构,并且并不是dense的压缩方式。

















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









