







 本文介绍了Warmup学习率预热方法,探讨其在神经网络训练中的作用,包括防止过早过拟合、模型稳定性提升以及不同实现方式如常量预热和渐进预热。还对比了optimizer.step()和scheduler.step()的差异,以及如何在实践中运用Warmup技术来优化模型性能。
本文介绍了Warmup学习率预热方法,探讨其在神经网络训练中的作用,包括防止过早过拟合、模型稳定性提升以及不同实现方式如常量预热和渐进预热。还对比了optimizer.step()和scheduler.step()的差异,以及如何在实践中运用Warmup技术来优化模型性能。
一、warmup是什么?
Warmup是针对学习率优化的一种方式,Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches,再修改为预先设置的学习率来进行训练。
二、为什么要使用 warmup?
在实际中,由于训练刚开始时,训练数据计算出的梯度 grad 可能与期望方向相反,所以此时采用较小的学习率 learning rate,随着迭代次数增加,学习率 lr 线性增大,增长率为 1/warmup_steps;迭代次数等于 warmup_steps 时,学习率为初始设定的学习率;
另一种原因是由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
迭代次数超过warmup_steps时,学习率逐步衰减,衰减率为1/(total-warmup_steps),再进行微调。
刚开始训练时,学习率以 0.01 ~ 0.001 为宜, 接近训练结束的时候,学习速率的衰减应该在100倍以上
三、如何实现warmup?
num_train_optimization_steps为模型参数的总更新次数
一般来说:
t_total 是参数更新的总次数,首先是如果设置了 梯度累积trick会除 gradient_accumulation_steps ,然后乘上 训练 epoch 得到最终的更新次数
下面俩例子区别是 len(train_dataloader)=int(total_train_examples) / .train_batch_size 实际上是一样的
num_train_optimization_steps = int(total_train_examples / args.train_batch_size / args.gradient_accumulation_steps)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=num_train_optimization_steps)
t_total = len(train_dataloader) / args.gradient_accumulation_steps * args.num_train_epochs
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
四、warmup 方法的优势:
有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
有助于保持模型深层的稳定性
五、optimizer.step()和scheduler.step()的区别
optimizer.step()通常用在每个mini-batch之中,而scheduler.step()通常用在epoch里面,但是不绝对,可以根据具体的需求来做。只有用了optimizer.step(),模型才会更新,而scheduler.step()是对lr(学习率)进行调整。
Schedule用来调节学习率,拿线性变换调整来说,下面代码中,step是当前迭代次数:
def lr_lambda(self, step):
# 线性变换,返回的是某个数值x,然后返回到类LambdaLR中,最终返回old_lr*x
if step < self.warmup_steps: # 增大学习率
return float(step) / float(max(1, self.warmup_steps))
# 减小学习率
return max(0.0, float(self.t_total - step) / float(max(1.0, self.t_total - self.warmup_steps)))
if args.max_steps > 0:#default=-1
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
for step, batch in enumerate(tqdm(train_dataloader, desc="Iteration")):
batch = tuple(t.to(device) for t in batch)
input_ids, input_mask, segment_ids, label_ids = batch
outputs = model(input_ids, label_ids, segment_ids, input_mask)
loss = outputs#r如果没有调用任何函数,那么返回的是forward函数中的返回值
if n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu.
if args.gradient_accumulation_steps > 1:##所以loss应该是间隔指定梯度累积步的均值
loss = loss / args.gradient_accumulation_steps
loss.backward()
tr_loss += loss.item()##设置经过多少个 梯度累积步 之后才更新网络的参数
if (step + 1) % args.gradient_accumulation_steps == 0:#设定多少batch时更新神经网络的参数
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
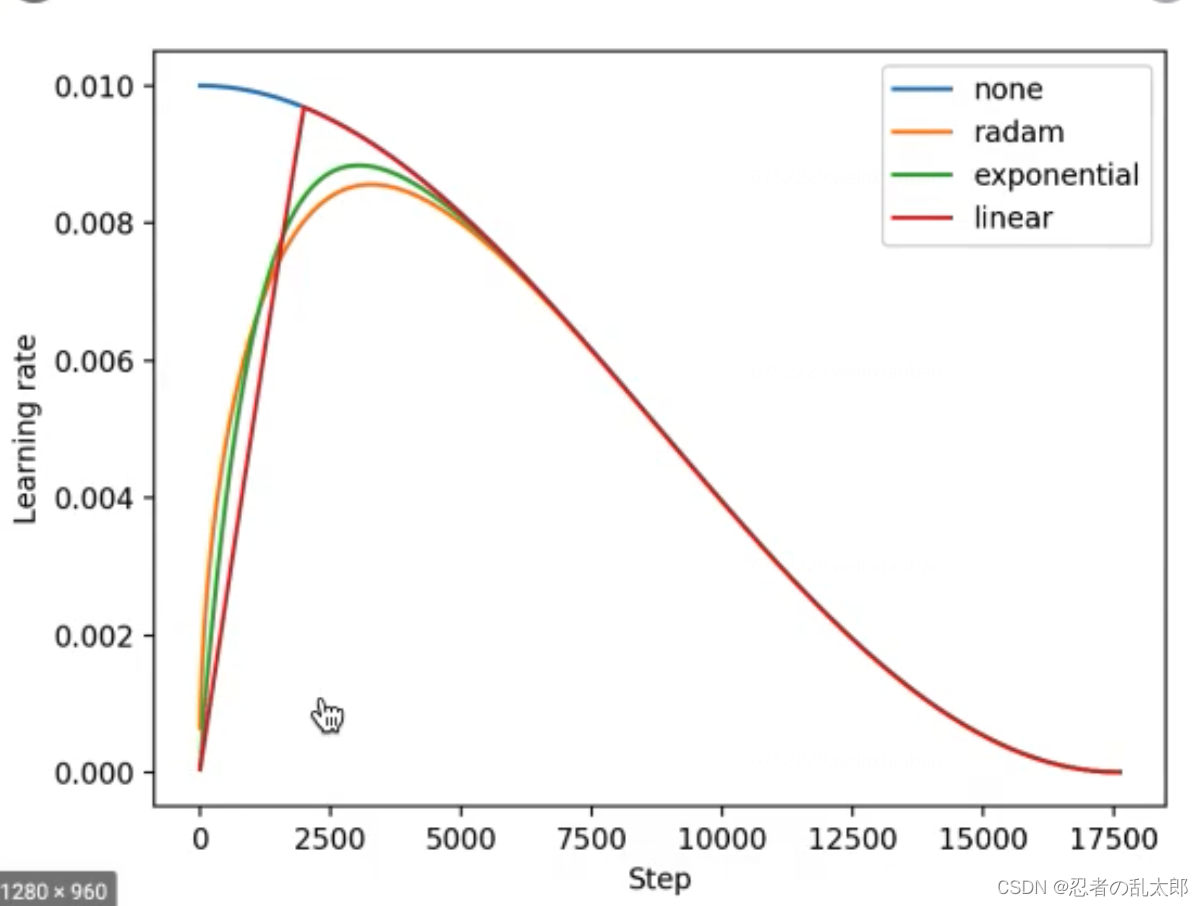
六、
学习率是神经网络训练中最重要的超参数之一,针对学习率的优化方式很多,Warmup是其中的一种。
(一)、什么是Warmup?
Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习率来进行训练。
(二)、为什么使用Warmup?
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
ExampleExampleExample:Resnet论文中使用一个110层的ResNet在cifar10上训练时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个steps),然后使用0.1的学习率进行训练。
(三)、Warmup的改进
(二)所述的Warmup是constant warmup,它的不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。于是18年Facebook提出了gradual warmup来解决这个问题,即从最初的小学习率开始,每个step增大一点点,直到达到最初设置的比较大的学习率时,采用最初设置的学习率进行训练。
1、gradual warmup的实现模拟代码如下:
"""
Implements gradual warmup, if train_steps < warmup_steps, the
learning rate will be `train_steps/warmup_steps * init_lr`.
Args:
warmup_steps:warmup步长阈值,即train_steps<warmup_steps,使用预热学习率,否则使用预设值学习率
train_steps:训练了的步长数
init_lr:预设置学习率
"""
import numpy as np
warmup_steps = 2500
init_lr = 0.1
# 模拟训练15000步
max_steps = 15000
for train_steps in range(max_steps):
if warmup_steps and train_steps < warmup_steps:
warmup_percent_done = train_steps / warmup_steps
warmup_learning_rate = init_lr * warmup_percent_done #gradual warmup_lr
learning_rate = warmup_learning_rate
else:
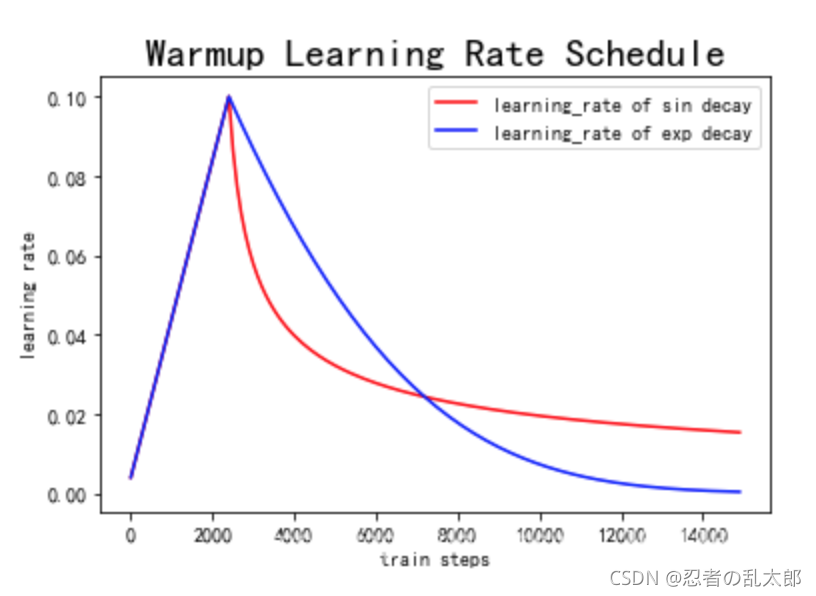
#learning_rate = np.sin(learning_rate) #预热学习率结束后,学习率呈sin衰减
learning_rate = learning_rate**1.0001 #预热学习率结束后,学习率呈指数衰减(近似模拟指数衰减)
if (train_steps+1) % 100 == 0:
print("train_steps:%.3f--warmup_steps:%.3f--learning_rate:%.3f" % (
train_steps+1,warmup_steps,learning_rate))
2、上述代码实现的Warmup预热学习率以及学习率预热完成后衰减(sin or exp decay)的曲线图如下:
(四)总结
使用Warmup预热学习率的方式,即先用最初的小学习率训练,然后每个step增大一点点,直到达到最初设置的比较大的学习率时(注:此时预热学习率完成),采用最初设置的学习率进行训练(注:预热学习率完成后的训练过程,学习率是衰减的),有助于使模型收敛速度变快,效果更佳。
参考资料:
warmup
香侬读 | Transformer中warm-up和LayerNorm的重要性探究
神经网络中 warmup 策略为什么有效;有什么理论解释么?
一文看懂学习率warmup及各主流框架实现差异
yolov5-5中训练的热身次数(warmup)设置
warmup 预热学习率

















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









