






2024 CVPR
文章链接:<<AMU-Tuning: Effective Logit Bias for CLIP-based Few-shot Learning>>
Abstract
作者认为,当前人们对致使现有CLIP few shot有效性的key factors研究不够深入,限制了few shot的发展。
在本文中提出从logit bias的角度引入统一的公式来分析基于CLIP的few shot方式,为此,分解了logit bias计算中的三个主要成分:logit features, logit predictor,and logit fusion,证实了其对few shot分类的影响,并在此基础上,提出全新的AMU-Tuning方式来学习logit bias,在几个benchmarks上进行了实验,结果表明,AMU-Tuning明显优于其同行,并达到了基于CLIP few shot的SOTA。
AMU-Tuning方式具体来说:
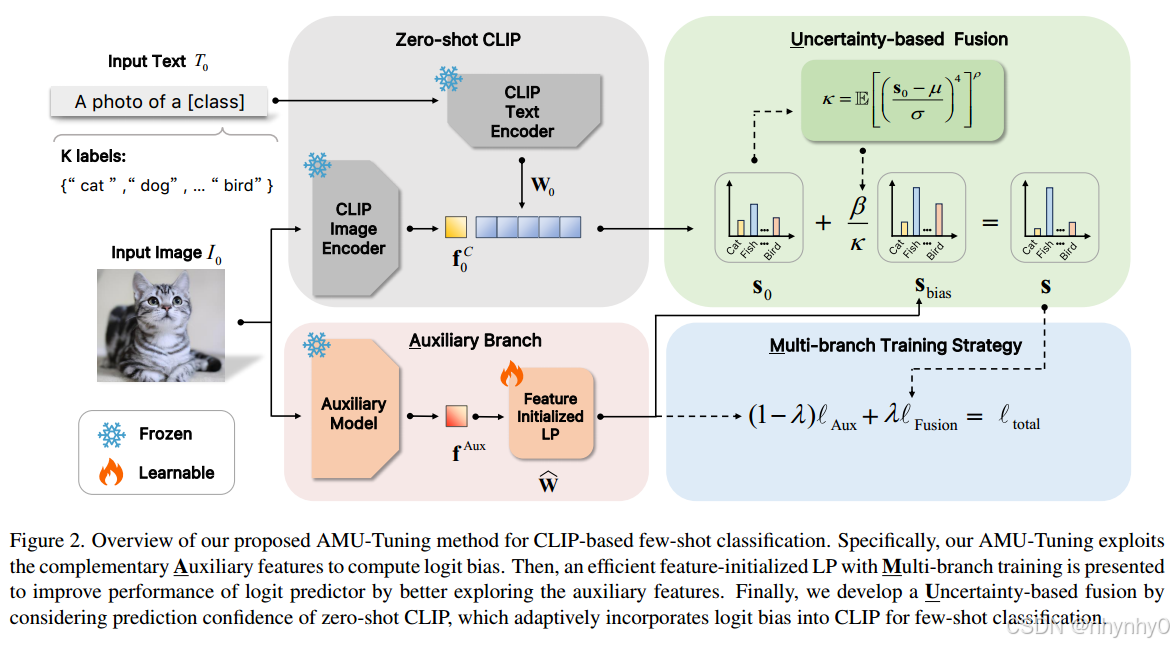
通过合适的辅助特征(Auxiliary features)来预测logit bias,然后将这些辅助特征通过多分支训练(Multi-branch training)送到一个 feature-initialized linear probing,最后基于不确定性的融合(Uncertaintybased fusion),将logit bias纳入到CLIP中few shot classification。
Background
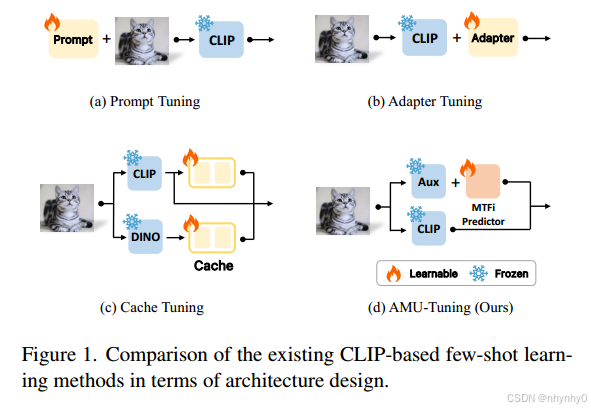
现有方法可分为三类:
- Prompt Tuning
为CLIP的text encoder引入可学习的text prompt; - Adapter Tuning
在text and visual encoder之后引入一些轻量单元,如MLP,来为下游任务调整特征; - Cache-based Tuning
cache-based tuning methods present “soft” K-nearest neighbor classifiers storing visual features and labels of training samples, which are combined with zero-shot CLIP for final classification.
Method
作者认为,之前的方法总体可以看作为zero-shot CLIP学习不同的logit biases,进而影响few-shot 分类表现。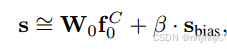
从logit bias的角度对之前的方法进行分析,将其拆解为三个方面(logit features, logit predictor,and logit fusion),实例分析其对few-shot的影响。
-
logit features
比较了几种辅助特征(Auxiliary features)在predict logit bias方面的互补性与优越性,发现合适的特征可以极大地提高logit bias的学习;
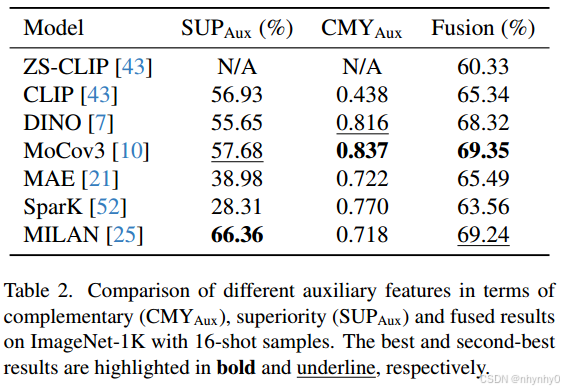
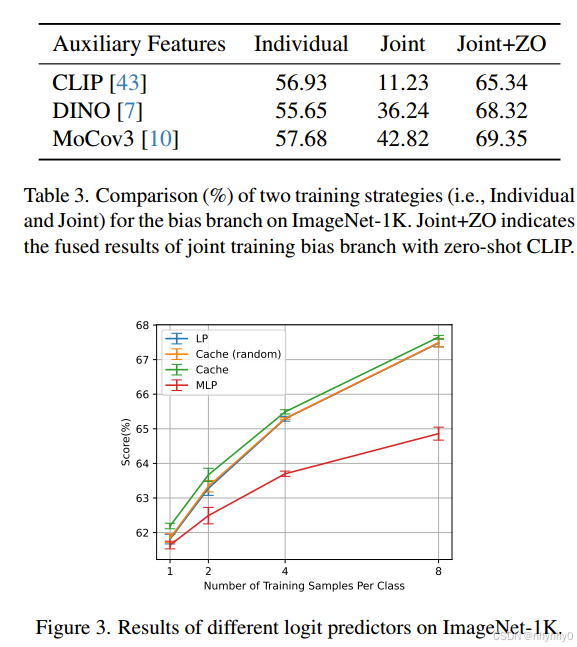
辅助特征: 现有方法主要利用CLIP自身来计算logit bias,CaFo中提出用额外的特征来帮助生成logit bias,本文中将这些额外的特征称为辅助特征。实验
在ImageNet-1k上用ResNet-50(RN50)为backbone的CLIP,16-shot的训练样本。
对于辅助特征,比较了6个预训练模型,CLIP、DINO、MoCov3、MAE、SparK和MILAN,backbone均为RN50,MAE和MILAN中由于预训练的RN50无法获得,使用ViT-B/16。
为计算logit bias,在辅助特征之后训练了一个LP,再把它和zero-shot CLIP的预测加起来,用于few-shot分类。
为50个epoch内的辅助特征设计一个独立的LP,其结果表示不同特征的优越性。
使用辅助特征的LP预测与zero-shot CLIP预测计算余弦相似度,值越小,表示两者不相似,进而表明辅助特征的补充性。
结果表明:
辅助特征的补充性比优越性更重要,且,在补充性相同时,优越性越高,fusion结果越好。
-
logit predictor
比较不同的logit predictor的效果(e.g. MLP, cache-based model, and linear probing (LP)),发现feature initialization对logit predictor有帮助,但是现有的predictor 并不能充分利用辅助特征的优越性;实验
在ImageNet-1k中,使用训练样本的不同shot,在几种predictor(MLP, Cache, Cache with random initialization (Cache-Random), and a simple linear probing (LP)(LP为baseline) )中评价logit predictior的效果,将RN50 of MoCov3的输出作为输入,结果表明Cache的效果最好,说明,feature initialization对logit predictor有帮助。
使用LP作为predictor,比较不同training branch(individual,joint)对辅助特征的作用,发现Joint方法本应对zero-CLIP补充辅助特征的信息,但是其效果并不好,说明现有的preditor并不能充分利用辅助特征的优越性。
-
logit fusion
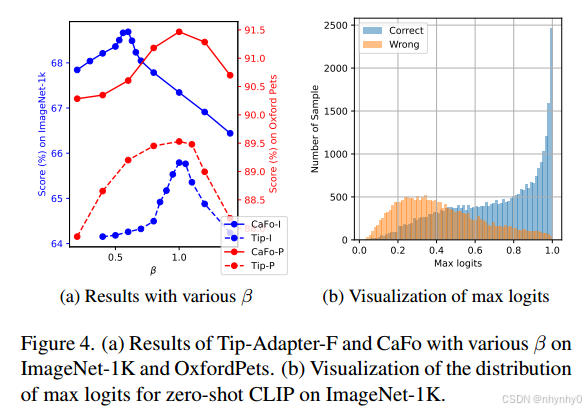
trade-off parameter of fusion对模型和数据集非常敏感,与zero-shot CLIP的置信度有关实验
在ImageNet-1K and OxfordPets datasets上,对比了不同β的结果,表明该值影响很大。
可视化zero-shot CLIP在ImageNet-1k上的上的max logits的分布,结果表明zero-shot CLIP在较大max logits上的分类较正确,表明更高confidence的logits导致更准确的分类结果,而较低confidence的logits的样本错误较多,因此可以在低confidence的logits上提高β的值。
进而提出了AMU-Tuning,并在11个下游任务,4个out of distribution benchmark上使用不同的backbone验证效果,模型具体架构如下图所示。
其中,辅助特征fAux是利用RN50的MoCov3找到的优越性和补充性最优的特征。
Multi-branch Training of Feature-initialized (MTFi) Logit Predictor
在之前logit predictor的实验中发现,LP比基于cached的模型更高效,但由于无feature initialization,表现却更差,于是提出了一个feature-initialized LP,将其权重初始化为下述,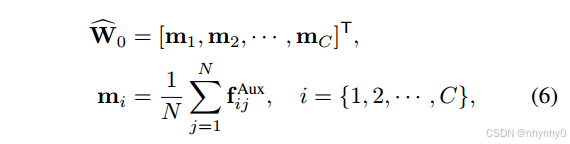
其中fijAux是第i个class中第j个样本(feature),第j个训练样本的sbias是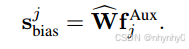
为充分利用辅助特征,提出多分支的训练策略,除了基于fused logit s的原始分类损失ℓfusion的基础上,引入了一条新的分支来最小化sbias与ground truth之间的交叉熵损失,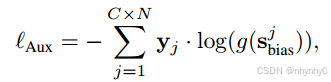
g(·) 是softmax函数,总loss为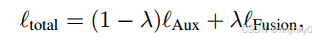
其中λ是用来平衡Aux与Fusion的一个超参数。
Uncertainty-based Fusion
并且,提出了一个不确定性κ(based on Kurtosis)的fusion来融合bias和zero-shot CLIP,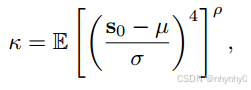
其中ρ是来控制不确定性大小的,最终AMU-Tuning方式如下所示,其中只有LP的W^是通过total的损失来优化的。
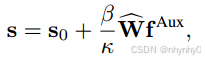
Experiments
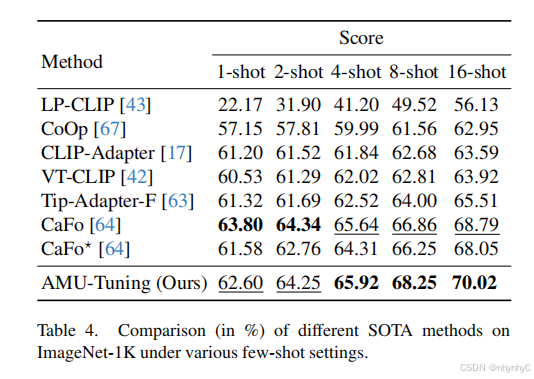
AMU-Tuning with [1, 2, 4, 8, 16]-shot training samples
与SOTA对比,在包含ImageNet-1k的11个下游任务上,AMU-Tuning达到了大多数任务的best,其中,由于Cafo使用DALL-E生成的额外训练样本,在shot较小时,AMU效果不如Cafo,shot较大时,AMU效果更好。
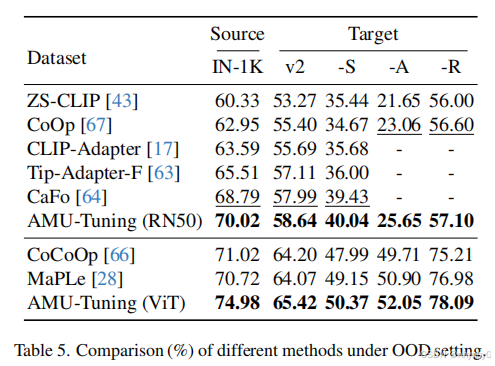
在4个out of distribution(OOD) benchmarks上,AMU-Tuning效果最好,说明鲁棒性良好。
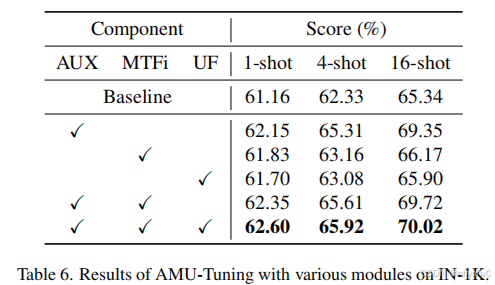
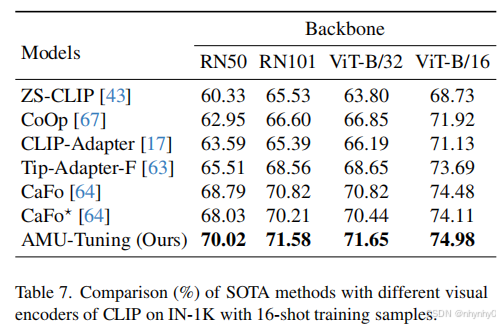
对AUX MTFi UF三个部分做消融实验,发现每一部分都可以提高performance,使用不同的CLIP visual encorder,与SOTA对比,发现当前基于RN50的AMU-Tuning有更好的结果,说明其强泛化性。
Question
- cached_based tuning 是怎么做的,DINO发挥了什么作用
cached_based tuning参考TipAdapter和CaFo,CaFo中增加了DINO的额外缓存结构; - MLP与Linear Probe有何区别
Linear 层是单层神经网络,进行线性变化,通常用于提取特征;
MLP是多层,可通过非线性变换学习更加复杂的特征; - fused logit 是什么?logit具体指的是什么?
个人认为,fused logit是指在上述MTFI完成之后,将辅助特征生成的sbias与zero-shot CLIP生成的s0进行融合的过程,这里的logit应该是余弦相似度; - logit predictor是指计算余弦相似度的一层吗?
个人认为是的;

















 2338
2338

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









