









一、通过官方网站查阅token与汉字的关系
大家都知道GPT是按照token收费的:
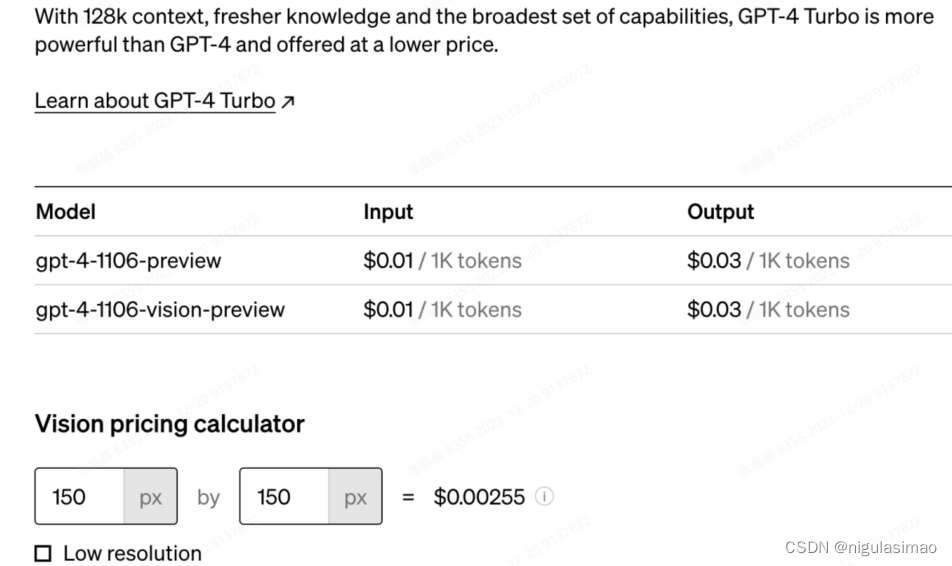
网上找到的各种资料,关于一个 token是多少汉字说法不一,今天我们就来看看到底一个token代表多少汉字。
网址是这个,大家有兴趣的可以自己上去查看。
https://platform.openai.com/tokenizer
首先我们来看一个短句,这句话29个字符,37个token。
它能识别出“中国”“你”“我”这样的专有名词,但是对于杭州、西湖这样的是识别不出来的,甚至算token的时候略有不同。
如“杭”算了两次,“州”则只算一次。

换一段示例,这里的字与token基本是一对一,我们也发现了如“处理”这样的词是只算一个token,但是像“擅”则占了3个token。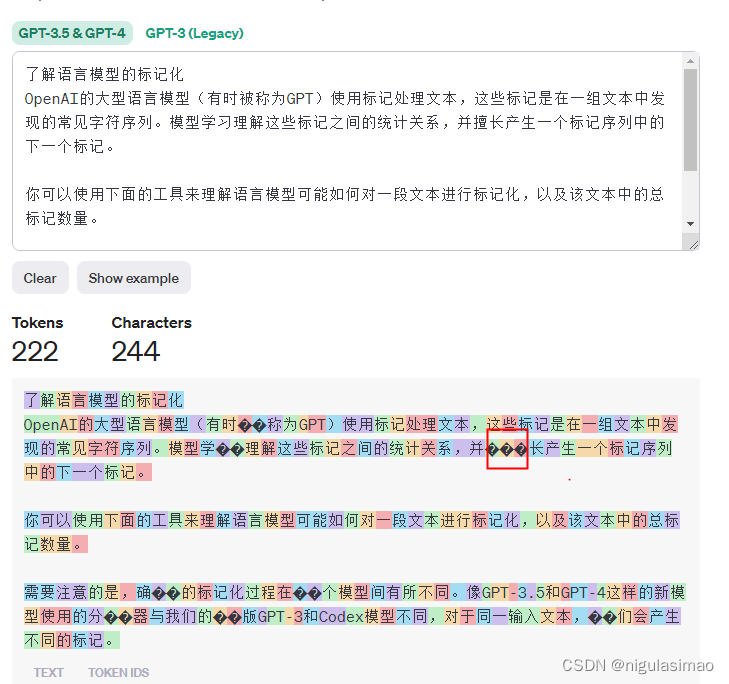
为什么会这样呢?通过与gpt进行问答,我们可以看出这个跟字符在训练集中出现的频率有关。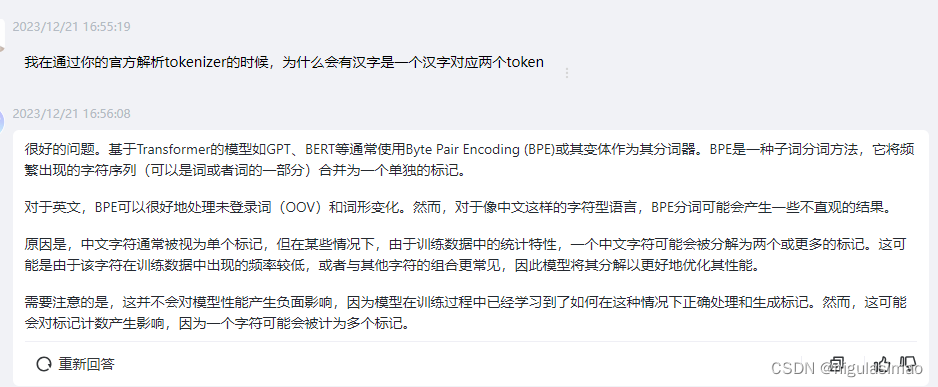
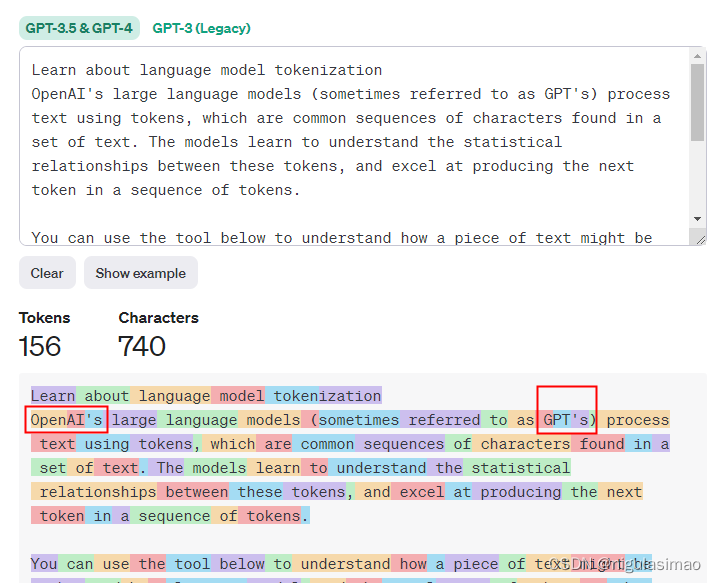
gpt对英文分词效果较好,我们将上边的中文转换成英文,token少了很多,但是对于一些不熟悉的单词,它也是逐个字符进行计算。
二、通过调用python库提前统计token数
当然你可以在自己的程序中先计算token数
Tiktoken是OpenAI开发的一个Python库。它的主要功能是查看一个给定的字符串在GPT模型中被标记化(Tokenized)为多少个标记。
在GPT和许多其他的Transformer架构的模型中,输入的文本首先会被分解(Tokenized)成更小的部分(即标记),然后这些标记会被模型处理。这些标记可以是一个单词,一个字符,或者是介于两者之间的任何东西。这取决于模型的实际实现和训练数据。
以下是一些Tiktoken的主要特性:
1. **查看标记数**:给定一个字符串,Tiktoken可以告诉你这个字符串会被分解成多少个标记。
2. **查看标记**:除了查看标记的数量,Tiktoken还可以显示具体的标记是什么。
3. **模型特定**:Tiktoken可以根据不同的模型(如GPT-2, GPT-3等)来进行标记化。
4. **计算API调用的成本**:由于OpenAI的API是按标记数计费的,所以你可以用Tiktoken提前计算出API调用的成本。
5. **开源**:Tiktoken是开源的,你可以在GitHub上找到它的源代码。
因此,如果你在使用像GPT这样的模型,并且想要更深入地理解你的输入数据是如何被模型处理的,Tiktoken是一个非常有用的工具。
# pip install tiktoken
# 定义一个函数 count_tokens,用于计算给定文本在特定语言模型下的标记数量
def count_tokens(text, model_version=4):
# 从 model_dict 字典中,根据 model_version 参数获取相应的语言模型
model = model_dict[model_version]
# 使用 tiktoken.encoding_for_model 方法,获取该模型的标记化编码器
encoding = tiktoken.encoding_for_model(model)
# 使用编码器的 encode 方法,对输入的 text 进行标记化处理,得到一个标记列表
tokens = encoding.encode(text)
# 计算标记列表的长度,即标记的数量
token_count = len(tokens)
# 返回标记的数量
return token_count

















 226
226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









