







图像分割
深度学习尤其是卷积神经网络在图像处理的许多领域都获得了很大的成功,在分类,识别等方面都已经获得了很大的成功.在深度学习把图像分类和识别达到极致之后。深度学习开始在图像分割方面开始进行收割了。图像分割的意思就是对于图像中每个像素进行分类操作。
提到深度学习用在图像分割上不得不提的一篇文章是FCN 这篇文章。这算一个开创性的文章吧。整个文章采用的模型是基于VGG16的模型。
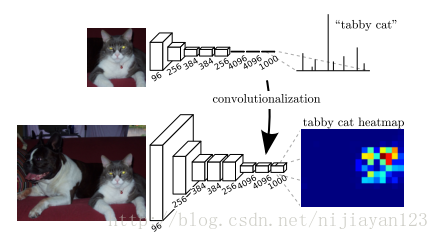
一开始在这边文章中我们可以发现图像分割和图像分类的区别了。在这里图像分割把图像分割的最后几层全连接的结构去掉了,因为不需要对整个图像进行概率的分类。把全连接结构去掉以后,后面进行了插值计算还原了整个图片的大小最后得到分割的图像。在这里不进行细说了。有兴趣的可以具体看看论文。
在有一些基础的同学看来,导致整个图像分辨率下降的原因是采用了池化的操作了卷积操作。导致整个一开始的图像大小慢慢的缩小了。所以现在去掉整个池化和采用“SAME”的卷积操作不就可以了。
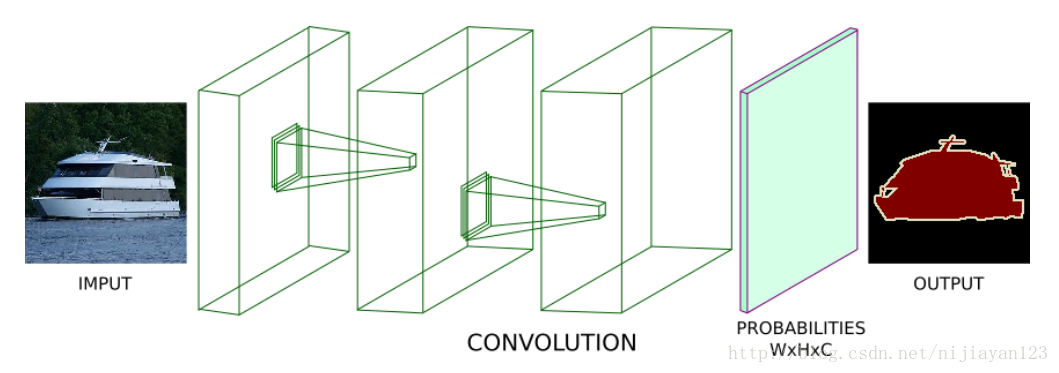
这种结构理论上是可以的,但是在实际操作中有很大的问题。在计算量和内存消耗上都十分巨大的,导致整个这样操作不是很现实。
在FCN开创了一个开始以后,后面出现了很多网络结构。现在最有用的也是用的最广泛的就是编码和解码的结构。
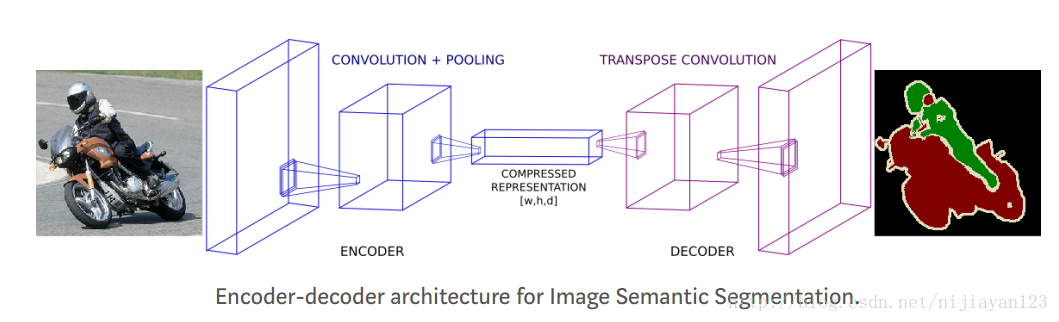
这种结构有许多典型的文章,比如segnet deconvnet u-net 等一系列这些文章。这些文章基本结构都是大同小异的,都是编码和解码的结构。
在编码和解码结构使用成熟以后。大家又回到一开始的FCN的结构。把最后的那个解码结构去掉了。但是去掉了解码过程以后,又回到一开始的问题。整个图片的分辨率越来越小无法保证了。所以后面有出现了一个经典的结构。俗称带洞的卷积神经网络图像分割。这其中以deeplab 的结构为主。
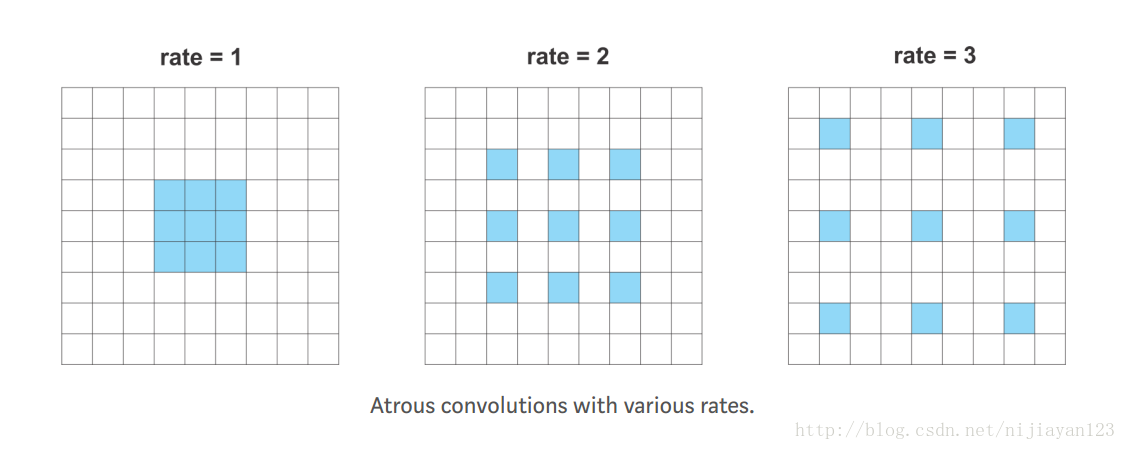
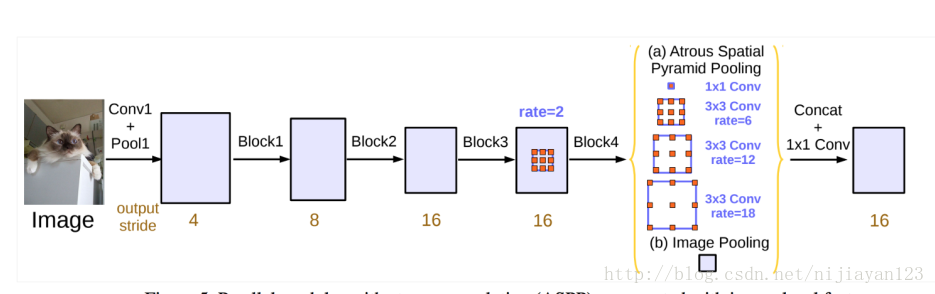
这类型的网络解决了图像分辨率越来越小等一系列问题。也有比较好的效果了。
但是最近几年又又新的结构和方式的结构提出来。所以深度学习在图像分割的领域有了很好的应用了。
上面只是说了一些大概的过程和结构。在FCN网络提出了以后,有许多基于这个结构的网络提出了只不过后面采用了CRF等一些结构来进一步优化整个输出的结果。
下面是基于keras 的图像分割的简单实现
def FCN8s():
inputData = Input(batch_shape=(None,224,224,3))
conv1_1 = Conv2D(64,kernel_size=(3,3),activation='relu',padding='same', name='conv1_1')(inputData)
conv1_2 = Conv2D(64,kernel_size=(3,3),activation='relu',padding='same', name='conv1_2')(conv1_1)
pool1 = MaxPooling2D((2,2), strides=(2,2), name='pool1')(conv1_2)
conv2_1 = Conv2D(128,kernel_size=(3,3),activation='relu',padding='same', name='conv2_1')(pool1)
conv2_2 = Conv2D(128,kernel_size=(3,3),activation='relu',padding='same', name='conv2_2')(conv2_1)
pool2 = MaxPooling2D((2,2), strides=(2,2), name='pool2')(conv2_2)
conv3_1 = Conv2D(256,kernel_size=(3,3),activation='relu',padding='same', name='conv3_1')(pool2)
conv3_2 = Conv2D(256,kernel_size=(3,3),activation='relu',padding='same', name='conv3_2')(conv3_1)
conv3_3 = Conv2D(256,kernel_size=(3,3),activation='relu',padding='same', name='conv3_3')(conv3_2)
pool3 = MaxPooling2D((2,2), strides=(2,2), name='pool3')(conv3_3)
conv4_1 = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same', name='conv4_1')(pool3)
conv4_2 = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same', name='conv4_2')(conv4_1)
conv4_3 = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same', name='conv4_3')(conv4_2)
pool4 = MaxPooling2D((2,2), strides=(2,2), name='pool4')(conv4_3)
conv5_1 = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same', name='conv5_1')(pool4)
conv5_2 = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same', name='conv5_2')(conv5_1)
conv5_3 = Conv2D(512,kernel_size=(3,3),activation='relu',padding='same', name='conv5_3')(conv5_2)
pool5 = MaxPooling2D((2,2), strides=(2,2), name='pool5')(conv5_3)
fc6 = Conv2D(4096,kernel_size=(7,7),activation='relu',padding='same', name='fc6')(pool5)
drop6 = Dropout(0.5)(fc6)
fc7 = Conv2D(4096,kernel_size=(1,1),activation='relu',padding='same', name='fc7')(drop6)
drop7 = Dropout(0.5)(fc7)
score_fr = Conv2D(21, kernel_size=(1,1), padding='valid', name='score_fr')(drop7)
score2 = Conv2DTranspose(21, kernel_size=(4,4),strides=(2,2), name='score2')(score_fr)
upscore2 = Cropping2D(cropping=1, name='crop2')(score2)
score_pool4 = Conv2D(21, kernel_size=(1,1), padding='valid', name='score_pool4')(pool4)
fuse = add([upscore2,score_pool4], name='fuse')
score4 = Conv2DTranspose(21, kernel_size=(4,4),strides=(2,2), name='score4', use_bias=False)(fuse)
upscore4 = Cropping2D(cropping=1, name='crop4')(score4)
score_pool3 = Conv2D(21, kernel_size=(1,1), padding='valid', name='score_pool3')(pool3)
fusex = add([upscore4,score_pool3], name='fusex')
upscore16 = Conv2DTranspose(21, kernel_size=(16,16),strides=(8,8), name='upsample', use_bias=False)(fusex)
score = Cropping2D(cropping=4, name='score')(upscore16)
model = Model(inputs=inputData, outputs=[score])
return model参考文献
1 SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
2 DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
3 Fully Convolutional Networks for Semantic Segmentation
4 ICNet for Real-Time Semantic Segmentation on High-Resolution Images
5 Learning Deconvolution Network for Semantic Segmentation Hyeonwoo
6 U-Net: Convolutional Networks for Biomedical Image Segmentation
Olaf
7 Conditional Random Fields as Recurrent Neural Networks
Shuai















 5327
5327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









