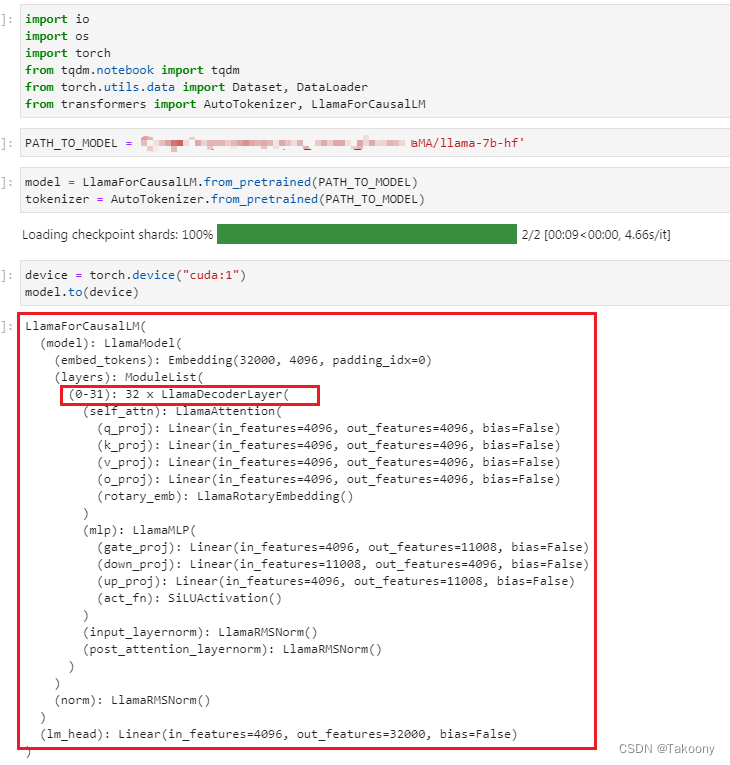
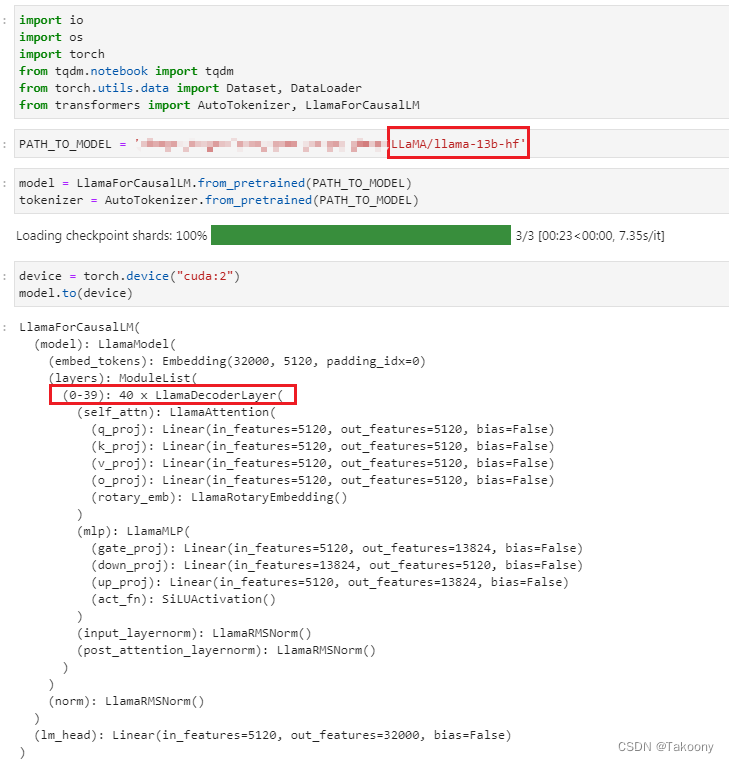
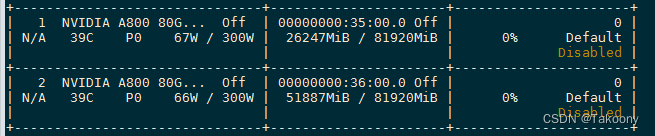
一、llama模型的结构是怎么样的? 采用了transfomer中的decoder,其中7b版本的结构如下: 13B结构如下: GPU显存使用情况: 二、llama模型中的词典为什么会有大量的token有ord(‘▁’)=9601 的字符呢?

























 1844
1844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






