







简介
DQN,即深度Q网络(Deep Q-network),是指基于深度学习的Q-Learing算法。Q-Learing算法维护一个Q-table,使用表格存储每个状态s下采取动作a获得的奖励,即状态-价值函数Q(s,a),这种算法存在很大的局限性。在现实中很多情况下,强化学习任务所面临的状态空间是连续的,存在无穷多个状态,这种情况就不能再使用表格的方式存储价值函数。
为了解决这个问题,我们可以用一个函数Q(s,a;w)来近似动作-价值Q(s,a),称为价值函数近似Value Function Approximation,我们用神经网络来生成这个函数Q(s,a;w),称为Q网络(Deep Q-network),w是神经网络训练的参数。
Q-Learning参考:https://blog.csdn.net/niulinbiao/article/details/133659036
DQN相较于传统的强化学习算法(Q-learning)有三大重要的改进:
-
引入深度学习中的神经网络,利用神经网络去拟合Q-learning中的Q表,解决了Q-learning中,当状态维数过高时产生的“维数灾难”问题;
-
固定Q目标网络,利用延后更新的目标网络计算目标Q值,极大的提高了网络训练的稳定性和收敛性;
-
引入经验回放机制,使得在进行网络更新时输入的数据符合独立同分布,打破了数据间的相关性。
本文还增加了动态探索概率,也就是随着模型的训练,我们有必要减少探索的概率
DQN的算法流程如下:
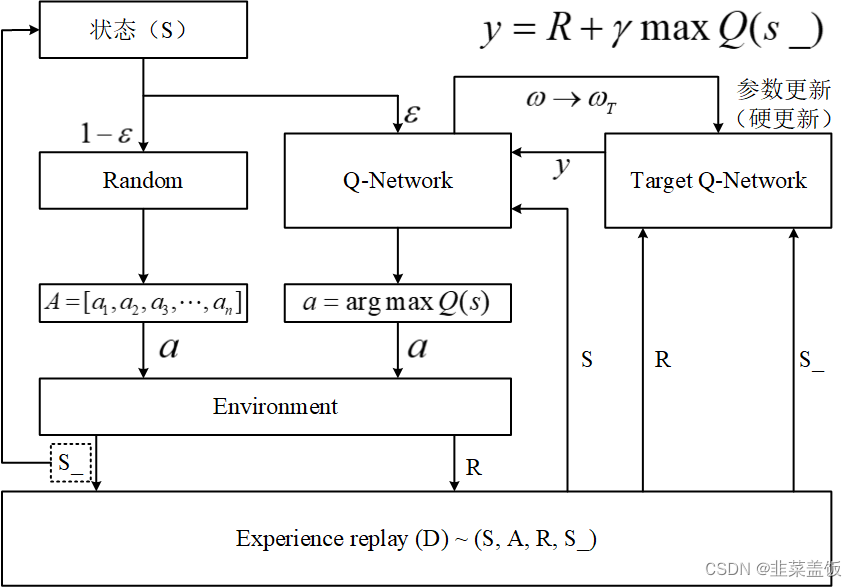
- 首先,算法开始前随机选择一个初始状态,然后基于这个状态选择执行动作,这里需要进行一个判断,即是通过Q-Network选择一个Q值最大对应的动作,还是在动作空间中随机选择一个动作。
- 在程序编程中,由于刚开始时,Q-Network中的相关参数是随机的,所以在经验池存满之前,通常将设置的很小,即初期基本都是随机选择动作。
- 在动作选择结束后,agent将会在环境(Environment)中执行这个动作,随后环境会返回下一状态(S_)和奖励(R),这时将四元组(S,A,R,S_)存入经验池。
- 接下来将下一个状态(S_)视为当前状态(S),重复以上步骤,直至将经验池存满。
- 当经验池存满之后,DQN中的网络开始更新。即开始从经验池中随机采样,将采样得到的奖励(R)和下一个状态(S_)送入目标网络计算下一Q值(y),并将y送入Q-Network计算loss值,开始更新Q-Network。往后就是agent与环境交互,产生经验(S,A,R,S_),并将经验放入经验池,然后从经验池中采样更新Q-Network,周而复始,直到Q-Network完成收敛。

- DQN中目标网络的参数更新是硬更新,即主网络(Q-Network)参数更新一定步数后,将主网络更新后的参数全部复制给目标网络(Target
Q-Network)。 - 在程序编程中,通常将设置成随训练步数的增加而递增,即agent越来越信任Q-Network来指导动作。
代码实现
1、环境准备
我们选择openAI的gym环境作为我们训练的环境
env1 = gym.make("CartPole-v0")

2、编写经验池函数
经验池的主要内容就是,存数据和取数据
import random
import collections
from torch import FloatTensor
class ReplayBuffer(object):
# 初始化
def __init__(self, max_size, num_steps=1 ):
"""
:param max_size: 经验吃大小
:param num_steps: 每经过训练num_steps次后,函数就学习一次
"""
self.buffer = collections.deque(maxlen=max_size)
self.num_steps = num_steps
def append(self, exp):
"""
想经验池添加数据
:param exp:
:return:
"""
self.buffer.append(exp)
def sample(self, batch_size):
"""
向经验池中获取batch_size个(obs_batch,action_batch,reward_batch,next_obs_batch,done_batch)这样的数据
:param batch_size:
:return:
"""
mini_batch = random.sample(self.buffer, batch_size)
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = zip(*mini_batch)
obs_batch = FloatTensor(obs_batch)
action_batch = FloatTensor(action_batch)
reward_batch = FloatTensor(reward_batch)
next_obs_batch = FloatTensor(next_obs_batch)
done_batch = FloatTensor(done_batch)
return obs_batch,action_batch,reward_batch,next_obs_batch,done_batch
def __len__(self):
return len(self.buffer)
3、神经网络模型
我们简单地使用神经网络
import torch
class MLP(torch.nn.Module):
def __init__(self, obs_size,n_act):
super().__init__()
self.mlp = self.__mlp(obs_size,n_act)
def __mlp(self,obs_size,n_act):
return torch.nn.Sequential(
torch.nn.Linear(obs_size, 50),
torch.nn.ReLU(),
torch.nn.Linear(50, 50),
torch.nn.ReLU(),
torch.nn.Linear(50, n_act)
)
def forward(self, x):
return self.mlp(x)
4、探索率衰减函数
随着训练过程,我们动态地减小探索率,因为训练到后面,模型会越来越收敛,没必要继续探索
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import numpy as np
class EpsilonGreedy():
def __init__(self,n_act,e_greed,decay_rate):
self.n_act = n_act
self.epsilon = e_greed
self.decay_rate = decay_rate
def act(self,predict_func,obs):
if np.random.uniform(0, 1) < self.epsilon: # 探索
action = np.random.choice(self.n_act)
else: # 利用
action = predict_func(obs)
self.epsilon = max(0.01,self.epsilon-self.decay_rate) #是探索率最低为0.01
return action
5、DQN算法
import copy
import numpy as np
import torch
from utils import torchUtils
# 添加探索值递减的策略
class DQNAgent(object):
def __init__( self, q_func, optimizer, replay_buffer, batch_size, replay_start_size,update_target_steps, n_act,explorer, gamma=0.9):
'''
:param q_func: Q函数
:param optimizer: 优化器
:param replay_buffer: 经验回放器
:param batch_size: 批次数量
:param replay_start_size: 开始回放的次数
:param update_target_steps: 经过多少步才会同步target网络
:param n_act: 动作数量
:param gamma: 收益衰减率
:param e_greed: 探索与利用中的探索概率
'''
self.pred_func = q_func
self.target_func = copy.deepcopy(q_func)
self.update_target_steps = update_target_steps
self.explorer = explorer
self.global_step = 0 #全局
self.rb = replay_buffer
self.batch_size = batch_size
self.replay_start_size = replay_start_size
self.optimizer = optimizer
self.criterion = torch.nn.MSELoss()
self.n_act = n_act # 动作数量
self.gamma = gamma # 收益衰减率
# 根据经验得到action
def predict(self, obs):
obs = torch.FloatTensor(obs)
Q_list = self.pred_func(obs)
action = int(torch.argmax(Q_list).detach().numpy())
return action
# 根据探索与利用得到action
def act(self, obs):
return self.explorer.act(self.predict,obs)
def learn_batch(self,batch_obs, batch_action, batch_reward, batch_next_obs, batch_done):
# predict_Q
pred_Vs = self.pred_func(batch_obs)
action_onehot = torchUtils.one_hot(batch_action, self.n_act)
predict_Q = (pred_Vs * action_onehot).sum(1)
# target_Q
next_pred_Vs = self.target_func(batch_next_obs)
best_V = next_pred_Vs.max(1)[0]
target_Q = batch_reward + (1 - batch_done) * self.gamma * best_V
# 更新参数
self.optimizer.zero_grad()
loss = self.criterion(predict_Q, target_Q)
loss.backward()
self.optimizer.step()
def learn(self, obs, action, reward, next_obs, done):
self.global_step+=1
self.rb.append((obs, action, reward, next_obs, done))
#当经验池中到的数据足够多时,并且满足每训练num_steps轮就更新一次参数
if len(self.rb) > self.replay_start_size and self.global_step%self.rb.num_steps==0:
self.learn_batch(*self.rb.sample(self.batch_size))
#我们每训练update_target_steps轮就同步目标网络
if self.global_step%self.update_target_steps==0:
self.sync_target()
# 同步target网络
def sync_target(self):
for target_param,param in zip(self.target_func.parameters(),self.pred_func.parameters()):
target_param.data.copy_(param.data)
6、训练代码
import dqn,modules,replay_buffers
import gym
import torch
from explorers import EpsilonGreedy
class TrainManager():
def __init__(self,
env, #环境
episodes=1000, #轮次数量
batch_size=32, #每一批次的数量
num_steps=4, #进行学习的频次
memory_size = 2000, #经验回放池的容量
replay_start_size = 200, #开始回放的次数
update_target_steps=200, #经过训练update_target_steps次后将参数同步给target网络
lr=0.001, #学习率
gamma=0.9, #收益衰减率
e_greed=0.1, #探索与利用中的探索概率
e_greed_decay=1e-6, #探索率衰减值
):
self.env = env
self.episodes = episodes
n_act = env.action_space.n
n_obs = env.observation_space.shape[0]
q_func = modules.MLP(n_obs, n_act)
optimizer = torch.optim.AdamW(q_func.parameters(), lr=lr)
rb = replay_buffers.ReplayBuffer(memory_size,num_steps)
explorer = EpsilonGreedy(n_act,e_greed,e_greed_decay)
self.agent = dqn.DQNAgent(
q_func=q_func,
optimizer=optimizer,
replay_buffer = rb,
batch_size=batch_size,
update_target_steps=update_target_steps,
replay_start_size = replay_start_size,
n_act=n_act,
explorer = explorer,
gamma=gamma)
# 训练一轮游戏
def train_episode(self):
total_reward = 0
obs = self.env.reset()
while True:
action = self.agent.act(obs)
next_obs, reward, done, _ = self.env.step(action)
total_reward += reward
self.agent.learn(obs, action, reward, next_obs, done)
obs = next_obs
if done: break
print('e_greed=',self.agent.explorer.epsilon)
return total_reward
# 测试一轮游戏
def test_episode(self):
total_reward = 0
obs = self.env.reset()
while True:
action = self.agent.predict(obs)
next_obs, reward, done, _ = self.env.step(action)
total_reward += reward
obs = next_obs
self.env.render()
if done: break
return total_reward
def train(self):
for e in range(self.episodes):
ep_reward = self.train_episode()
print('Episode %s: reward = %.1f' % (e, ep_reward))
#每训练100轮我们就测试一轮
if e % 100 == 0:
test_reward = self.test_episode()
print('test reward = %.1f' % (test_reward))
if __name__ == '__main__':
env1 = gym.make("CartPole-v0")
tm = TrainManager(env1)
tm.train()
实现效果

















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











