







1、Boostrap介绍
1.1 概念性解释
- Boostrap统计学方法是一种非参数检验方法,用于估计各种统计量的置信区间。
- Boostrap计算步骤简单的描述为:通过有放回的数据集的重采样,产生一系列的待检验统计量的Boostrap经验分布。基于该分布,计算标准误差,构建置信区间,并对多种类型的样本进行统计信息和假设检验。
- Boostrap统计学方法使用范围比较广,因为它不需要假定数据服从特定的理论分布(比如,多数假设检验的正太分布假设),因此常作为传统假设检验的替代方法
- 如果数据满足特定理论分析,请使用特定理论分布的假设检验;否则,统计效力大大下降
- 适用于小样本量;重采样次数要大于1000次,推荐5000次
对于小数据集,bootstrap效果通常很好。然而,bootstrap产生的数据集改变了初始数据集的分布,这会引入估计偏差,随着数据集总体的增加而功效降低。尽管可以在Bootstrap过程中调整偏差,但情况就会变得复杂。因此普遍认为原数据集的总体不能过大,这样可以保证每次抽样都能反映总体的特性,多次抽样后即能覆盖原总体,并且抽样组成的新总体比原总体大。
**判断可信度的方法**
- Boostrap分布必须逼近正太分布(QQ-plot检验)
- 基于Boostrap分布的统计量与原始样本统计量具有较小的bias
- 95%的置信区间应与Boostrap分布的2.5%和97.5%构建的置信区间十分接近,推荐使用后者(因具有更高的准确度)
- BCa置信区间是bootstrap bias-corrected accelerated (BCa) interval的简写,比Boostrap更具有普遍性和更好的准确度;通常情况下,推荐使用BCa构建的置信区间(该方法也适用于小样本量的计算)
1.2 Boostrap与常规统计学的比较
-
常规的假设检验程序通常假定数据遵循特殊的分布,如T检验、方差分析等参数检验要求正态分布,并使用样本数据的性质、实验设计和检验统计量来估计抽样分布的方程式。因此为了获得有效的结果,需要考虑适当的测试统计数据并满足检验的前提假设。
-
与此相比,bootstrap不对数据的分布做任何假设。对于bootstrap估计抽样分布的方法,将一项研究获得的样本数据进行多次重抽样,创建多个模拟样本集,该方法中不考虑原数据集的固有分布特征,以及特定的前提假设等。
2、Boostrap的统计分析过程
Bootstrap对原始数据集进行重抽样,创建模拟数据数据集,其抽样方法具有如下特点:
(1)每次抽样对于每个样本具有相同的概率;
(2)属于“有放回”的抽样方式;
(3)该过程将创建与原始数据集大小相同的重抽样数据集。
(4)每一个重抽样数据集,均计算一个统计量;基于重抽样的统计量,构建Boostrap抽样分布
以一个示例来解释该过程:
假如:来自总体的一个样本的具有如下数据特征:
n
=
10
x
‾
=
40
s
d
=
5
n = 10 \\ \overline{x} = 40 \\ sd = 5
n=10x=40sd=5
假定样本服从正太分布
其95%置信区间为:
x
‾
−
μ
±
t
d
f
×
s
n
\overline{x} -\mu\pm t_{df} \times \frac{s}{\sqrt{n}}
x−μ±tdf×ns ,其中,
d
f
df
df 表示自由度(
d
f
=
n
−
1
df = n - 1
df=n−1)
假定样本不服从正太分布
此时,上式无法适用。此时可通过bootstrap来解决。
(1)从样本中随机选择10个观测,依次抽样后再放回,即有放回的抽样方式;
(2)计算并记录每一次抽取的样本均值;
(3)重复(1)和(2)过程,到达一个设定的次数,如1000次(考虑到应用bootstrap方法时的样本数量不会很多,因此大部分情况下,1000次足以满足需求了),如此获得了1000个抽样均值的分布,并按从小到大排序;
(4)获取置信区间:
- 在抽样均值分布中找到
2.5%和97.5%分位点,对于1000次抽样,则可分别定位于最前和最末位置的第25个数,它们即定义了95%的置信区间;此时可以有95%的信心认为,总体均值处于此范围内。 - 如果Boostrap抽样分布逼近正态分布,也可以使用如下计算方法计算。
m
e
a
n
b
o
o
t
=
1
B
×
∑
x
‾
∗
S
E
b
o
o
t
=
1
B
−
1
×
∑
(
x
‾
∗
−
m
e
a
n
b
o
o
t
)
2
C
I
95
%
=
x
‾
±
t
∗
×
S
E
b
o
o
t
mean_{boot} = \frac{1}{B} \times \sum_{}{}\overline{x}^* \\ SE_{boot} = \sqrt{\frac{1}{B-1} \times \sum_{}{}(\overline{x}^* - mean_{boot})^2} \\ CI_{95\%} = \overline{x} \pm t^* \times SE_{boot}
meanboot=B1×∑x∗SEboot=B−11×∑(x∗−meanboot)2CI95%=x±t∗×SEboot
其中,
B
B
B 是Boostrap抽样次数;
x
‾
∗
\overline{x}^*
x∗ 是每一次抽样获得的统计量;
S
E
b
o
o
t
SE_{boot}
SEboot 是经过
B
B
B 次抽样的标准误;
x
‾
\overline{x}
x 是原始统计量;
t
∗
t^*
t∗ 是自由度为
n
−
1
n-1
n−1的
t
t
t 分布中
−
t
∗
-t^*
−t∗ 到
t
∗
t^*
t∗ 之间的面积(可查
t
t
t 分布表获得)。
3、Boostrap使用范围
-
Bootstrap统计学方法可用于分析多种类型的统计量和样本属性,例如中位数、标准差、相关系数、回归系数、二元数据的方差、多元统计量等。
-
基于小样本的Bootstrap分布可能非常多变,可能无法准确估计样本分布的形状和分布。因此,从小样本进行可能不可Boostrap分析可能不可靠。
-
总体均值不连续时也要慎重考虑使用bootstrap。
-
此外,如果样本均值服从正态分布或其它特定理论分布,则bootstrap就不存在优势(非参数方法普遍存在这个特点,其它如置换检验、Kruskal-Wallis检验、Wilcoxon检验等),此时参数检验方法仍是首选。但若样本的潜在分布未知,或存在离群点,或样本量过小(
这个是存在争议的),以及没有其它合适的参数方法时,bootstrap将是获取置信区间以及进行假设检验的一种有效方法。例如期望估计样本中位数的置信区间,或者两样本的中位数之差,正态理论没有现成的简单公式可直接套用,此时bootstrap将会是不错的选择。
4、基于R语言的示例
下文展示使用R包boot的方法。
boot扩展了自助法和重抽样的相关用途,可以借助它实现对一个统计量(如单个均值、单个中位数等)或多个统计量(如多变量间的相关系数、一列回归系数等)估计置信区间,实现检验的目的。
接下来,我们展示一种计算相关性的Boostrap的过程。
# 加载依赖包
library(boot)
library(openxlsx)
library(reshape2)
# 加载数据集
dat <- read.xlsx("MATRIX.xlsx", rowNames = TRUE, colNames = TRUE)
dat <- dat[complete.cases(dat),]
dat <- log10(t(dat))
# 计算分子特征的相关系数
# 此时,dat的行为样本,列为分子特征
# > dat[1:5, 1:5]
# M327T43_2 M748T80 M141T343_2 M152T344 M169T48
# N-1 6.557935 3.636034 6.479646 3.590035 4.239999
# N-3 6.865103 3.906939 6.738693 3.979460 4.245882
# N-4 6.374541 4.113542 6.742880 4.047668 4.027226
# N-6 6.430568 3.884347 6.794199 3.787583 4.735048
# N-7 6.108594 3.976090 6.547120 4.172771 4.278799
cor0 <- cor(dat, method = "pearson")
# 基于Boostrap方法获取相关系数的置信区间,判断置信区间的可靠性
# 对于 boot() 而言:
# 1. 如果只有单个统计量,函数应当返回一个数值
# 2. 如果存在多个统计量,函数应该返回一个向量
# 这里需要计算多变量间的相关系数,即代表了多统计量情形,因此首先创建一个能够返回相关系数向量的函数
cor_pearson <- function(data, indices){
# The first argument passed will always be the original data.
# The second will be a vector of indices, frequencies or weights which define the bootstrap sample (row).
# Further, if predictions are required, then a third argument is required
# which would be a vector of the random indices used to generate the bootstrap predictions.
cor0 <- melt(cor(data[indices,]))
cor0 <- cor0$value
cor0
}
# 重抽样 1000 次
set.seed(188)
boot_result <- boot(data = dat, statistic = cor_pearson, R = 1000)
# > boot_result
#
# ORDINARY NONPARAMETRIC BOOTSTRAP
#
# Call:
# boot(data = dat, statistic = cor_pearson, R = 1000)
#
# Bootstrap Statistics :
# original bias std. error
# t1* 1.0000000000 0.000000e+00 0.000000000
# t2* -0.4320469455 6.930338e-03 0.067542272
# t3* 0.4678526182 -5.874037e-03 0.079870378
# t4* -0.1983394818 -3.355326e-03 0.094921866
# t5* 0.3635396786 -3.303559e-03 0.069800938
# ... ... ...
- 结果中返回了n个统计量,对应了两两变量(分子特征)间的pearson相关系数的抽样分布。
- 存在多个统计量的bootstrap抽样时,需要通过指定索引参数观测结果。比如,我们比较感兴趣的两个分子特征:M267T259-M327T43_2
# 根据一开始计算的相关矩阵,获取索引
cor0 <- melt(cor0)
group <- paste(cor0$Var1, cor0$Var2, sep = '-')
# 查看感兴的分子特征间的相关系数的抽样分布
plot(boot_result, index = which(group == 'M267T259-M327T43_2'))
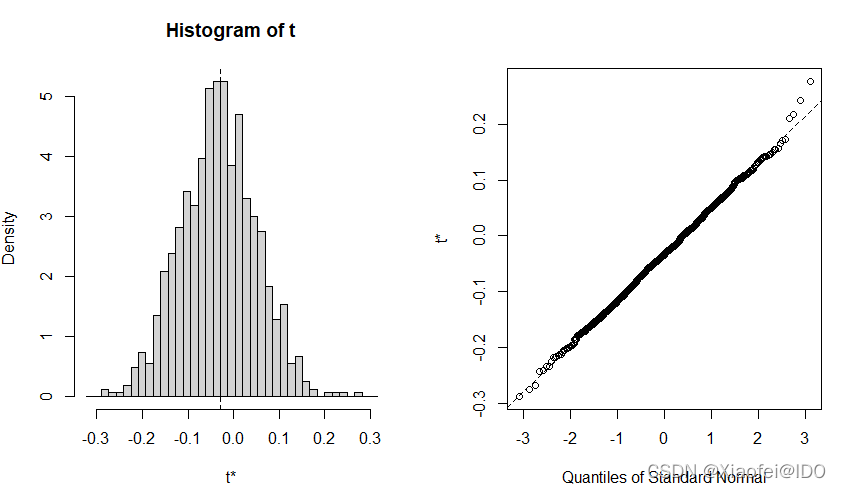
从结果中,我们得知,由bootstrap抽样1000次计算所得pearson相关系数的分布呈正态分布。随后,我们计算其置信区间。
#获取 95% 置信区间,详情 ?boot.ci
#type 参数设定获取置信区间的方法,这里展示了所有方法的区间估计结果,细节描述见帮助
boot.ci(boot_result, conf = 0.95, type = 'all',
index = which(group == 'M267T259-M327T43_2'))
# BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
# Based on 1000 bootstrap replicates
#
# CALL :
# boot.ci(boot.out = boot_result, conf = 0.95, type = "all", index = which(group ==
# "M267T259-M327T43_2"))
#
# Intervals :
# Level Normal Basic
# 95% (-0.1862, 0.1361 ) (-0.1861, 0.1385 )
#
# Level Percentile BCa
# 95% (-0.1960, 0.1286 ) (-0.1797, 0.1386 )
# Calculations and Intervals on Original Scale
# Warning message:
# In boot.ci(boot_result, conf = 0.95, type = "all", index = which(group == :
# bootstrap variances needed for studentized intervals
结果解读:(1)生成置信区间的不同方法将导致获得不同的区间。(2)以上示例的置信区间跨0值,显然是不合理的,因为我们不可能允许两变量之间同时存在正相关和负相关的可能性,因此不成立,也就是两分子特征间的相关性是不可信的。
查看另一个分子特征关系:“M748T80-M327T43_2”
> boot.ci(boot_result, conf = 0.95, type = 'all', index = which(group == "M748T80-M327T43_2"))
# BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
# Based on 1000 bootstrap replicates
#
# CALL :
# boot.ci(boot.out = boot_result, conf = 0.95, type = "all", index = which(group ==
# "M748T80-M327T43_2"))
#
# Intervals :
# Level Normal Basic
# 95% (-0.5714, -0.3066 ) (-0.5806, -0.3149 )
#
# Level Percentile BCa
# 95% (-0.5492, -0.2835 ) (-0.5589, -0.3016 )
# Calculations and Intervals on Original Scale
# Warning message:
# In boot.ci(boot_result, conf = 0.95, type = "all", index = which(group == :
# bootstrap variances needed for studentized intervals
> cor0[which(group == "M748T80-M327T43_2"),]
# Var1 Var2 value
# 2 M748T80 M327T43_2 -0.4320469
结果解读:查看原始观测数据所得的pearson相关系数数值,为-0.43,落在置信区间之内,并且置信区间均保持在负值(负相关)内,因此有充分(95%的把握)理由认为,所观测两微生物类群间的相关性是可信的。


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









