






推荐算法 [1]
传统机器学习推荐算法
基于流行度的推荐算法
简单粗暴,类似于各大新闻、微博热榜等,根据PV(访问量)、UV(独立访客)、日均VV(访问次数)或分享率等数据来按某种热度排序来推荐给用户。
优点:适用于刚注册的新用户。
缺点:无法针对用户提供个性化推荐。
改进:基于该算法可做一些优化,例如加入用户分群的流行度进行排序,通过把热榜上的体育内容优先推荐给体育迷,把政要热文推给热爱谈论政治的用户。
基于协同过滤的推荐算法
倒排索引
倒排索引。从大量文档中查找包含某些词的文档集合,并且在O(1)或O(log n)的时间复杂度完成。在推荐中,将广告库或者物品集建立索引,根据一些定向条件在广告库中迅速检索到一些相关的广告或者物品。
- 收集需要建立索引的文档(物品集)。
- 每一篇文档做分词。
- 对文档进行预处理。
- 对所有文档建立倒排索引,索引中包含一部词典和一个全体倒排记录表。

举例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8exdaWrn-1673923050957)(C:\Users\11878\AppData\Roaming\Typora\typora-user-images\image-20221224202028114.png)]](https://img-blog.csdnimg.cn/1707eea12923407eb31a440316d1544d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GMaT4iJh-1673923050958)(C:\Users\11878\AppData\Roaming\Typora\typora-user-images\image-20221225121342039.png)]](https://img-blog.csdnimg.cn/d0af6037ec4e4100832740b930bd7e79.png)
TF-IDF(词频term frequency-逆文档频率):
对每篇文档采用词袋(BOW)以向量方式描述文档,方便进行相似性度量。搞一个词库,每篇文章对应一个长度为词库长度的向量,向量对应位置元素为相应词语 在文档中出现的次数。对于逆文档频率:如果一个词语在每一篇文章中都出现了,则它对文章之间的相似度是没有贡献的,没办法去区分文章与文章之间的差异,这种词对于向量的贡献应该降低。
I D F ( m ) = l o g ( N D F ( m ) ) IDF(m)=log(\frac{N}{DF(m)}) IDF(m)=log(DF(m)N),N表示总的文章数量,m代表这个词在多少篇文章出现。
对于文章中的每个词,都应该来计算一个值, t f − i d f t , d = t f t , d × i d f t tf-idf_{t,d}=tf_{t,d}\times idf_t tf−idft,d=tft,d×idft当前文档中的词频乘在多少篇文章出现过的倒数。
- 如果一个词语只在少数文档中出现,并且在当前文档中出现的频率比较高,那么它就更能代表当前文档,该词所占的比重就比较大。
- 如果一个词语出现次数比较少或者在很多文档中都出现了,则他的所占的比重就比较小。
用来干嘛?描述一篇文章。计算文章的相似性。
基于用户的协同过滤算法描述
如何找到有相似爱好的人?计算数据相似度!
-
杰卡德相似系数(Jaccard similarity coefficient)
J ( A , B ) = A ∩ B A ∪ B J(A,B)=\frac{A\cap B}{A \cup B} J(A,B)=A∪BA∩B
-
夹角余弦(Cosine)
向量A和向量B的夹角余弦公式
c o s ( θ ) = a ⋅ b ∣ a ∣ ∣ b ∣ cos(\theta)=\frac{a\cdot b}{|a||b|} cos(θ)=∣a∣∣b∣a⋅b
-
其余方法:欧式距离、曼哈顿距离

首先找到最相似的几个人,怎么找?计算相似度!
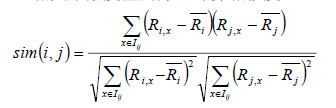
该公式要计算用户i和用户j之间的相似度,I(i, j)是代表用户i和用户j共同评价过的物品,R(i,x)代表用户i对用户x的评分,R(i)头上有一杠的代表用户i所有评分的平均分, 之所以要减去平均分是因为有的用户打分严有的松, 归一化用户打分避免相互影响。
找到最相似的几个人之后,基于这些相似的人,对于某一个我还未喜欢的物品计算加权分数,得分最高的物品被推荐。
- 构造倒排表
- 建立共现矩阵
- 计算用户与用户间的相似度
基于物品的协同过滤算法描述
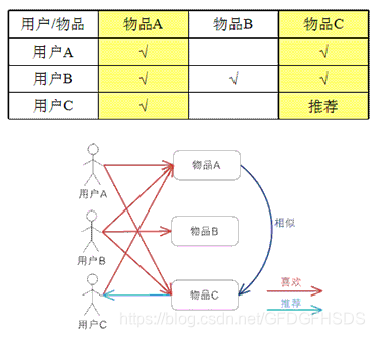
计算公式:
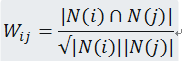
|N(i)|表示喜欢物品i的用户数,|N(j)|表示喜欢物品j的用户数, |N(i)∩N(j)|表示同时喜欢物品i和物品j的用户数。从上面的公式我们可以看出物品i和物品j相似是因为他们共同别很多的用户喜欢,相似度越高表示同时喜欢他们的用户数越多。
存在的问题:
-
稀疏矩阵问题
当用户与产品评分成千上万时,矩阵会很大,而且很多会是空白的,使用计算机处理这样的矩阵会浪费内存,浪费时间。
- 构造倒排表
- 建立共现矩阵
- 计算用户与用户间的相似度
隐语义模型(Latent Factor Model)
矩阵分解模型(Matrix Factor Model)
对于m个用户和n个商品,将会有一个 m × n m\times n m×n的矩阵,矩阵元素为用户对物品的喜好程度或者评分。将该矩阵分解为两个矩阵,一个为 m × k m\times k m×k的矩阵,另一个为 k × n k\times n k×n的矩阵。每一个用户和每一个物品都用一个k维的向量表达,两个向量的内积代表了某用户对某物品的喜好程度。同时还可以计算用户间的相似性,物品间的相似性等。
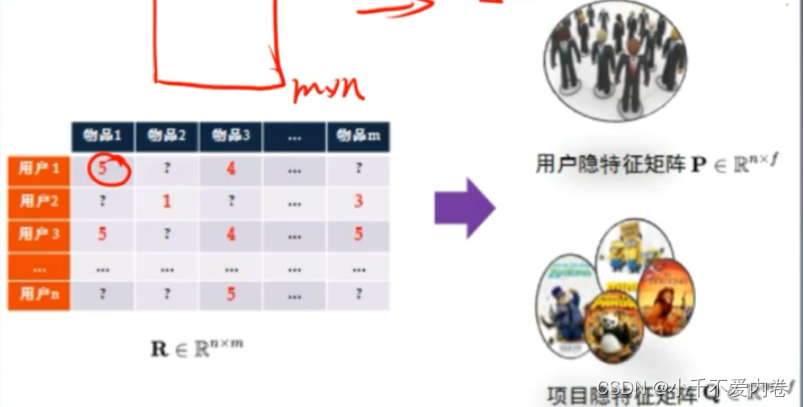
求解方法:
- 特征值分解
- 奇异值分解
- 梯度下降
基于兴趣分类的方法,可以对物品的兴趣进行分类。对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品。
公式: p ( u , i ) = r u i = p u T q i = ∑ f = 1 F p u , k q i , k p(u, i)=r_{ui}=p_u^Tq_i=\sum_{f=1}^{F}p_{u,k}q_{i,k} p(u,i)=rui=puTqi=∑f=1Fpu,kqi,k
p u , k p_{u,k} pu,k为用户u对k这一类别的喜好程度, q i , k q_{i,k} qi,k为物品i属于k这一类别的可能性。这实际上就是一个矩阵分解的过程。
- 如何给物品进行分类?
- 如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度?
- 对于一个给定的类,选择哪些属于这个类的物品推荐给用户,如何确定这些物品在一个类中的权重?
基于图的模型
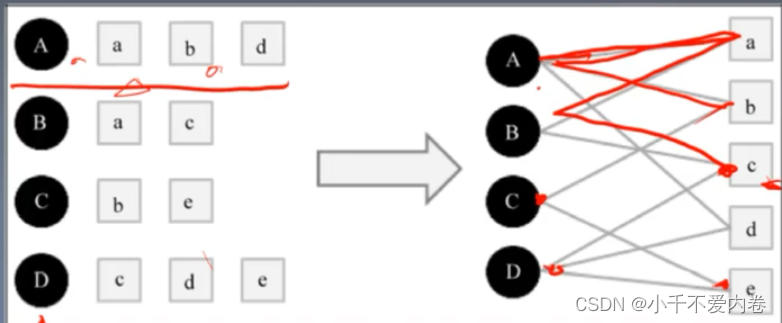
相关性高的特征:
- 两个顶点之间有很多条路径相连。
- 连接两个顶点之间的路径长度都比较短。
- 链接两个顶点之间的路径不会经过出度比较大的项。
基于内容的推荐算法
-
概念
基于标的物相关信息、用户相关信息及用户对标的物的操作行为来构建推荐算法模型,为用户提供推荐服务。这里的标的物相关信息可以是对标的物文字描述的metadata信息、标签、用户评论、人工标注的信息等。用户相关信息是指人口统计学信息(如年龄、性别、偏好、地域、收入等等)。用户对标的物的操作行为可以是评论、收藏、点赞、观看、浏览、点击、加购物车、购买等。基于内容的推荐算法一般只依赖于用户自身的行为为用户提供推荐,不涉及到其他用户的行为。
-
实现原理
-
与基于物品的协同过滤算法之间的区别
协同过滤算法仅仅通过了解用户与物品之间的关系进行推荐,不会考虑物品本身的属性,但是基于内容的算法会考虑到物品本身的属性,它会以物品本身的特征为基准去找相似的物品。
-
一般有三个步骤:
-
基于用户信息及用户操作行为构建用户特征表示。
-
基于标的物信息构建标的物的物特征表示。
-
基于用户及标的物特征表示为用户推荐标的物。
-
Logistics回归
离线训练:Spark、sklearn、Tensorflow等将各种特征组合都进行训练,比如某个用户(uid)和物品(item)两个特征交叉得到的特征进行训练,就会得到针对于uid这个用户的对于特征为item的物品的超平面,将权重保存下来。
线上使用时,可能会输入很多个特征组合,然后在保存的权重文件中寻找对应的权重,取出来直接进行计算,得到对应的分类结果。
LS-PLM(Large Scale Piece-wise Linear Model)大规模分段线性模型
或者叫MLR(Mixed Logistic Regression)混合逻辑回归

可以理解为是一个集成算法。
聚类:将样本进行分类,比如依据用户进行分类(男性、女性),每个类别都训练一个LR模型,经过聚类之后,会对每个类别都有一个可能性的值。将这个可能性当作权重进行多个LR模型的集成。
基于特征交叉的推荐算法
普通线性模型,各个特征独立考虑,特征线性组合经激活函数后交叉性弱。
大量特征之间是存在关联性的。
非线性增强。
信息区分性更强。















 3533
3533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









