







 本文详细介绍了粒子群优化算法的实现过程,包括参数设定、粒子群初始化、速度和位置更新、个体极值和群体极值的计算,以及迭代寻优的逻辑。通过代码展示了如何使用PSO算法求解优化问题,并可视化了最优个体适应值随迭代次数的变化。
本文详细介绍了粒子群优化算法的实现过程,包括参数设定、粒子群初始化、速度和位置更新、个体极值和群体极值的计算,以及迭代寻优的逻辑。通过代码展示了如何使用PSO算法求解优化问题,并可视化了最优个体适应值随迭代次数的变化。
之前一篇论文在研究智能优化算法,较为权威且常用的如粒子群寻优、遗传算法、模拟退火算法等等,整理几个较为经典的算法如下,本篇主要是粒子群算法,算法的理论部分就不赘述了。
此代码已跑通
%PSO算法
clc % 清屏
clear all; % 删除workplace变量
close all; % 关掉显示图形窗口
tic;
%% 参数设置
w = 0.6; % 惯性因子 (0~1之间,不宜过大或过小)
c1 = 2; % 加速常数
c2 = 2; % 加速常数
Dim = 3; % 维数
SwarmSize =30; % 粒子群规模
MaxIter = 100; % 最大迭代次数
MinFit = 0; % 最小适应值
Vmax = 1;
Vmin = -1;% 对速度范围进行限制
Ub = [10 10 10];
Lb = [0 0 0];%对位置进行限制
%% 粒子群初始化(每个粒子的位置和速度都是一个1行3列的矩阵,共100个粒子
%即整体的位置和速度均为为100行3列的矩阵 )
Range = ones(SwarmSize,1)*(Ub-Lb);%100行1列 乘以 1行3列得 100行3列元素均为10的矩阵
Swarm = rand(SwarmSize,Dim).*Range + ones(SwarmSize,1)*Lb; % 初始化粒子群(是一个位置信息100行3列)
%内部元素均为0~50之间
VStep = rand(SwarmSize,Dim)*(Vmax-Vmin) + Vmin; % 初始化速度(100行3列,每个元素在-1~1之间)
%矩阵加常值默认为每个元素都加Vmin
%亦可为VStep = rand(SwarmSize,Dim)*(Vmax-Vmin) +ones(SwarmSize,Dim)* Vmin;
fSwarm = zeros(SwarmSize,1);%产生一个元素均为0得100行1列得矩阵
%可认为为“空”矩阵,用于存放后续迭代得到的100个粒子的适应值
for i=1:SwarmSize%依次求出每个粒子的适应值
fSwarm(i,:) = @(Swarm(i,:)); % 粒子群的适应值,此处的function函数是自己的适应度函数
% 此适应度函数由另一个文件编写,也可以和该程序合为一个程序
end
%% 个体极值和群体极值
[bestf,bestindex]=min(fSwarm);%fswarm中每列最小元素为bestf,最小元素的位置为(每列由上到下)bestindex)
%fswarm为100行1列的矩阵,bestindex属于0~100,即第bestindex个粒子经过100次迭代取得全局最小适应度值bestf;
zbest=Swarm(bestindex,:); % 全局最佳。100个粒子经过100次迭代,第bestindex个粒子(fSwarm值最小)对应位置,3行1列。
gbest=Swarm; % 个体最佳。第一个最佳值由初始化随机产生,若后来迭代出有更小值,用该值取代之。
%第i个粒子经过100次迭代中使第i个粒子适应值最小的位置。(只和自己适应值比较,不和其他99个比较)
fgbest=fSwarm; % 个体最佳适应值。100个粒子经过100次迭代,每,100行1列
fzbest=bestf; % 全局最佳适应值。100个粒子产生各自的最小适应值中再比较选出全局最小适应值
%(需要知道那个粒子(第bestindex个)对应该全局最小适应值及该粒子对应位置信息(zbest))
%%
while fzbest > MaxFit
for i=1:SwarmSize
Swarm(i,:)=[0.001 100 3];
fSwarm(i,:) = gpc_1(Swarm(i,:));
end
[bestf,bestindex]=min(fSwarm);%fswarm中每列最小元素为bestf,最小元素的位置为(每列由上到下)bestindex)
%fswarm为100行1列的矩阵,bestindex属于0~100,即第bestindex个粒子经过100次迭代取得全局最小适应度值bestf;
zbest=Swarm(bestindex,:); % 全局最佳。100个粒子经过100次迭代,第bestindex个粒子(fSwarm值最小)对应位置,3行1列。
gbest=Swarm; % 个体最佳。第一个最佳值由初始化随机产生,若后来迭代出有更小值,用该值取代之。
%第i个粒子经过100次迭代中使第i个粒子适应值最小的位置。(只和自己适应值比较,不和其他99个比较)
fgbest=fSwarm; % 个体最佳适应值。100个粒子经过100次迭代,每,100行1列
fzbest=bestf;
end
%% 迭代寻优
iter = 0;%第零次迭代(未迭代)
y_fitness = zeros(1,MaxIter); % 本行及以下3行预先产生4个“空”(元素为零)矩阵(1列100行)
thetae_1 = zeros(1,MaxIter); %用于放100次迭代产生的前全局最佳位置对应的三维行向量第一个值
P = zeros(1,MaxIter);%用于放100次迭代产生的前全局最佳位置对应的三维行向量第二个值
gamma = zeros(1,MaxIter);%用于放100次迭代产生的前全局最佳位置对应的三维行向量第三个值
while( (iter < MaxIter) && (fzbest > MinFit))%迭代次数不到100次并且全局最佳值(指适应度值)大于0.1才执行。否则跳出循环。
for j=1:SwarmSize%对100个粒子,每一次迭代依次对每个粒子的位置、速度、适应值进行更新
% 速度更新
VStep(j,:) = w*VStep(j,:) + c1*rand*(gbest(j,:) - Swarm(j,:)) + c2*rand*(zbest - Swarm(j,:));
%rand-等概率的产生一个0~1之间的数(以增加对个体最佳和全局最佳的搜索)
if VStep(j,:)>Vmax, VStep(j,:)=Vmax; end%若第j个粒子速度超过最大速度,令该粒子速度等于最大速度
if VStep(j,:)<Vmin, VStep(j,:)=Vmin; end%若第j个粒子速度低于最小速度,令该粒子速度等于最小速度
% 位置更新
Swarm(j,:)=Swarm(j,:)+VStep(j,:);%位置为什么等于先前位置加速度而不是加VStep(j,:)*T呢?
%可以这样理解:间隔迭代时间为T(这个T理解为单位时间,同现实中单位时间为1s含义一样,只不过T不等于1s)
%每个粒子每隔T走一步(一步一迭代),即单位时间内走一步,所以距离等于速度(值得注意的是粒子速度是阶跃的,阶跃的距离是随机的)
for k=1:Dim
if Swarm(j,k)>Ub(k), Swarm(j,k)=Ub(k); end%若第j个粒子位置超过最大位置边界值,令该粒子位置等于最大位置边界值
if Swarm(j,k)<Lb(k), Swarm(j,k)=Lb(k); end%若第j个粒子位置低于最小位置边界值,令该粒子位置等于最小位置边界值
end
% 适应值
fSwarm(j,:) =@(Swarm(j,:));
% 个体最优更新
if fSwarm(j) < fgbest(j)%若第j个粒子当前适应值小于先前个体最佳适应值
gbest(j,:) = Swarm(j,:);%令第j个粒子位置取代先前个体最佳位置(gbest(j,:) 用于“个体”记录位置信息,当这个“个体”取得全局最佳时,gbest(j,:)就给了 zbest )
fgbest(j) = fSwarm(j);%则令j个粒子当前适应值取代先前个体最佳适应值成为新的个体最佳适应值,否则先前个体最佳适应值不变(不断寻“小”的过程)
end
% 群体最优更新
if fSwarm(j) < fzbest%再已迭代步数的粒子中(每一次迭代,100个粒子的速度、位置、适应值fSwarm(j) 同时变化,fSwarm(j)与先前全局最佳适应值作比较 )
%若第j个粒子当前适应值小于先前全局最佳适应值
zbest = Swarm(j,:);%令第j个粒子位置取代先前全局最佳位置
fzbest = fSwarm(j);%则令j个粒子当前适应值取代先前全局最佳适应值成为新的全局最佳适应值,否则先前全局最佳适应值不变
end %%%要强调的是:第j个粒子当前适应值既要和 先前个体最佳适应值 作比较,又要和 先前全局最佳适应值 作比较。以保证全局最佳和个体最佳为“真”
end
iter = iter+1; % 迭代次数更新
y_fitness(1,iter) = fzbest; % 为绘图做准备 每一次迭代更新的fzbest(100个值)存放在 y_fitness(1,iter) (1行iter列)中,运行完毕后 y_fitness为1行100列
%zbest记录,每一步产生一个三维行向量。100步运行完毕后产生100行3列矩阵(100个3维向量)
thetae_1(1,iter) = zbest(1); %每一步当前全局最佳位置对应的三维向量(行向量)的第一个值给 K_p(1,iter) , 整体的K_p(1,iter)描述了zbest第一列元素的跨度
P(1,iter) = zbest(2);%每一步当前全局最佳位置对应的三维向量(行向量)的第二个值给 K_i(1,iter) ,整体的K_i(1,iter)描述了zbest第二列元素的跨度
gamma(1,iter) = zbest(3);%每一步当前全局最佳位置对应的三维向量(行向量)的第一个值给 K_d(1,iter) ,整体的K_p(1,iter)描述了zbest第三列元素的跨度
end
%%绘图
figure(1) % 绘制性能指标ITAE的变化曲线
plot(y_fitness,'LineWidth',2)
title('最优个体适应值','fontsize',10);
xlabel('迭代次数','fontsize',10);ylabel('适应值','fontsize',10);
set(gca,'Fontsize',10);
grid on
toc;结果如图:
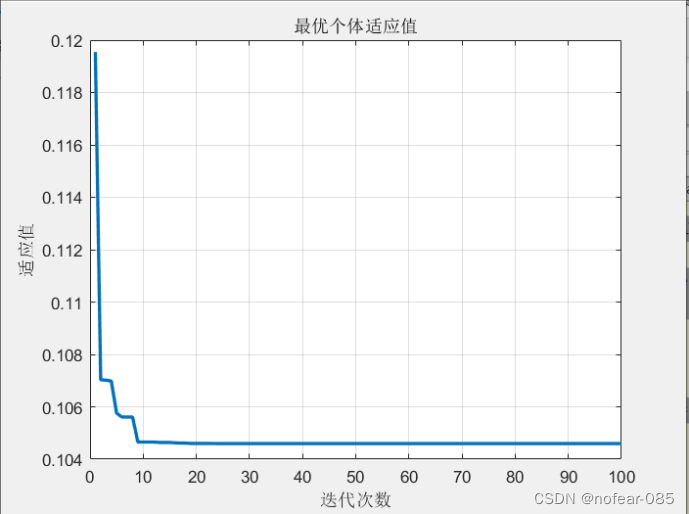
代码逻辑就在代码注释中,之后会将遗传算法和模拟退火算法等慢慢总结放上来。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











