







IO家族类层次体系结构横向匹配
上一篇文章中主要介绍了JavaIO流家族的整体设计思路,简单回顾下
基本逻辑涉及数据源 流的方向,以及流的数据形式这三个部分的组合
按照流的数据形式和流的方向,组合而来了四大家族,分别是:
InputStream/OutputStream Reader/Writer
数据源与四大家族的组合构成了IO流的基本功能
数据源形式 InputStream OutputStream Reader Writer ByteArray(字节数组) ByteArrayInputStream ByteArrayOutputStream 无 无 File(文件) FileInputStream FileOutputStream FileReader FileWriter Piped(管道) PipedInputStream PipedOutputStream PipedReader PipedWriter Object(对象) ObjectInputStream ObjectOutputStream 无 无 String StringBufferInputStream 无 StringReader StringWriter CharArray(字符数组) 无 无 CharArrayReader CharArrayWriter
扩展功能基本通过装饰器模式实现
扩展功能点 InputStream OutputStream Reader Writer Data(基本类型) DataInputStream DataOutputStream 无 无 Buffered(缓冲) BufferedInputStream BufferedOutputStream BufferedReader BufferedWriter LineNumber(行号) LineNumberInputStream 无 LineNumberReader 无 Pushback(回退) PushbackInputStream 无 PushbackReader 无 Print(打印) 无 PrintStream 无 PrintWriter
从上面的列表应该可以看得出来,对于IO体系中的主要的一些类和接口
我们只需要明确两点,就能够更加深入的了解他们
1.针对于各种数据源,四大家族的处理逻辑
2.扩展功能点的含义
注意:
很多IO的成员并不操作磁盘上的文件
比如ByteArrayInputStream和ByteArrayOutputStream 接下来我们还会详细的介绍到
他们并不直接操作持久化的数据(存储在磁盘上的),还有不少其他的也都不是的
他们跟IO有什么关系?为什么他们要实现流的接口?
此处我想要提醒的是,
对于我们程序设计语言来说,IO 表示的是对数据的操纵,数据有读写
IO代表的是一类可读可写行为类似的事物,而不是指从磁盘上读取文件
为什么不是有一个单纯的类去进行对于字节数组的操作呢,为什么非要跟IO挂钩沾边?
首先,这并不是不可以,
的确是可以构造一个跟IO体系结构没关系的字节数组
来操纵类进行字节数组的读写
可是,他的行为显然跟IO非常的类似,在定义一套不同的接口显然增加开发者使用成本
再者,不管从哪里读 ,本身也仍旧是输入输出的问题
而且,针对不同的数据源提供一致性的接口,这也非常的符合面向接口的编程规范
所以,一句话,不要把IO狭隘地理解为操作磁盘上的文件.数据.
IO是输入与输出,是读与写的代名词
IO数据源应用
ByteArray(字节数组)
| 字节数组,毫无疑问,不会应用在字符家族里面 他应用于 ByteArrayInputStream 以及 ByteArrayOutputStream 他的内部包含一个 字节数组 byte buf[] ByteArrayInputStream 以及 ByteArrayOutputStream 内部维护了一个byte buf[] 会将数据读取到这个字节数组(缓冲区) 或者将数据写入到这个字节数组(缓冲区) 他们维护的是这个内部的字节数组本身,并不会写入文件 |
这两个类本质就是操纵字节数组,提供对字节数组的读取与写入
它的本质如同文件一样,都是用来存储数据
只不过是数据存在于内存中而已
通过将数据封装到内部的字符数组中,可以提供IO一致性的接口 ByteArray 仅仅应用与字节流

File(文件)
| 前面说过,File 是最常见的一种数据形式 所以对IO提供针对文件的操作非常合理 我们知道,所有的数据存储最终都是字节的形式 但是对于文件的操作又是如此的频繁和重要 所以,针对于字符的输入输出也提供了对应的处理 不过还是那句话,最终文件都是字节形式存储,所以,对于字符文件,自然需要进行编码与解码 FilterReader每一次的读取都意味着一次解码 FilterWriter每一次的写入都意味着编码 |
既然是文件,我们前面介绍过File类
File类的构造主要由路径名或者文件描述符
所以对于文件的输入输出相关的IO操作,自然可以通过 路径名 文件描述符 或者File 本身作为目标对象
也就是说构造函数的参数一般都是这三者之一
对于文件的操作是实实在在的操作文件本身
File 四大家族都有应用
Piped(管道)
| 管道的概念,不是来自于java io很早前就有此概念 含义非常明朗,就如同他的名字一样,管道,好像两个水管连接起来,形成一个通道 这个通道是直接连接的,并不会再跑到别的地方去弯弯绕 管道流的主要作用是可以进行两个线程间的通讯 既然主要作用进行线程间的通讯,他就是传输数据使用的 IN 字节数组缓存数据,OUT使用IN对象  |
| 管道在四大家族中都有应用 |
Object
| ObjectInputStream 和 ObjectOutputStream 的作用是,对基本数据和对象进行序列化操作支持 ObjectOutputStream对象能提供对“基本数据或对象”的持久存储 ObjectInputStream,读取出这些“基本数据或对象” 只有支持 java.io.Serializable 或 java.io.Externalizable 接口的对象才能被ObjectInputStream/ObjectOutputStream所操作 |
序列化自然不可能就只有字符,所以Object仅仅针对字节家族
String
| 提供了对String类型的支持 reader读取到String writer写入到StringBuffer |
 |
| StringBufferInputStream 已经不推荐使用了 所以,后续可以认为String仅仅支持字符家族 |
CharArray
| 类似ByteArray,也是提供对字符数组的支持 操纵内存数据 |
 字符数组仅仅支持字符家族
字符数组仅仅支持字符家族
其实可以看得出来,只有File才是真正跟磁盘文件相关的
其他的数据源形式都是操作内存数据
IO扩展功能应用
Data(基本类型)
| Data是对基本数据类型的支持 针对于DataOutputStream写出的数据文件 可以使用DataInputStream进行读取 也就是说是一种特殊形式的文件 |
他们底层依赖的还是字节流 通过继承FilterInputStream 和 FilterOutputStream
使用其中的InputStream in 以及 OutputStream out
这两个对象是通过构造方法传递进来的
Buffered(缓冲)
| 缓冲也就是为了减少读取的频率,设置一个缓冲区 缓冲的概念到处都是,所以缓冲应用于四大家族 |
LineNumber(行号)
| LineNumber是针对输入的 所以存在于LineNumberInputStream和LineNumberReader 不过对于字节流的LineNumberInputStream 已经弃用 |
LineNumberReader是一个跟踪行号的缓冲字符输入流
也很显然,流都是顺序读取不能回退的,所以想要读取行号自然要借助于缓存
他的实现继承BufferedReader 也很好理解
Pushback
| Pushback 回退,也就是读取了一个字符,然后再次把它放回到流中 所以是针对输入的 PushbackInputStream PushbackReader 也是借助于内部的缓存 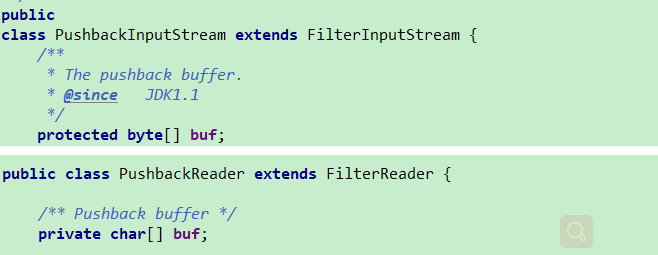 |
Print(打印)
| 主要是为了提供数据打印的便利性 |
打印自然是针对于输出的
PrintStream PrintWriter
本文从数据源以及扩展功能点的角度,再次分析了IO类库的整体设计
虽然上一篇文章中对于所有的基本功能点以及扩展功能点已经做了一个介绍
本文再次提及是为了着重强调,数据源与扩展功能点在类层次结构中涉及的重要性
只有彻底明确了数据源以及扩展功能点的逻辑
才能彻底理解整个IO类库架构设计
















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









