






课程地址:(4)XTuner 大模型单卡低成本微调实战_哔哩哔哩_bilibili
课程文档:https://github.com/InternLM/tutorial/blob/main/xtuner/README.md
XTuner:https://github.com/internLM/xtuner
一、Finetune简介
LLM 的下游应用中,增量预训练和指令跟随是经常会用到两种的微调模式;
1、增量预训练微调
- 使用场景: 让基座模型学习到一些新知识,如某个垂类领域的常识
- 训练数据:文章、书籍、代码等

2、指令跟随微调
- 使用场景:让模型学会对话模板,根据人类指令进行对话
- 训练数据:高质量的对话、问答数据

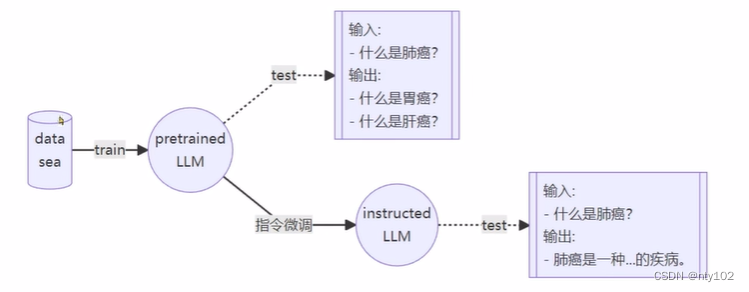

不同模型的对话模板均不相同;


二、LoRA & QLoRA
LLM 的参数量主要集中在模型中的 Linear,训练这些参数会耗费大量的显存;
LORA 通过在原本的 Linear 旁,新增一个支路,包含两个连续的小 Lnear.新增的这个支路通常叫做 Adapter;
Adapter 参数量远小于原本的 Linear,能大幅降低训练的显存消耗;


三、Xtuner简介
1,适配多种生态
- 多种微调算法
多种微调策略与算法,覆盖各类 SFT 场
- 适配多种开源生态
支持加载 HuggingFace、ModelScope 模型或数据集
- 自动优化加速
开发者无需关注复杂的显存优化与计算加速细节
2、适配多种硬件
- 训练方案覆盖NVIDIA20系以上所有显卡
- 最低只需8GB 显存即可微调 7B 模型


















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









