







BP神经网络主要用于预测和分类,对于大样本的数据,BP神经网络的预测效果较佳,BP神经网络包括输入层、输出层和隐含层三层,通过划分训练集和测试集可以完成模型的训练和预测,由于其简单的结构,可调整的参数多,训练算法也多,而且可操作性好,BP神经网络获得了非常广泛的应用,但是也存在着一些缺陷,例如学习收敛速度太慢、不能保证收敛到全局最小点、网络结构不易确定。另外,网络结构、初始连接权值和阈值的选择对网络训练的影响很大,但是又无法准确获得,针对这些特点可以采用遗传算法或粒子群算法等对神经网络进行优化。
目录
一、遗传算法优化bp神经网络
1.1、遗传算法优化bp神经网络流程
我们看一下下面的流程图,因为遗传算法优化参数是BP神经网络的初始权值和阈值,只要网络结构已知,权值和阈值的个数就已知了。神经网络的权值和阈值一般是通过随机初始化为[-0.5,0.5]区间的随机数,网络的训练结果是一样的,引入遗传算法就是为了优化出最佳的初始权值和阈值。
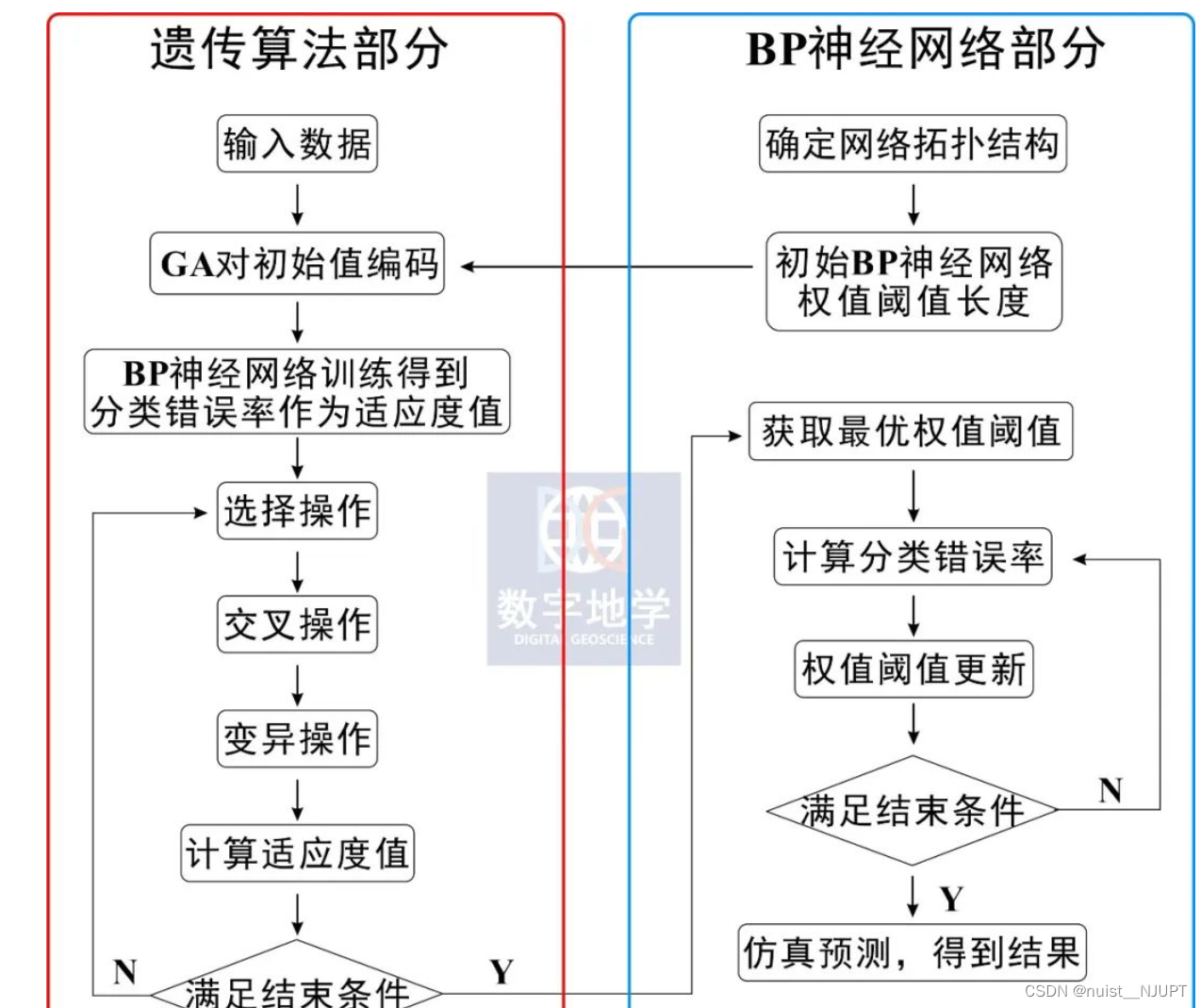
对于GA优化BP的问题,本次有三点需要说明:
1.bp神经网络的层数一般3层效果较好,即只包含输入层、一层的隐藏层、输出层。
2.bp神经网络的隐藏层神经元个数一般为输入层神经元个数的2倍再加1,即n1=n0*2+1。
3.我们用的是遗传算法工具箱来解决的问题,即使用谢菲尔德gatbx工具箱。
1.2、数据集介绍
本文是利用bp神经网络进行分类,是分类问题,当然也可以理解为预测问题,一共采取的共12组数据,其中9组数据作为训练,3组数据作为测试,数据如下:所有数据已经进行完归一化操作。
训练集输入数据如下:其中15*9,一共15个输入,每一列表示一个个体,一共9个个体,每个个体包含15个输入。

训练集的输出数据如下:一共9列,每一列代表一个类别。

测试集是三组,训练集是9组,这边就不放测试集的数据了。
1.3、遗传算法的实现bp优化
遗传算法优化BP神经网络是用遗传算法来优化BP神经网络的初始权重值和阈值,使优化后的BP神经网络能够更好地进行样本预测。遗传算法优化BP神经网络的要素包括种群初始化、适应度函数,选择算子、交叉算子和变异算子。
(1)种群初始化
个体编码使用二进制编码,每个个体均为一个二进制串,由输人层与隐含层连接权值、隐含层阈值、隐含层与输出层连接权值、输出层阈值四部分组成,每个权值和阈值使用M位的二进制编码,将所有权值和阈值的编码连接起来即为一个个体的编码。例如,本例的网络结构是15 - 31 - 3。
(2)适应度函数
本案例是为了使BP网络在预测时,预测值与期望值的残差尽可能小,所以选择预测样本的预测值与期望值的误差矩阵的范数作为目标函数的输出。适应度函数采用排序的适应度分配函数:FitnV = ranking(obj),其中obj为目标函数的输出。
(3)选择算子
选择算子采用随机遍历抽样(sus)。
(4)交叉算子
交叉算子采用最简单的单点交叉算子。
(5)变异算子
变异以一定概率产生变异基因数,用随机方法选出发生变异的基因。如果所选的基因的编码为1,则变为0;反之,则变为1。
我们输入层有15个神经元,隐藏层有31个神经元,输出层有3个(我们这里做的是3分类问题),那么w1就有31x15个,b1有31个;w2有15x3个,b2有3个,一共加起来有592个参数。其次是关于种群初始化:我们设定有40个种群,这40个种群中每个种群都含有592个变量,且都需要用2进制表示。所以初始化时,需要生成40*5920维度的矩阵。
GA优化BP的matlab代码如下:
clc; clear
close all
%% 加载神经网络的训练样本,测试样本每列一个样本,输入P,输出T
% 样本数据就是前面问题描述中列出的数据
load('data.mat')
% 初始隐含层神经元个数
hiddennum = 31; % 输入层个数*2 + 1
% 输入向量的最大值和最小值
threshold = [0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1];
inputnum = size(P, 1); % 输入层神经元个数
outputnum = size(T, 1); % 输出层神经元个数
w1num = inputnum * hiddennum; % 输入层到隐含层的权值个数
w2num = outputnum * hiddennum; % 隐含层到输出层的权值个数
N = w1num + hiddennum + w2num + outputnum; % 待优化的变量个数
%% 定义遗传算法参数
NIND = 40; % 种群大小
MAXGEN = 50; % 最大遗传代数
PRECI = 10; % 个体长度
GGAP = 0.95; % 代沟
px = 0.7; % 交叉概率
pm = 0.01; % 变异概率
trace = zeros(N + 1, MAXGEN); % 寻优结果的初始值
FieldD = [repmat(PRECI, 1, N); repmat([-0.5; 0.5], 1, N); repmat([1;0;1;1], 1, N)]; % 区域描述器
Chrom = crtbp(NIND, PRECI * N); % 创建任意离散随机种群
%% 优化
gen = 0; % 代计数器
X = bs2rv(Chrom, FieldD);
[M, ~] = size(X);
Obj = zeros(M, 1);
for i = 1 : M
%所有个体预测样本预测误差的范数
x = X(i, :) ;
inputnum = size(P, 1); % 输入层神经元个数
outputnum = size(T, 1); % 输出层神经元个数
%% 新建BP网络
net = feedforwardnet(hiddennum);
net = configure(net, P, T);
net.layers{2}.transferFcn = 'logsig';
%% 设置网络参数:训练次数为1000次,训练目标为0.01,学习速率为0.1
net.trainParam.epochs = 1000;
net.trainParam.goal = 0.01;
net.trainParam.lr = 0.1;
net.trainParam.show = NaN;
net.trainParam.showwindow = false; % 使用高版本MATLAB不显示图形框
%% 神经网络初始权值和阈值
w1num = inputnum * hiddennum; % 输入层到隐含层的权值个数
w2num = outputnum * hiddennum; % 隐含层到输出层的权值个数
w1 = x(1 : w1num); % 初始输入层到隐含层的权值
B1 = x(w1num + 1 : w1num + hiddennum); % 隐含层神经元阈值
w2 = x(w1num + hiddennum + 1 : w1num + hiddennum + w2num); % 初始隐含层到输出层的权值
B2 = x(w1num + hiddennum + w2num + 1 : w1num + hiddennum + w2num + outputnum); % 输出层阈值
net.iw{1, 1} = reshape(w1, hiddennum, inputnum); % 输入层到隐含层的权值
net.lw{2, 1} = reshape(w2, outputnum, hiddennum); % 隐含层到输出层的权值
net.b{1} = reshape(B1, hiddennum, 1);
net.b{2} = reshape(B2, outputnum, 1);
%% 训练网络
net = train(net, P, T);
%% 测试网络
Y = sim(net, P_test);
err = norm(Y - T_test);
Obj(i) = err ;
end% 计算初始种群的十进制转换
ObjV = Obj; % 计算目标函数值,即遗传算法的适应度函数
while gen < MAXGEN
fprintf('%d\n', gen)
FitnV = ranking(ObjV); % 分配适应度值
SelCh = select('sus', Chrom, FitnV, GGAP); % 选择
SelCh = recombin('xovsp', SelCh, px); % 重组
SelCh = mut(SelCh, pm); % 变异
X = bs2rv(SelCh, FieldD); % 子代个体的二进制到十进制转换
ObjVSel = Objfun(X, P, T, hiddennum, P_test, T_test); % 计算子代的目标函数值
[Chrom, ObjV] = reins(Chrom, SelCh, 1, 1, ObjV, ObjVSel); % 将子代重插入到父代,得到新种群
X = bs2rv(Chrom, FieldD);
gen = gen + 1; % 代计数器增加
% 获取每代的最优解及其序号,Y为最优解,I为个体的序号
[Y, I] = min(ObjV);
trace(1: N, gen) = X(I, :); % 记下每代的最优值
trace(end, gen) = Y; % 记下每代的最优值
end
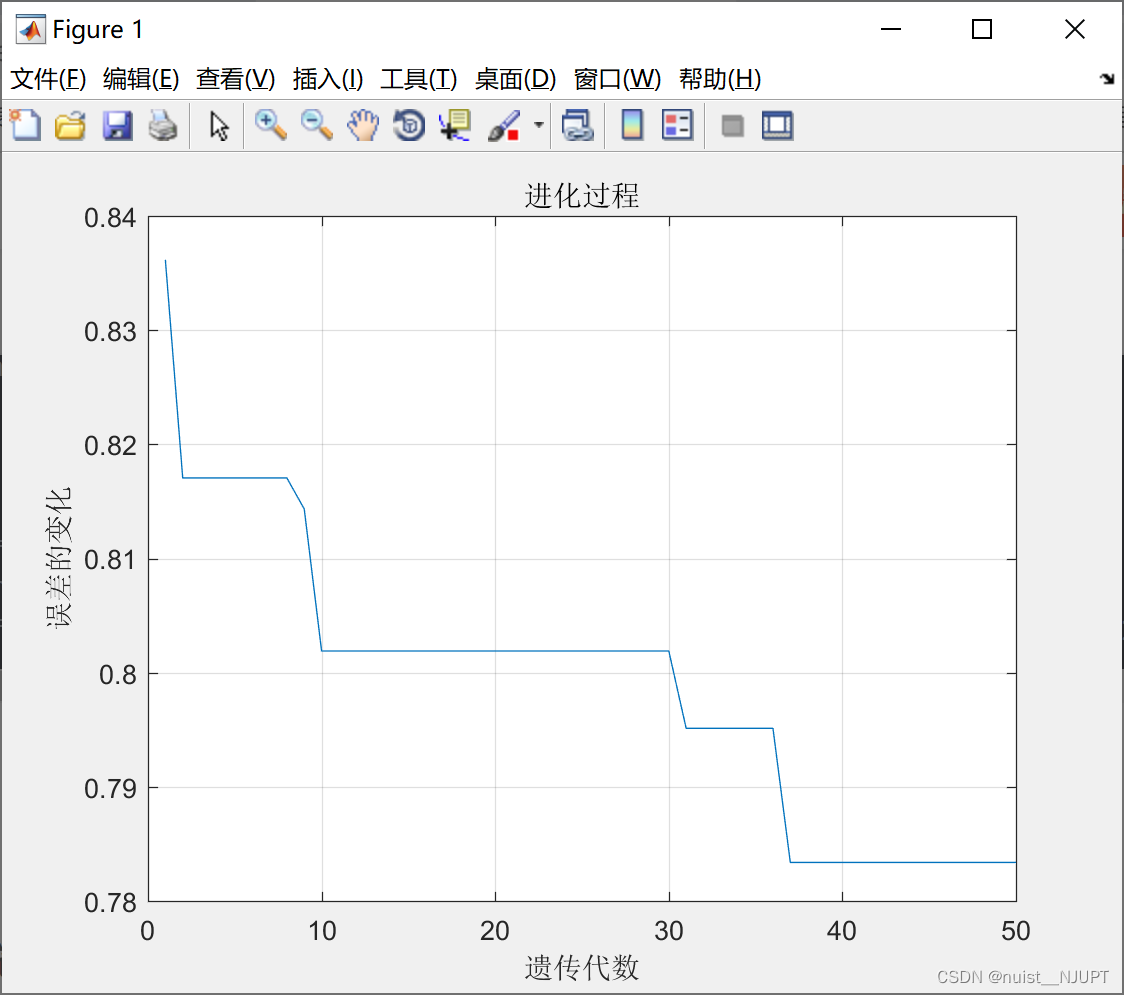
%% 画进化图
figure(1);
plot(1: MAXGEN, trace(end, :));
grid on
xlabel('遗传代数')
ylabel('误差的变化')
title('进化过程')
bestX = trace(1: end - 1, end);
bestErr = trace(end, end);
fprintf(['最优初始权值和阈值:\nX=', num2str(bestX'), '\n最小误差 err = ', num2str(bestErr), '\n'])我们可以看到每代的最优值,即适应度函数的最小值,即误差的最小值。随着代数的增加误差不端减小,由此我们可以找出初始化的权值和阈值。
1.4、传统bp和优化后的bp预测效果对比
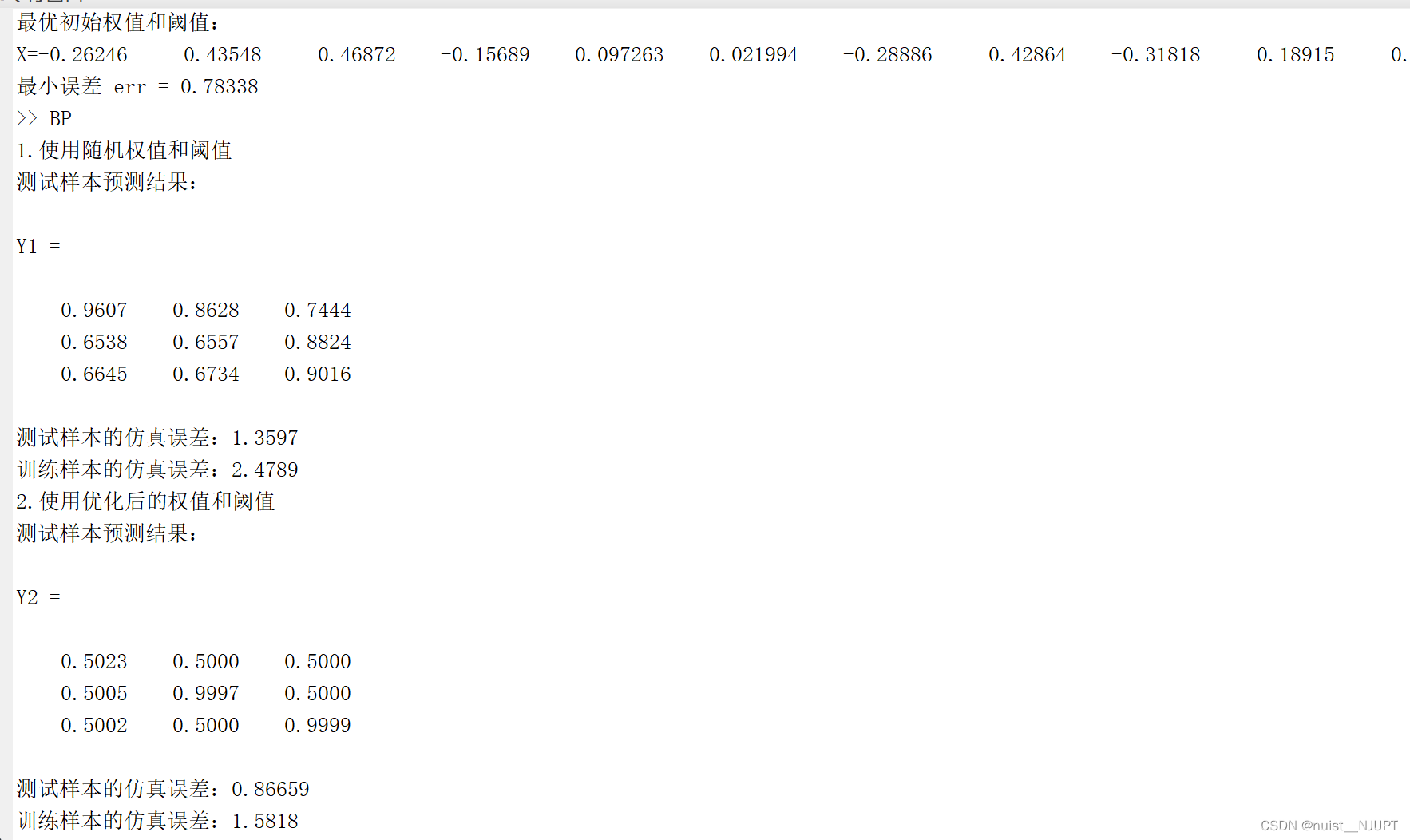
我们使用未优化的权值和阈值作为bp的参数去预测,同时将上面遗传算法优化后的权值和阈值代入bp神经网络进行预测,对预测误差进行对比,明显发现GA对bp的优化起到了效果。
%% 新建BP网络
hiddennum = 31 ;
net = feedforwardnet(hiddennum);
net = configure(net, P, T);
net.layers{2}.transferFcn = 'logsig';
%% 设置网络参数:训练次数为1000次,训练目标为0.01,学习速率为0.1
net.trainParam.epochs = 1000;
net.trainParam.goal = 0.01;
net.trainParam.lr = 0.1;
%% 训练网络
net = train(net, P, T);
%% 测试网络
disp('1.使用随机权值和阈值')
disp('测试样本预测结果:')
Y1 = sim(net, P_test)
err1 = norm(Y1 - T_test); % 测试样本的仿真误差
err11 = norm(sim(net, P) - T); % 训练样本的仿真误差
disp(['测试样本的仿真误差:', num2str(err1)])
disp(['训练样本的仿真误差:', num2str(err11)])
%% 使用优化后的权值和阈值
inputnum = size(P, 1); % 输入层神经元个数
outputnum = size(T, 1); % 输出层神经元个数
%% 新建BP网络
net = feedforwardnet(hiddennum);
net = configure(net, P, T);
net.layers{2}.transferFcn = 'logsig';
%% 设置网络参数:训练次数为1000次,训练目标为0.01,学习速率为0.1
net.trainParam.epochs = 1000;
net.trainParam.goal = 0.01;
net.trainParam.lr = 0.1;
%% BP神经网络初始化权值和阈值
w1num = inputnum * hiddennum; % 输入层到隐含层的权值个数
w2num = outputnum * hiddennum; % 隐含层到输出层的权值个数
w1 = bestX(1 : w1num); % 初始输入层到隐含层的权值
B1 = bestX(w1num + 1 : w1num + hiddennum); % 隐含层神经元阈值
w2 = bestX(w1num + hiddennum + 1 : w1num + hiddennum + w2num); % 初始隐含层到输出层的权值
B2 = bestX(w1num + hiddennum + w2num + 1 : w1num + hiddennum + w2num + outputnum); % 输出层阈值
net.iw{1, 1} = reshape(w1, hiddennum, inputnum); % 输入层到隐含层的权值
net.lw{2, 1} = reshape(w2, outputnum, hiddennum); %隐 含层到输出层的权值
net.b{1} = reshape(B1, hiddennum, 1);
net.b{2} = reshape(B2, outputnum, 1);
%% 训练网络
net = train(net, P, T);
%% 测试网络
disp('2.使用优化后的权值和阈值')
disp('测试样本预测结果:')
Y2 = sim(net, P_test)
err2 = norm(Y2 - T_test);
err21 = norm(sim(net, P) - T);
disp(['测试样本的仿真误差:', num2str(err2)])
disp(['训练样本的仿真误差:', num2str(err21)])运行的结果如下,由下图我们可以发现,通过GA优化后的bp神经网络的预测效果更佳,无论是训练集还是测试集,GA对bp的优化均更好。
1.5、小结
遗传算法优化BP神经网络的目的是通过遗传算法得到更好的网络初始权值和阈值,其基本思想就是用个体代表网络的初始权值和阈值,把预测样本的BP神经网络的测试误差的范数作为目标函数的输出,进而计算该个体的适应度值,通过选择、交叉、变异操作寻找最优个体,即最优的BP神经网络初始权值和阈值,然后通过BP神经网络进行预测,除了遗传算法之外,还可以采用粒子群算法、蚁群算法等优化BP神经网络初始权值和阈值。

















 631
631











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











