







Switch Transformer: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
下载地址:
https://arxiv.org/pdf/2101.03961.pdf
github 代码:https://github.com/tensorflow/mesh/blob/master/mesh_tensorflow/transformer/moe.py
公众号:AliceWanderAI
Introduction
作者在Introduction 中提出:
为了寻求更高的计算效率,我们提出了一种稀疏激活的专家模型:Switch Transformer。在我们的案例中,稀疏性来自为每个输入样本仅激活神经网络权重的子集。
For seeking greater computational efficiency, we propose a sparsely-activated expert model: the Switch Transformer. In our case the sparsity comes from activating a subset of the neural network weights for each incoming example.
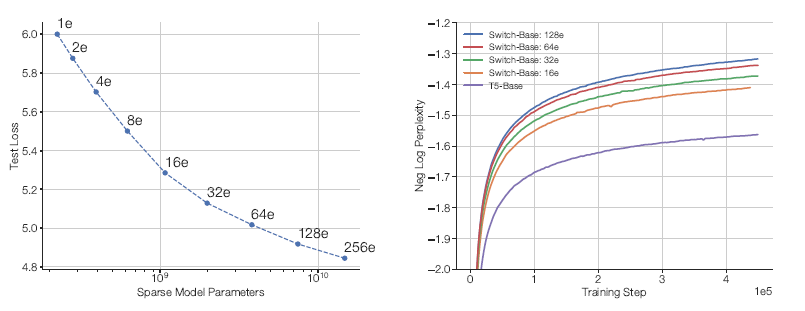
上面左图显示的是:sparse model
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1213
1213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









