







原文URL: http://blog.csdn.net/sun_168/article/details/20637833
推荐系统是当下越来越热的一个研究问题,无论在学术界还是在工业界都有很多优秀的人才参与其中。近几年举办的推荐系统比赛更是一次又一次地把推荐系统的研究推向了高潮,比如几年前的Neflix百万大奖赛,KDD CUP 2011的音乐推荐比赛,去年的百度电影推荐竞赛,还有最近的阿里巴巴大数据竞赛。这些比赛对推荐系统的发展都起到了很大的推动作用,使我们有机会接触到真实的工业界数据。我们利用这些数据可以更好地学习掌握推荐系统,这些数据网上很多,大家可以到网上下载。
推荐系统在工业领域中取得了巨大的成功,尤其是在电子商务中。很多电子商务网站利用推荐系统来提高销售收入,推荐系统为Amazon网站每年带来30%的销售收入。推荐系统在不同网站上应用的方式不同,这个不是本文的重点,如果感兴趣可以阅读《推荐系统实践》(人民邮电出版社,项亮)第一章内容。下面进入主题。
为了方便介绍,假设推荐系统中有用户集合有6个用户,即U={u1,u2,u3,u4,u5,u6},项目(物品)集合有7个项目,即V={v1,v2,v3,v4,v5,v6,v7},用户对项目的评分结合为R,用户对项目的评分范围是[0, 5]。R具体表示如下:
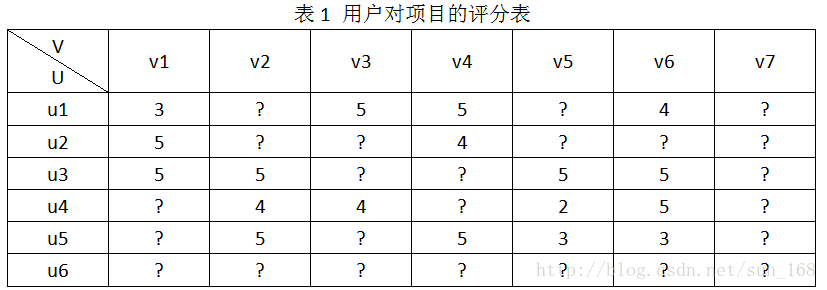
推荐系统的目标就是预测出符号“?”对应位置的分值。推荐系统基于这样一个假设:用户对项目的打分越高,表明用户越喜欢。因此,预测出用户对未评分项目的评分后,根据分值大小排序,把分值高的项目推荐给用户。怎么预测这些评分呢,方法大体上可以分为基于内容的推荐、协同过滤推荐和混合推荐三类,协同过滤算法进一步划分又可分为基于基于内存的推荐(memory-based)和基于模型的推荐(model-based),本文介绍的矩阵分解算法属于基于模型的推荐。
矩阵分解算法的数学理论基础是矩阵的行列变换。在《线性代数》中,我们知道矩阵A进行行变换相当于A左乘一个矩阵,矩阵A进行列变换等价于矩阵A右乘一个矩阵,因此矩阵A可以表示为A=PEQ=PQ(E是标准阵)。
矩阵分解目标就是把用户-项目评分矩阵R分解成用户因子矩阵和项目因子矩阵乘的形式,即R=UV,这里R是n×m, n =6, m =7,U是n×k,V是k×m。直观地表示如下:
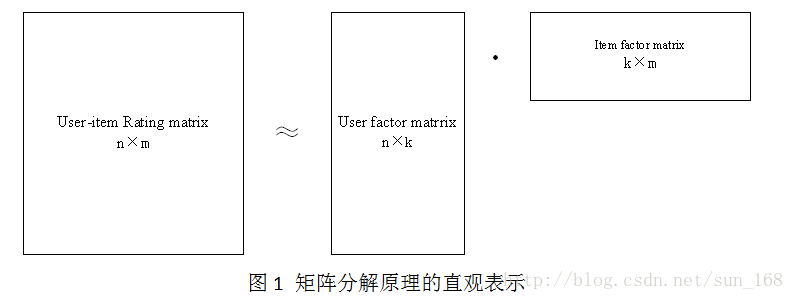
高维的用户-项目评分矩阵分解成为两个低维的用户因子矩阵和项目因子矩阵,因此矩阵分解和PCA不同,不是为了降维。用户i对项目j的评分r_ij =innerproduct(u_i, v_j),更一般的情况是r_ij =f(U_i, V_j),这里为了介绍方便就是用u_i和v_j内积的形式。下面介绍评估低维矩阵乘积拟合评分矩阵的方法。
首先假设,用户对项目的真实评分和预测评分之间的差服从高斯分布,基于这一假设,可推导出目标函数如下:
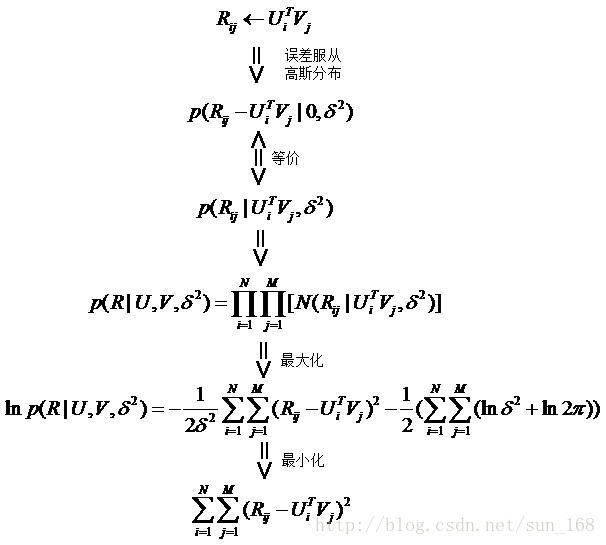
最后得到矩阵分解的目标函数如下:
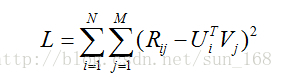
从最终得到得目标函数可以直观地理解,预测的分值就是尽量逼近真实的已知评分值。有了目标函数之后,下面就开始谈优化方法了,通常的优化方法分为两种:交叉最小二乘法(alternative least squares)和随机梯度下降法(stochastic gradient descent)。
首先介绍交叉最小二乘法,之所以交叉最小二乘法能够应用到这个目标函数主要是因为L对U和V都是凸函数。首先分别对用户因子向量和项目因子向量求偏导,令偏导等于0求驻点,具体解法如下:

上面就是用户因子向量和项目因子向量的更新公式,迭代更新公式即可找到可接受的局部最优解。迭代终止的条件下面会讲到。
接下来讲解随机梯度下降法,这个方法应用的最多。大致思想是让变量沿着目标函数负梯度的方向移动,直到移动到极小值点。直观的表示如下:
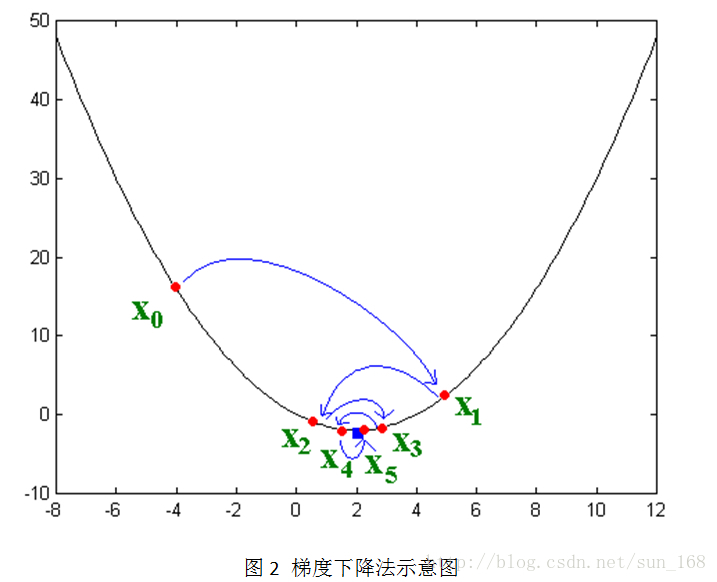
其实负梯度的负方向,当函数是凸函数时是函数值减小的方向走;当函数是凹函数时是往函数值增大的方向移动。而矩阵分解的目标函数L是凸函数,因此,通过梯度下降法我们能够得到目标函数L的极小值(理想情况是最小值)。
言归正传,通过上面的讲解,我们可以获取梯度下降算法的因子矩阵更新公式,具体如下: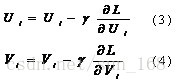
(3)和(4)中的γ指的是步长,也即是学习速率,它是一个超参数,需要调参确定。对于梯度见(1)和(2)。
下面说下迭代终止的条件。迭代终止的条件有很多种,就目前我了解的主要有
1) 设置一个阈值,当L函数值小于阈值时就停止迭代,不常用
2) 设置一个阈值,当前后两次函数值变化绝对值小于阈值时,停止迭代
3) 设置固定迭代次数
另外还有一个问题,当用户-项目评分矩阵R非常稀疏时,就会出现过拟合(overfitting)的问题,过拟合问题的解决方法就是正则化(regularization)。正则化其实就是在目标函数中加上用户因子向量和项目因子向量的二范数,当然也可以加上一范数。至于加上一范数还是二范数要看具体情况,一范数会使很多因子为0,从而减小模型大小,而二范数则不会它只能使因子接近于0,而不能使其为0,关于这个的介绍可参考论文Regression Shrinkage and Selection via the Lasso。引入正则化项后目标函数变为:
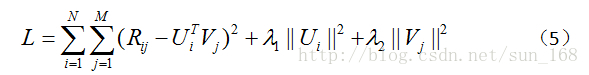
(5)中λ_1和λ_2是指正则项的权重,这两个值可以取一样,具体取值也需要根据数据集调参得到。优化方法和前面一样,只是梯度公式需要更新一下。
矩阵分解算法目前在推荐系统中应用非常广泛,对于使用RMSE作为评价指标的系统尤为明显,因为矩阵分解的目标就是使RMSE取值最小。但矩阵分解有其弱点,就是解释性差,不能很好为推荐结果做出解释。
后面会继续介绍矩阵分解算法的扩展性问题,就是如何加入隐反馈信息,加入时间信息等。
引用:
说明上图 图2摘自李金屏课件















 7238
7238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









