









1 简介
论文题目:Reading the Manual-Event Extraction as Definition Comprehension
论文来源:EMNLP 2020
论文链接:https://aclanthology.org/2020.spnlp-1.9.pdf
1.1 创新
- 提出一个新的事件抽取方法,通过使用bleached statements来利用注释指南,同时使用多-span选择模型来进行事件抽取。
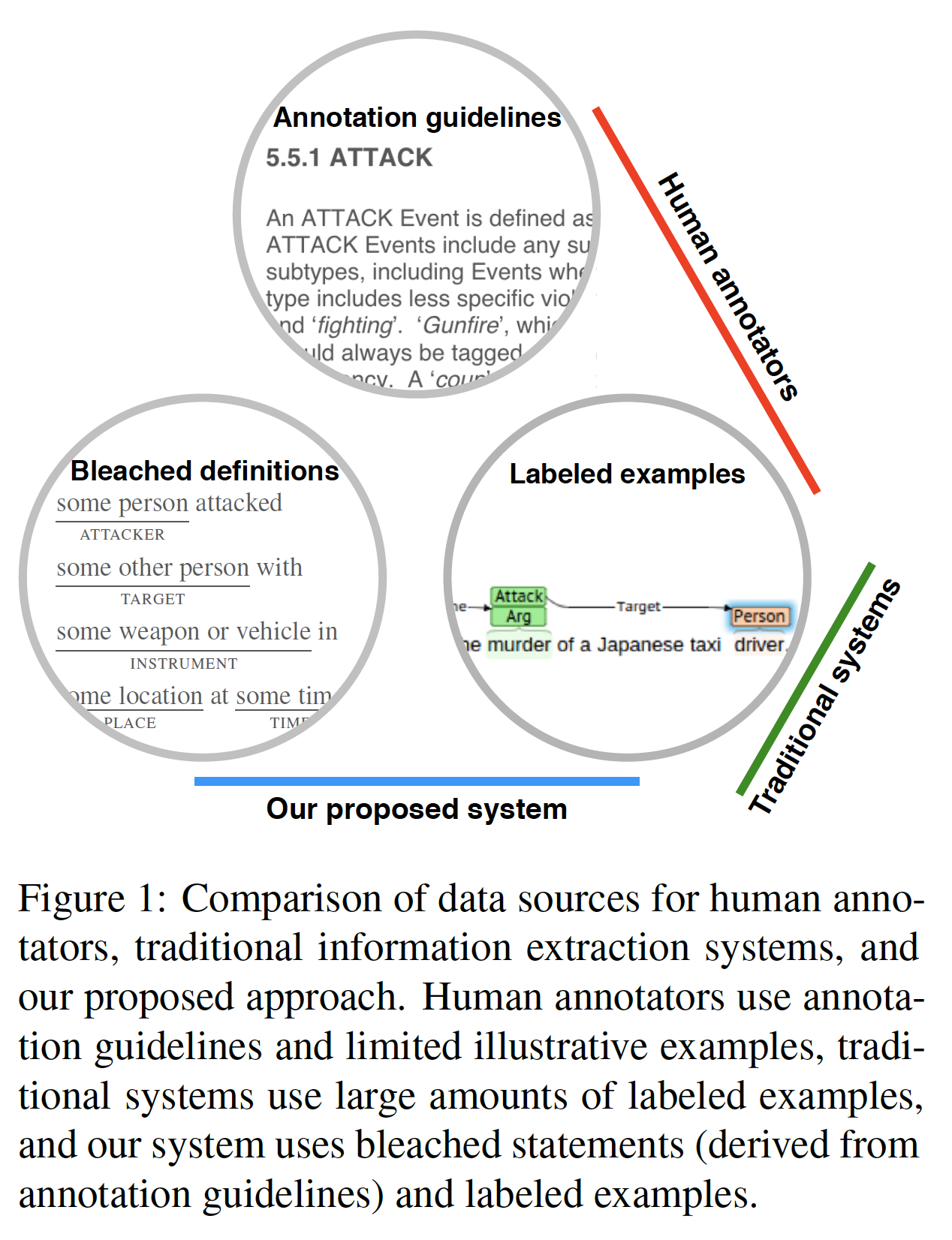
2 任务定义
一个bleached statement包含状态token
S
=
(
s
1
,
s
2
,
.
.
.
,
s
n
)
S=(s_1,s_2,...,s_n)
S=(s1,s2,...,sn),占位符字典
R
=
{
(
r
k
:
I
k
)
}
k
=
1
,
.
.
.
,
K
R=\{(r_k:I_k)\}_{k=1,...,K}
R={(rk:Ik)}k=1,...,K(分别表示论元角色和索引),一个例子如下:


将触发词定义为一种特殊的论元,因此,任务定义为给定一个bleached statement S、占位符词典R和文本tokenT,返回一个字典
R
^
\widehat{R}
R
(包含触发词和论元,如下图右下角)
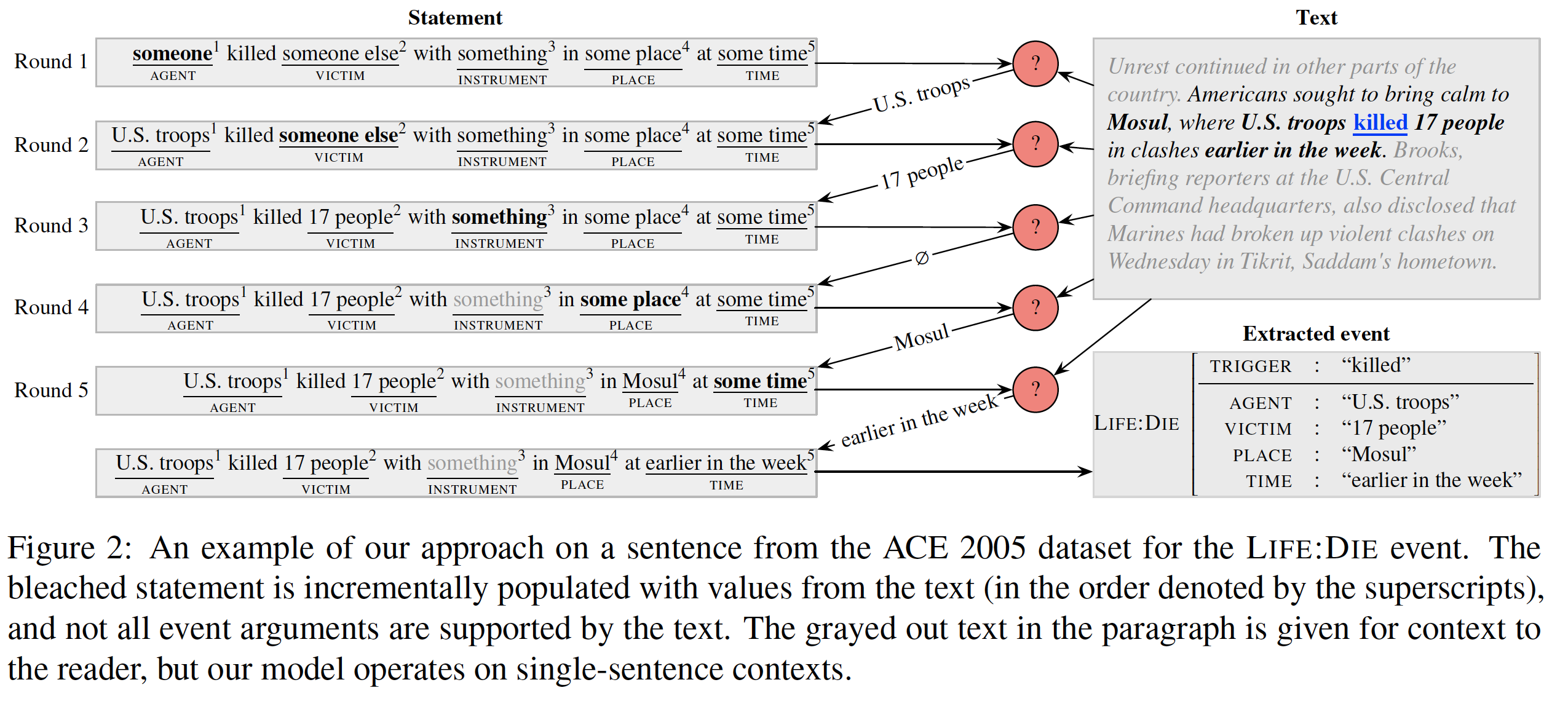
3 方法
给定带有多个占位符的bleached statement,增量式的填充每个占位符(从左到右逐步替换占位符,在训练中使用gold论元进行替换),公式为
A
←
G
E
T
A
R
G
S
(
S
,
I
,
T
)
A{\leftarrow}GETARGS(S,I,T)
A←GETARGS(S,I,T),如果返回为空,则不替换占位符,如果返回为多个论元,用and连接,算法过程如下图:

完整的事件抽取算法如下,首先进行触发词检测,然后进行论元抽取。

4 模型
首先使用BERT对bleached statement和文本编码,公式为BERT([CLS,s_1,…,s_n,SEP,t_1,…,t_m,SEP]),然后对文本进行BIO标注,公式如下:
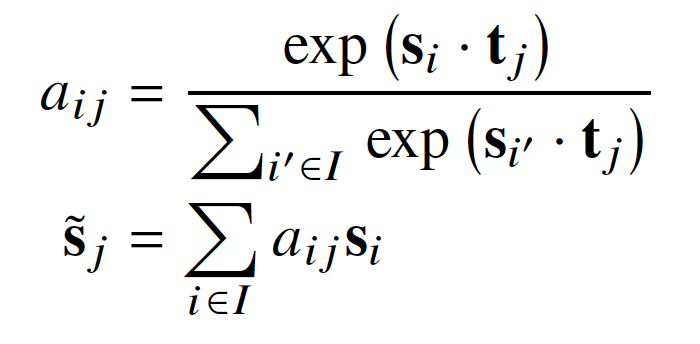
|
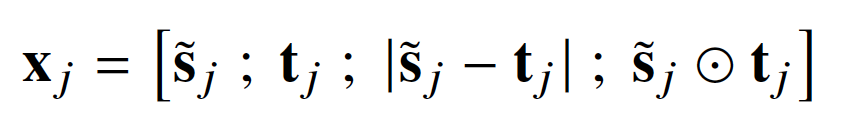
|
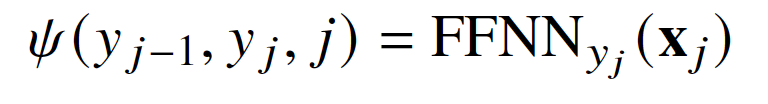
|
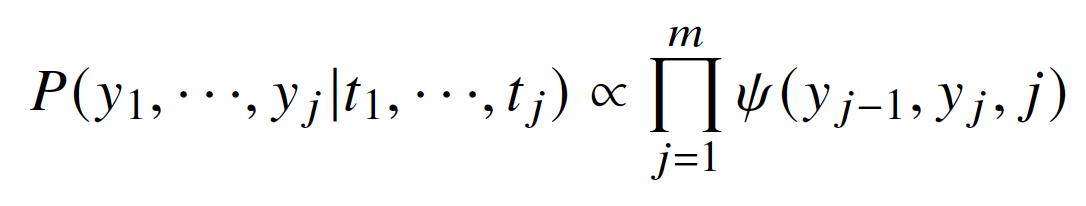
|
将触发词当作特殊的论元,使用论元选择模块进行触发词识别,触发词不属于任何论元。在事件检测中,通过设置样本中未出现的事件类型,进行负采样。
同时使用SQuAD 2.0进行预训练,问题设置主要为wh-question phrases,使用AllenNLP toolkit抽取出wh-phrases。
5 实验
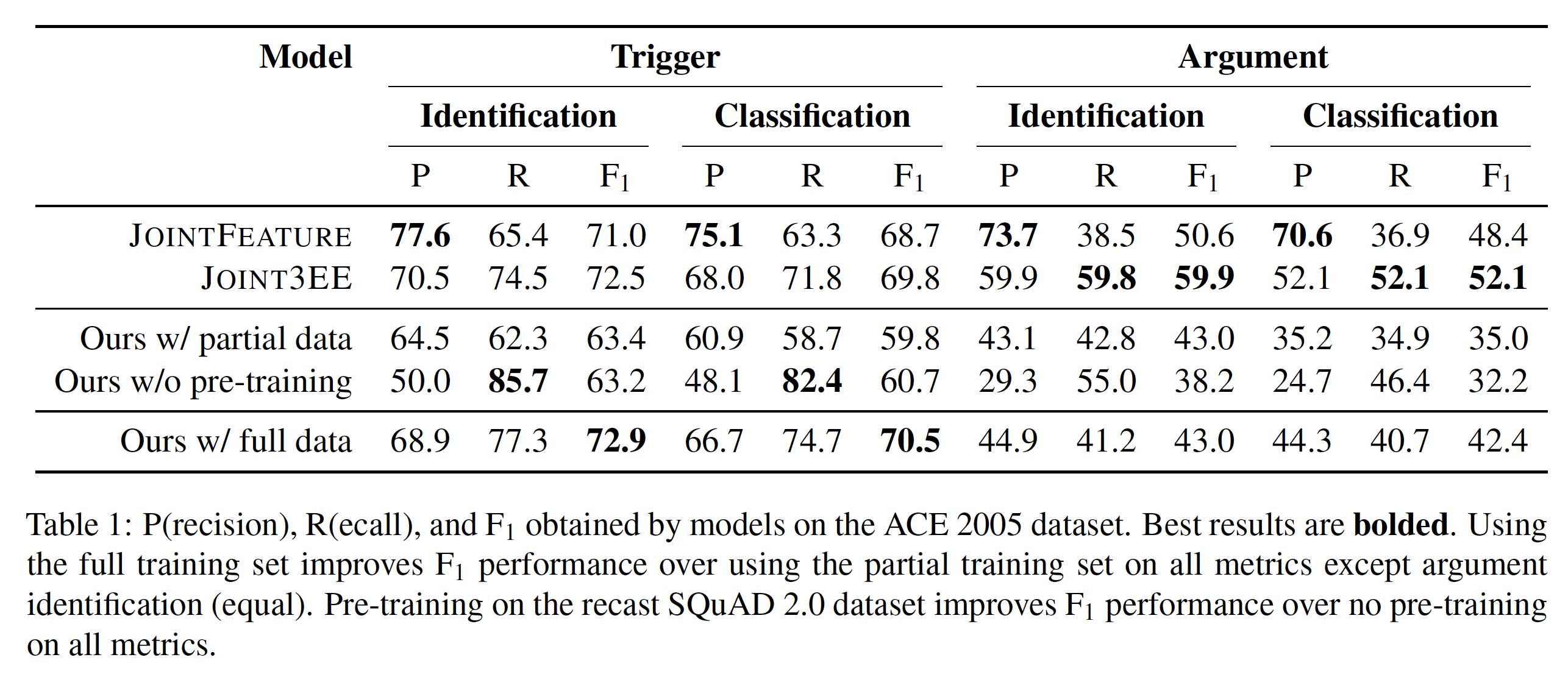
实验数据集为ACE 2005,实验结果如下图(使用部分数据为仅使用newswire的58个文档进行训练):
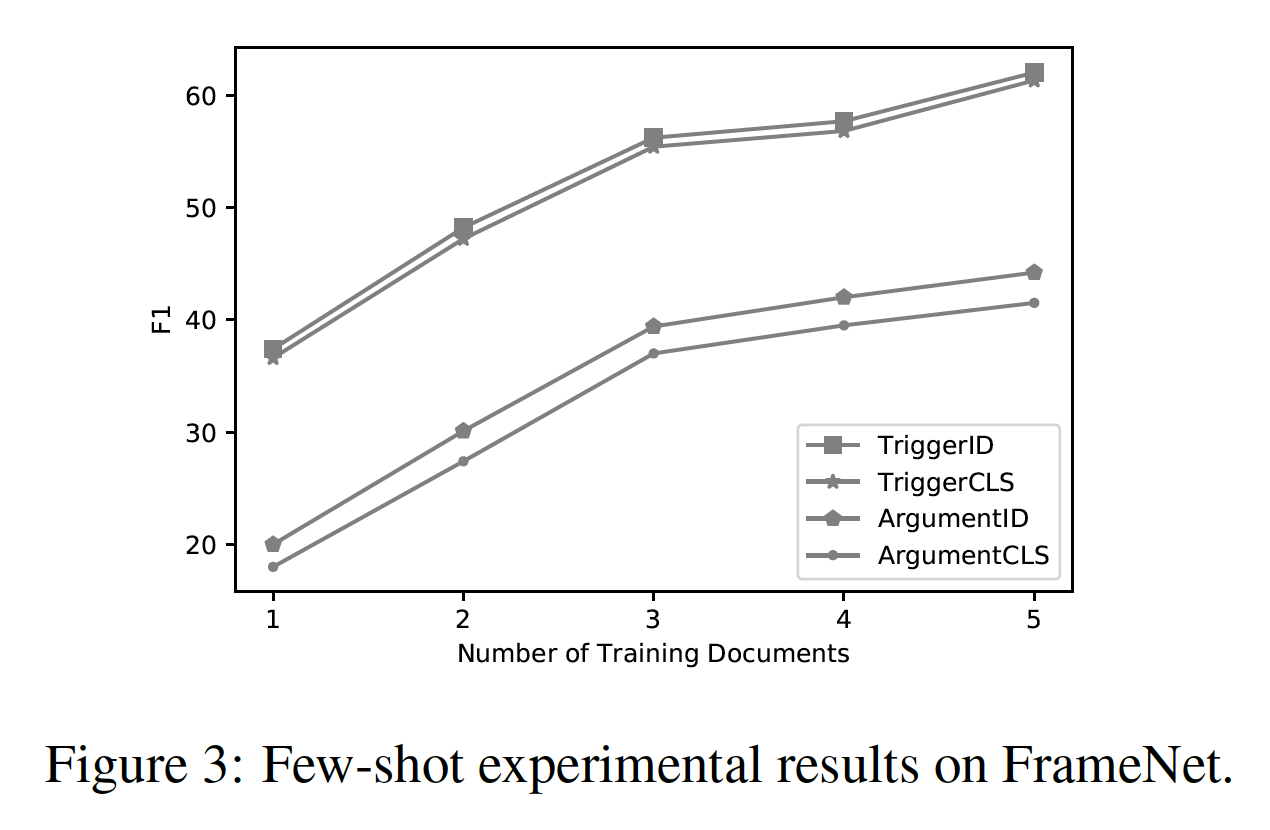
在FrameNet的Few-shot实验结果如下图:
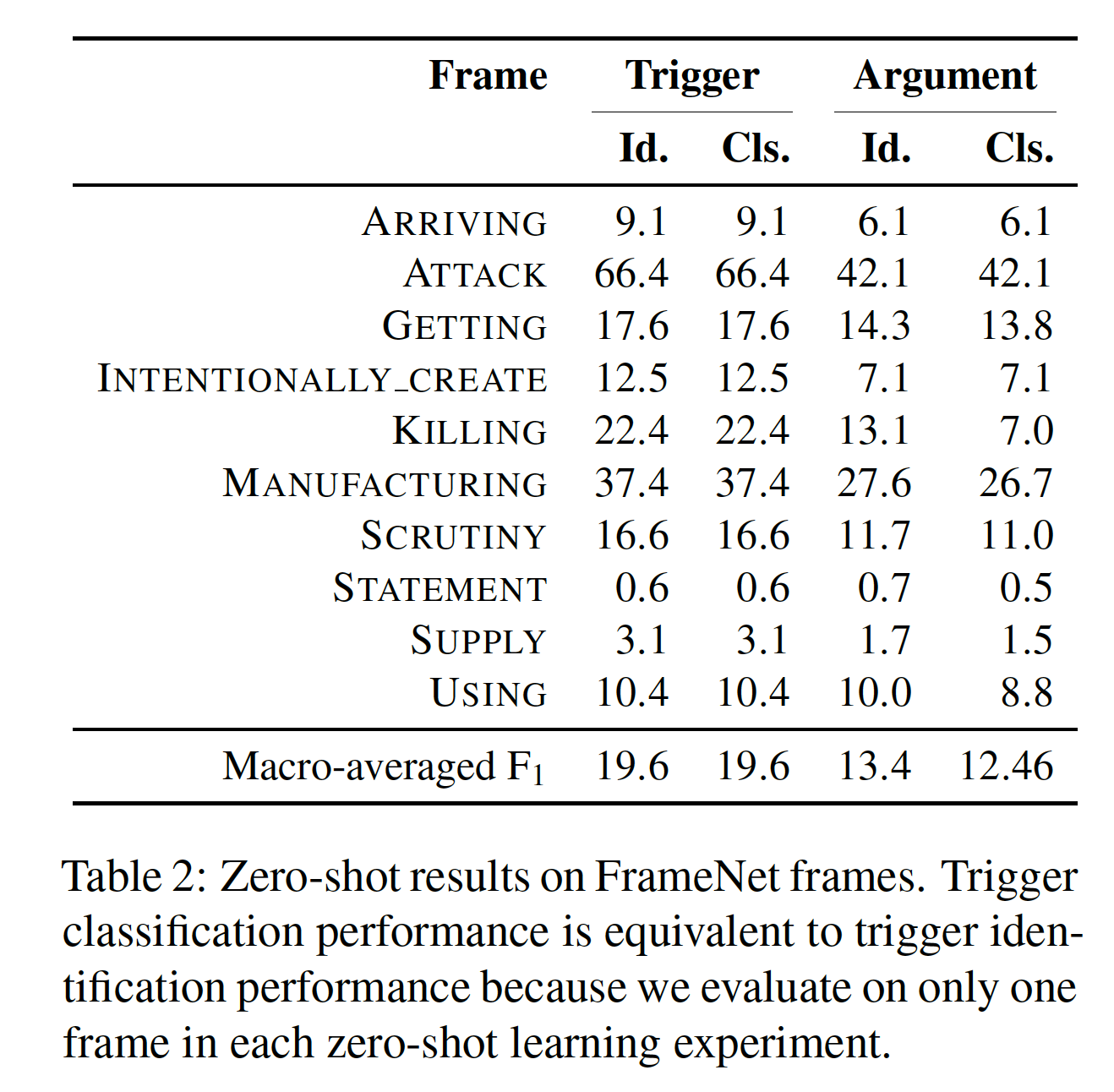
在FrameNet的Zero-shot实验结果如下图:

















 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











