








这篇文章写的是之前关于CUDA加速的另外一篇文章没详谈的部分,当时因为嫌麻烦懒得写,最近买了GTX960心情大好!决定把这个坑给填了。
当然由于本人才疏学浅,关于配置这些东西也是一知半解,所以参考了这篇文章,如果看到的朋友觉得本人讲的不好可以参考下那个。
OK,进入主题之前说一下,本篇文章与本文开头提到的那篇有比较强的关联性,如果看的不太明白的话建议先看那篇。下面正式开始。
首先建一个win32工程或者MFC工程,本文以MFC工程为例。
去上面文章提到的CUDA工程所在位置找到“main.h”和“kernel.cu”两个文件,然后添加进刚刚建的工程里面(也就是在工程名上右键->添加现有项)。如果不想这么搞也行,直接新建两个文件然后填入内容即可,内容如下:
main.h
#include<time.h>//时间相关头文件,可用其中函数计算图像处理速度
#include <iostream>
#define datasize 50000
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "main.h"
inline void checkCudaErrors(cudaError err)//错误处理函数
{
if (cudaSuccess != err)
{
fprintf(stderr, "CUDA Runtime API error: %s.\n", cudaGetErrorString(err));
return;
}
}
__global__ void add(int *a, int *b, int *c)//处理核函数
{
int tid = blockIdx.x*blockDim.x + threadIdx.x;
for (size_t k = 0; k < 50000; k++)
{
c[tid] = a[tid] + b[tid];
}
}
extern "C" int runtest(int *host_a, int *host_b, int *host_c)
{
int *dev_a, *dev_b, *dev_c;
checkCudaErrors(cudaMalloc((void**)&dev_a, sizeof(int)* datasize));//分配显卡内存
checkCudaErrors(cudaMalloc((void**)&dev_b, sizeof(int)* datasize));
checkCudaErrors(cudaMalloc((void**)&dev_c, sizeof(int)* datasize));
checkCudaErrors(cudaMemcpy(dev_a, host_a, sizeof(int)* datasize, cudaMemcpyHostToDevice));//将主机待处理数据内存块复制到显卡内存中
checkCudaErrors(cudaMemcpy(dev_b, host_b, sizeof(int)* datasize, cudaMemcpyHostToDevice));
add << <datasize / 100, 100 >> >(dev_a, dev_b, dev_c);//调用显卡处理数据
checkCudaErrors(cudaMemcpy(host_c, dev_c, sizeof(int)* datasize, cudaMemcpyDeviceToHost));//将显卡处理完数据拷回来
cudaFree(dev_a);//清理显卡内存
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}做完上面的工作其实已经完成一大半了,通常好一点的习惯是新建一个叫做“CUDA”或者“CUDAFILE”之类的名字的筛选器然后把.cu文件扔到里面去,这样看起来会比较好,不过也不是必须的。
下面来做本文最为关键的一步,因为CUDA代码是用CUDA本身提供的编译器来编译的,这里需要收到指定一下,过程如下:
工程名上右键->生成依赖性->生成自定义
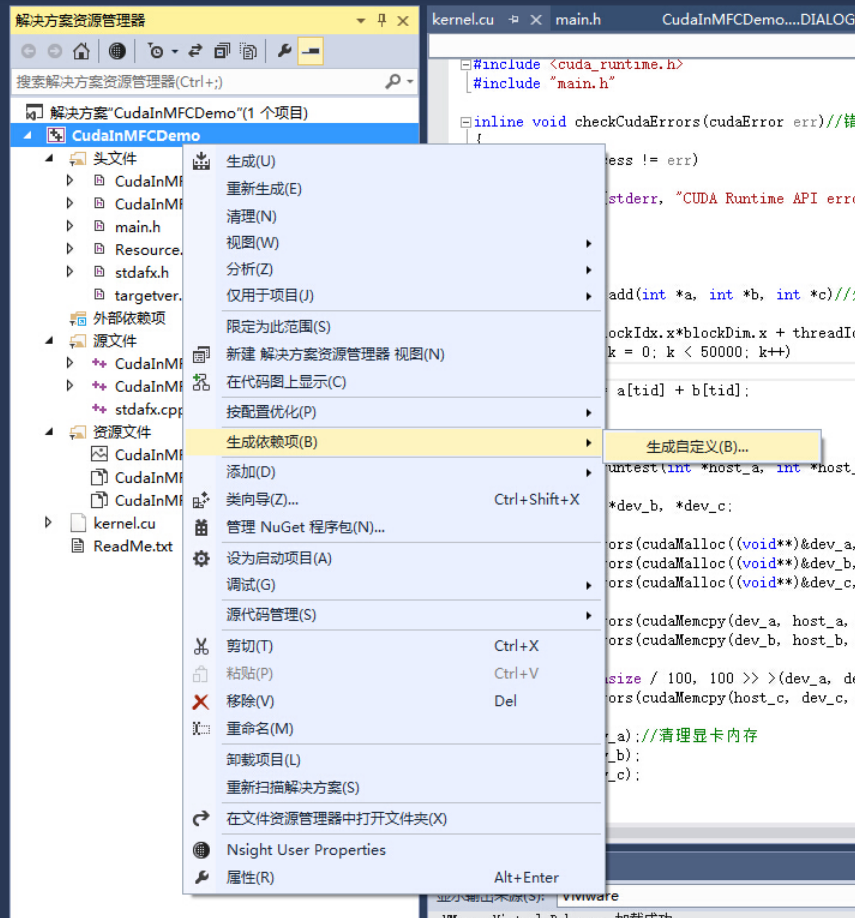
把CUDA 6.5(.targets,.props)勾上,如果你的版本不是6.5,就勾CUDA开头的就对了,好像现在已经有7.0了。勾完确定。
在kernel.cu名字上右键进入其属性页面
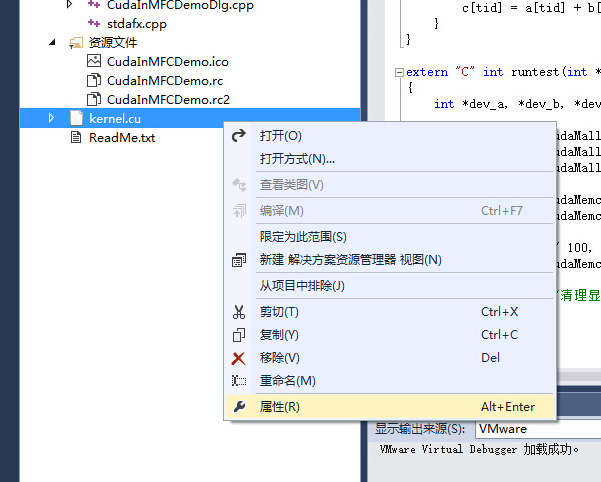
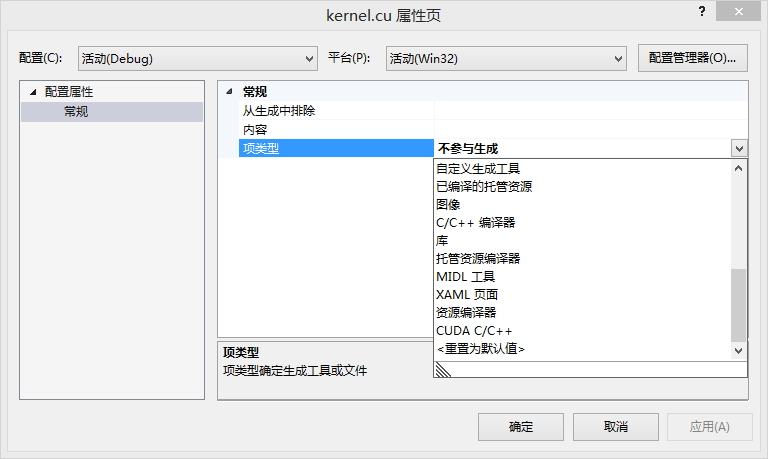
在属性页中可以看到项类型为“不参与生成”,用脚趾头就能想到这个东西要改掉,下拉,直接选上“CUDA C/C++”,应用,确定。
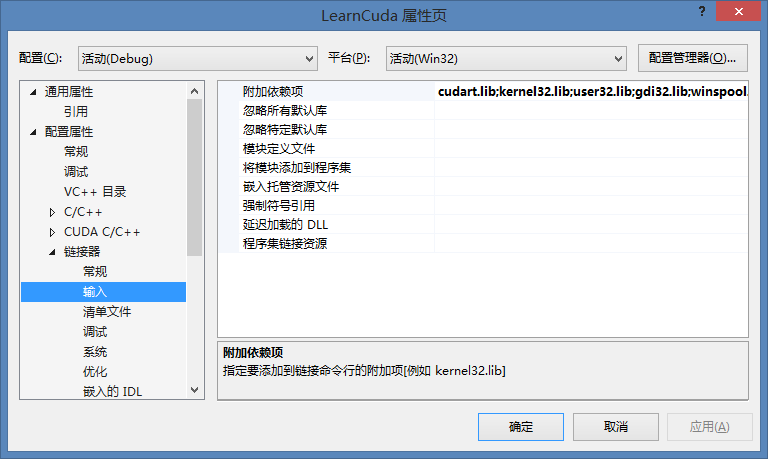
OK,到这步基本是做完了,但还要加上一些链接库,这个自己写会比较坑爹,好在上一篇文章提到的CUDA项目有自动添加这些,所以只要去那个工程复制粘贴就搞定了。具体是工程属性->配置属性->链接器->输入->附加依赖性,添加下面这些(这些是我自己的,没在别的电脑或者版本环境试过,最好是拷贝CUDA工程自己生成的):
cudart.lib
kernel32.lib
user32.lib
gdi32.lib
winspool.lib
comdlg32.lib
advapi32.lib
shell32.lib
ole32.lib
oleaut32.lib
uuid.lib
odbc32.lib
odbccp32.lib
最后,工程属性->配置属性->生产事件->后期生成事件->命令行,也把CUDA自动生成工程的信息考过去,这样就大功告成啦,本人的信息是
echo copy "$(CudaToolkitBinDir)\cudart*.dll" "$(OutDir)"
copy "$(CudaToolkitBinDir)\cudart*.dll" "$(OutDir)"
这个是拷贝动态链接库的,对发行来说很重要!
做完这些就大功搞成了。在后面的代码中把“main.h”头文件包含进来,然后声明下加速的函数即可,在这个例子中为:
extern "C" int runtest(int *host_a, int *host_b, int *host_c);//显卡处理函数
int a[datasize], b[datasize], c[datasize];
for (size_t i = 0; i < datasize; i++)
{
a[i] = i;
b[i] = i*i;
}
long now1 = clock();//存储图像处理开始时间
runtest(a, b, c);//调用显卡加速
printf("GPU运行时间为:%dms\n", int(((double)(clock() - now1)) / CLOCKS_PER_SEC * 1000));//输出GPU处理时间
long now2 = clock();//存储图像处理开始时间
for (size_t i = 0; i < datasize; i++)
{
for (size_t k = 0; k < 50000; k++)
{
c[i] = (a[i] + b[i]);
}
}
printf("CPU运行时间为:%dms\n", int(((double)(clock() - now2)) / CLOCKS_PER_SEC * 1000));//输出GPU处理时间















 2384
2384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









