







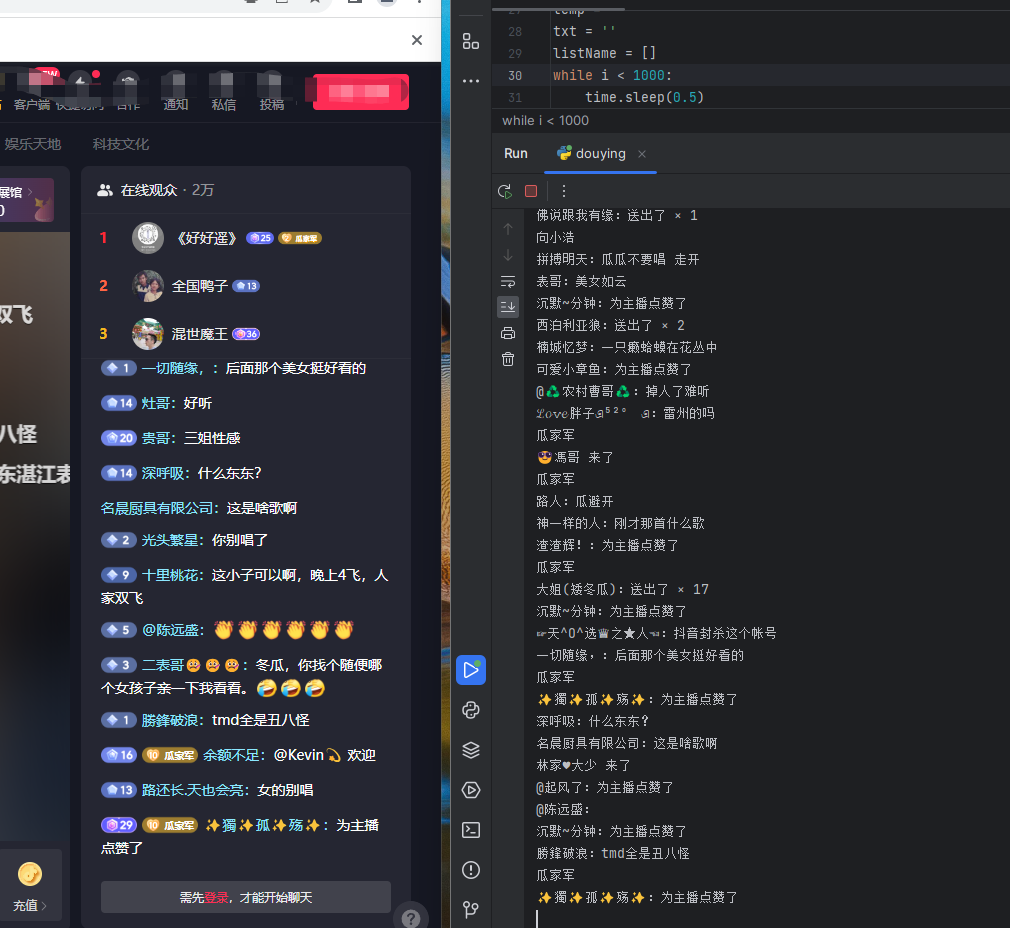
为了工作需要,为什么要把一些聊天记录保存下来,以方便以后分析:
- 规范合规:在一些行业中,如金融和医疗保健,法律要求保留特定类型的聊天记录以符合法规。
- 客户服务:保存聊天记录可以帮助企业了解客户的需求和问题,并为客户提供更好的支持。
- 培训和改进:保存聊天记录可以帮助企业分析员工的表现,识别常见问题和缺陷,并改进培训计划和流程。
- 争议解决:如果出现争议,保存的聊天记录可以作为证据,帮助企业解决纠纷。
- 数据分析:保存聊天记录可以帮助企业分析客户行为、偏好和趋势,以便更好地了解市场和改进业务策略。
保存聊天记录可以帮助企业提高效率、改善客户体验、遵守法规,并为业务决策提供有价值的信息。
1. Scrapy
Scrapy是Python爬虫领域最著名的框架之一。它是一个快速、高效、可扩展的爬虫框架。Scrapy自带了强大的Selector和异步处理机制,能够快速高效地爬取大量数据。
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)
2. BeautifulSoup
BeautifulSoup是Python最流行的HTML解析器之一。它可以解析HTML和XML文档,并提供了许多简单的方法来处理解析树。
from bs4 import BeautifulSoup
import requests
url = 'http://quotes.toscrape.com/'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
print(quote.find('span', class_='text').text)
print(quote.find('small', class_='author').text)
tags = quote.find('div', class_='tags').find_all('a', class_='tag')
for tag in tags:
print(tag.text)
3. PyQuery
PyQuery是另一个流行的Python爬虫框架,它是jQuery的Python实现。它可以解析HTML和XML文档,并提供了类似于jQuery的API来处理解析树。
from pyquery import PyQuery as pq
import requests
url = 'http://quotes.toscrape.com/'
response = requests.get(url)
doc = pq(response.text)
for quote in doc('div.quote').items():
print(quote('span.text').text())
print(quote('small.author').text())
tags = quote('div.tags a.tag')
for tag in tags:
print(pq(tag).text())
4. Requests-HTML
Requests-HTML是基于Requests和PyQuery的Python爬虫框架。它提供了类似于Requests的API,并使用PyQuery进行数据解析。
from requests_html import HTMLSession
url = 'http://quotes.toscrape.com/'
session = HTMLSession()
response = session.get(url)
for quote in response.html.find('div.quote'):
print(quote.find('span.text', first=True).text)
print(quote.find('small.author', first=True).text)
tags = quote.find('div.tags a.tag')
for tag in tags:
print(tag.text)
5. Selenium
Selenium是一个流行的自动化测试工具,也可以用于爬虫开发。它可以模拟用户行为,支持JavaScript渲染的网页。
from selenium import webdriver
url = 'http://quotes.toscrape.com/'
driver = webdriver.Chrome()
driver.get(url)
for quote in driver.find_elements_by_css_selector('div.quote'):
print(quote.find_element_by_css_selector('span.text').text)
print(quote.find_element_by_css_selector('small.author').text)
tags = quote.find_elements_by_css_selector('div.tags a.tag')
for tag in tags:
print(tag.text)
driver.quit()















 990
990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









