






Intro
在当今的人工智能领域,一张高性能GPU所配套的数学库软件发挥着至关重要的作用。实际上,许多复杂的AI算法和模型训练过程都依赖于这些底层数学库来执行高效的数据处理与计算任务。其中,矩阵乘法作为最基础也是最重要的一项功能,在各种深度学习框架中被频繁调用,对于提高整个系统的性能至关重要。
鉴于此,决定对A750的GPU上运行的矩阵乘法计算进行一系列详尽而深入的测试,将考察不同规模、不同类型矩阵之间的乘法运算效率。
这样的测试不仅有助于开发者更好地理解现有工具的优势与局限性,还能为未来开发更高效能的数学库提供宝贵的经验和数据支持。总之,针对A750 GPU上矩阵乘法计算能力的全面评估,将极大地促进相关技术的发展,并最终推动人工智能领域的进步。
目前,Intel提供了一个强大的矩阵计算库——MKL(Math Kernel Library),该库作为oneAPI Toolkit的一部分被广泛使用。MKL库是众多深度学习框架和应用的基础组件之一,它不仅支持在Intel自家的GPU上高效运行,而且也能充分利用CPU资源来加速数学运算任务。值得注意的是,尽管MKL是由Intel开发的,但它同样能够在非Intel平台上良好工作,比如可以在AMD处理器上使用,这使得MKL成为了一个跨平台、高性能的计算解决方案。无论是对于学术研究还是工业实践来说,MKL都因其出色的性能优化能力而备受青睐,尤其是在需要处理大规模数据集或执行复杂算法时。此外,通过oneAPI这一统一编程模型的支持,开发者能够更加方便地利用MKL提供的功能,在不同类型的硬件上实现一致性和可移植性,从而进一步提高了软件开发效率。
oneAPI的安装和配置
测试使用环境如下:
| 主板 | 华擎 B450 |
|---|---|
| CPU | Ryzen5500 |
| 内存 | DDR4 32G 3200MHZ |
| GPU | Intel Arc 750 |
所使用的操作系统是Ubuntu 24.04 LTS版本,这是一款长期支持(Long Term Support)的操作系统,意味着它将在未来几年内持续获得安全更新和技术支持。对于硬件方面的好消息是,A750显卡已经被纳入了Linux内核的主线支持中。这意味着用户无需手动下载和安装额外的驱动程序,即可让A750显卡在Ubuntu 24.04 LTS上正常工作。这样的集成不仅简化了设置过程,也确保了更好的兼容性和稳定性,为用户提供了一个更加流畅、可靠的计算环境。此外,随着系统的定期更新,A750显卡的支持也会得到进一步优化,从而让用户能够享受到最新的性能改进和功能增强。
根据官网的指引完成oneAPI的安装
https://www.intel.cn/content/www/cn/zh/developer/tools/oneapi/toolkits.html
加载oneAPI环境
使用MKL库进行矩阵乘法计算
目前,A750在MKL(Math Kernel Library,数学核心函数库)中的支持存在一定的限制。具体来说,A750芯片在使用MKL库时,暂时还不支持双精度浮点数的计算操作,仅能执行单精度浮点数的运算任务。因此,在本次测试中,我们将完全依赖于单精度模式来进行所有相关的计算工作。这一选择是基于现有硬件和软件兼容性的考量,旨在确保测试能够在当前条件下顺利进行。对于需要更高精度的应用场景,可能需要考虑其他支持双精度计算的硬件或寻找替代方案。
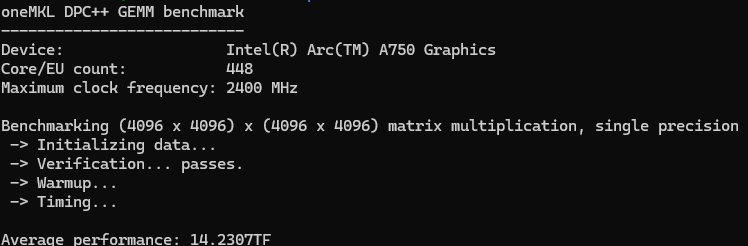
在TechPowerUp的数据库中,https://www.techpowerup.com/gpu-specs/arc-a750.c3929
A750显卡的FP32(单精度浮点运算)性能标称为17.20 TFLOPS。为了探究实际应用中该显卡能够发挥出多少比例的理论最大浮点计算能力,我们特别关注了Gemm(通用矩阵乘法)计算的表现。Gemm是一种常见的高性能计算任务,广泛应用于科学计算、人工智能等领域,因此其执行效率可以很好地反映硬件在处理密集型数值计算时的实际效能。
本次测试所使用的代码基于OneAPI提供的官方示例进行了适当调整。根据OneAPI官方给出的测试程序,在进行(4096x4096)规模的矩阵乘法运算时,A750显卡大约能够实现约14 TFLOPS的有效计算速度。这意味着,在这种特定的工作负载下,A750达到了其理论峰值性能的大约81%左右。
值得注意的是,虽然这个结果表明A750在大型矩阵操作上展现出了较强的能力,但要完全释放其潜力可能还需要进一步优化算法实现或调整其他相关参数。此外,不同类型的计算任务可能会导致不同的性能表现,因此上述测试结果仅作为参考,具体情况还需结合实际应用场景来分析。
为了更加客观和全面地评估数学库的性能,进行跨不同数据规模的测试是非常必要的。因此,我对oneAPI官方提供的测试代码进行了修改,以测试在不同数据规模下的GEMM(通用矩阵乘法)性能。通过这种方式能够更好地理解该库在处理小规模到大规模数据时的表现差异,从而为实际应用提供更有价值的参考信息。通过对不同数据规模下GEMM性能的详细考察,我们能够获得关于A750上MKL库性能更为深入且全面的认识。
测试结果
在A750GPU上分别针对128
256 384 512 640 768 896 1024 1152 1280 1408 1536 1664 1792 1920 2048 3072 4096 8192
数据规模的矩阵计算分别进行测试,测试结果如下图所示
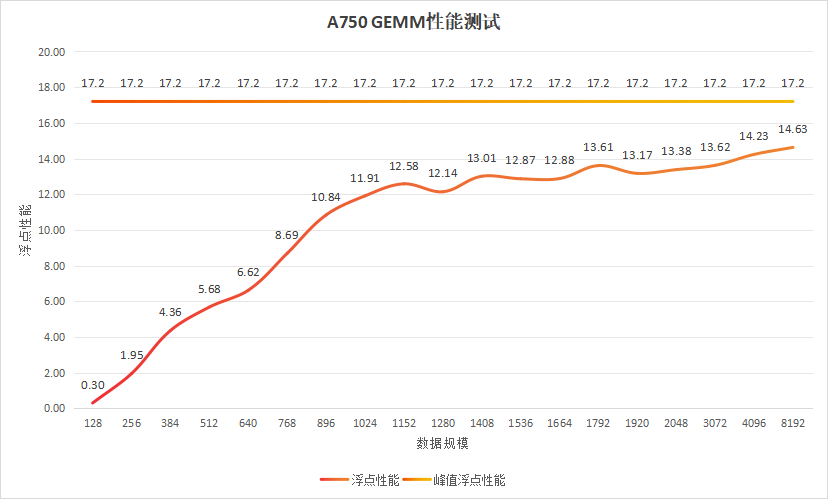
从观察到的数据趋势来看,随着处理数据量的逐步增加,A750在矩阵乘法(GEMM)上的性能表现呈现出明显的提升。这一现象表明,该硬件在面对更大规模的任务时,其潜在的计算能力得到了更充分的利用。随着工作负载的增长,A750的GEMM性能持续上升,直到达到一个相对稳定的水平大约为14Tflops。这个数值接近于设备理论最大性能17Tflops的大约80%,显示出A750能够在实际应用中实现相当高的效率与效能比。换句话说,在合理的配置和优化下,A750能够充分发挥其硬件优势,为需要大量并行计算的应用场景提供强有力的支持,从而满足大多数高性能计算需求。这样的性能释放对于加速机器学习模型训练、大数据分析以及其他依赖于高效数值计算的任务来说是非常有价值的。

















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









