






略记之以防遗忘-x战警-曾晓奇-09-06-25 凌晨
以前草草地读过CUDA Programming Guide,但后来又没有动手写程序,所以很快就遗忘了。及至最近,我觉得自己非学点东西不可,不能成天想着以后要找工作却不行动。不管怎么样,学好一门技术对自己总是好的,毕竟我也可以用它来加速我自己的程序不是?
在看nvidia给的例程的白皮书(是scan那个问题)的时候看到关于shared memory的bank conflict问题,于是转到在 2.0版本的Programming Guide中关于这一部分的介绍。
有一段起先一直没怎么看懂,在实验室想了许久没想通,到了寝室继续想,终于想通了。
第60页写道:
(现在假设每次对shared memory的访存操作是针对一个32-bit字。不考虑广播)
以线程的标号ID tid访问shared memory中的数组元素时,假设步长为s,那么kernel应该这样写:
__shared__ float shared[32];
float data = shared[BaseIndex + s * tid];
首先记住对于计算能力1.x的设备同一个时刻访问一个Multiprocessor上的shared memory的线程只有半个warp,即16个线程。现在假设两个线程,一个标号为tid, 另一个标号为tid+n,那么这两个线程访问shared memory时出现bank conflict 即他们访问了同一个bank的话,就是说m能整除s*n。 然后programming guide立马说这等同于说m/d能整除n(其中d为m,s的最大公约数)。就是这一句比较突然让我没有招架住。但是推导一下就知道了很简单:
m整除s*n所以可以设 s*n = k*m (1)
d是m,s的最大公约数,于是令s = p*d, m=q*d, (2)
由于d是m,s的最大公约数所以p,q是互质的两个正整数。
(1)<=> p*n=k*q
<=> k = n*p/q
由于k是正整数,p,q互质,所以n必为q的正整数倍,否则不可能使得k为正整数。
所以q整除n,由(2)知m/d整除n.
知道这个以后就好办了,接着programming guide中说只有当半个warp所含的线程数小于等于m/d时才不会有bank conflict。这是为什么呢,因为如果线程数大于m/d的话,那么基于上面的讨论半个warp中第m/d个线程就会与第0个线程访问同一个bank。当半个warp中线程数小于等于m/d时(这样的话半个warp中的线程标号从0到 m/d - 1)就不会出现这个问题。又由于计算能力1.x的设备半个warp含有16个线程,一个multiprossor的shared memory分成16个bank,那么就是说m=16, 由d是正整数,所以d必须只能为1(否则16>16/d,从而导致会出现bank conflict)。d=1意味着s为奇数(因为m=16只有一个因子2)。
现在来反地推一下,当s为奇数时d=1, 16=16/d, 半个warp上的标号为tidx+0到tidx+15, 这16个标号的线程之间不会访问同一个bank,因为假设两个线程标号差为t(t=1,...,15),较小的那个标号为t1,如果这两个线程访问同一个bank
那么 (BaseIndex + s * tid1)%16 = (BaseIndex+s*(tid1+t))%16
=> (s*t)%16=0
即必有16整除s*t,但s为奇数,t=1,...,15,这是不可能的。 所以s为奇数时不会存在bank conflict.
综上所述,对计算能力为1.x的设备来说,s为奇数<=>不存在bank conflict.
有了这个以后再去理解programming guide后面说的每次操作访问小于或大于32-bit单元怎样才能不造成bank conflict,什么样的结构体才不会造成bank conflict,就易懂了。
上面是没有考虑广播的情况。当多个线程访问同一个32-bit字的时候,可以利用一个广播把该字的内容一次性传给所有这些线程。访问shared memory的具体的过程是这样的(见CUDA 2.0版本的62页):
1.选出一个要访问的地址的内容作为广播内容
2.满足这样一些shared memory存取操作:
2.1 访问该广播内容地址的所有存取操作(用广播的形式将该内容传给那些操作)。
2.2 对于每个bank选一个访问它的存取操作(如果有存取操作访问该bank的话)。
3.如果不再有访问shared memory的存取操作则结束,否则回到1。
上面的过程是一个循环,每一次循环需要两个时钟周期。如果一次循环就可以结束,那么我们称这次(半个warp)访问shared memory的操作是conflict free的。每次第1步选择出来作为广播内容的字地址是不定的,2.2步每个bank选择的访问它的存取操作也是不一定的,因为可能有多个操作访问该bank。所以有如下图所示情况(图片来自2.0版本CUDA programming guide第66页Figure 5-8)
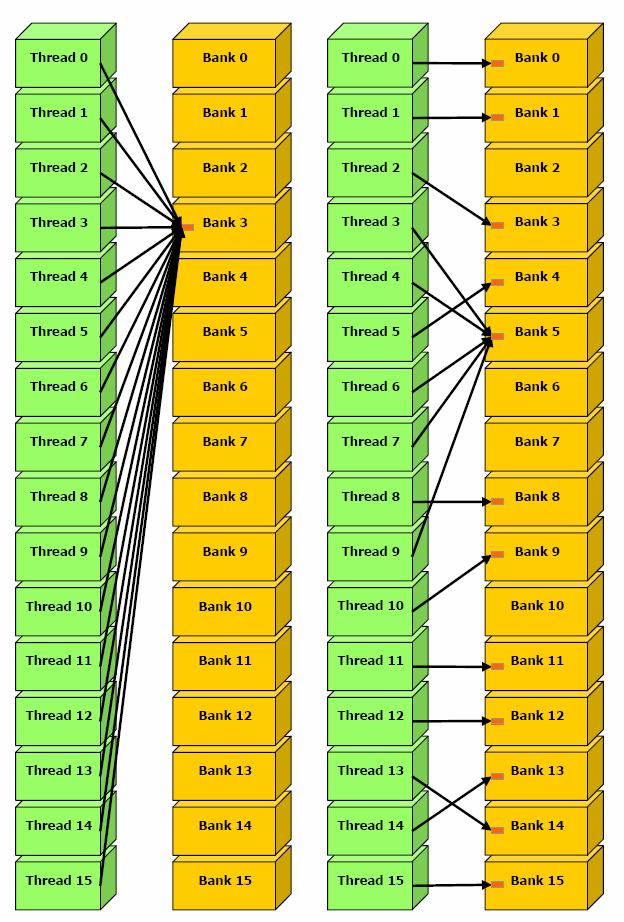
左图是所有16个线程都访问同一个32-bit字,一个广播解决,所以conflict free.
右图如果第1步选择的是Bank 5的那个被5个线程访问的字作为广播字的话,那么也是conflict free的。否则就存在bank conflict,这是个2路conflict,因为在2个循环能结束(第一个循环结束后只剩下访问Bank 5的那个字的4个线程,由于是访问同一个字,所以第二个循环用一个广播解决)。















 549
549

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









