







微信公众号:老牛同学
在上一篇中,我们探讨了 词嵌入(Word Embedding) ,它根据词嵌入矩阵将文本序列转换为数值向量,使得计算机能够理解和处理自然语言。现在,让我们进一步了解位置嵌入(Positional Embedding),这是让 Transformer 模型“知晓”词语顺序的关键。
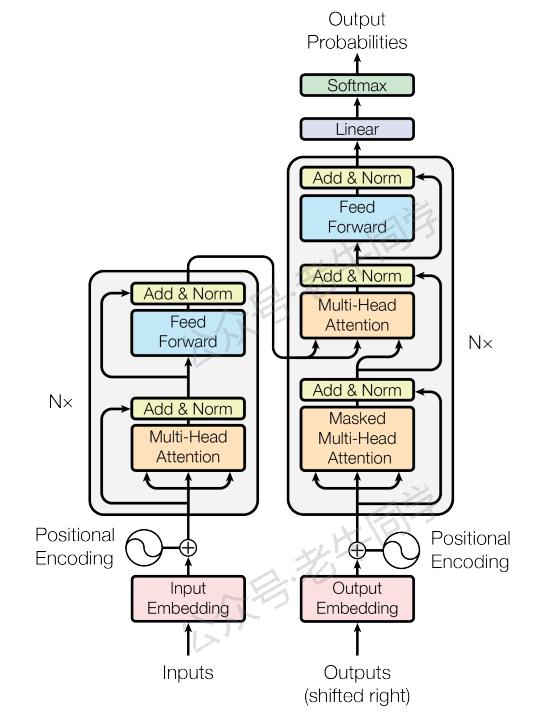
1. 位置嵌入的作用
想象一下,如果我们只用词嵌入,那么无论一个词出现在句子的开头还是结尾,它的表示都是相同的。然而,在自然语言中,词语的位置往往影响其意义。例如,“苹果”在“我吃了一个苹果”和“苹果公司发布了新产品”这两个句子中的含义截然不同。因此,我们需要一种机制来告诉模型这些信息,这就是位置嵌入的作用。
位置嵌入通过给每个词赋予一个与它在句子中位置相关的独特向量,使得模型不仅能够捕捉到词语的语义,还能理解它们之间的相对顺序,从而更好地建模句子结构和依赖关系。
2. 位置嵌入的原理
为了让模型能够学习到位置信息,最直接的方法是为每个位置分配一个固定的、预定义的向量。在原始的 Transformer 模型中,位置嵌入是由正弦和余弦函数组成的,这样设计的原因在于它具有周期性,可以帮助模型处理比训练时更长的序列,同时保持一定的泛化能力。
具体来说,对于模型维度 d 、位置 pos 和维度 i,位置嵌入 PE(pos, 2i)(偶数维)和 PE(pos, 2i+1) (奇数维)分别由以下公式计算:
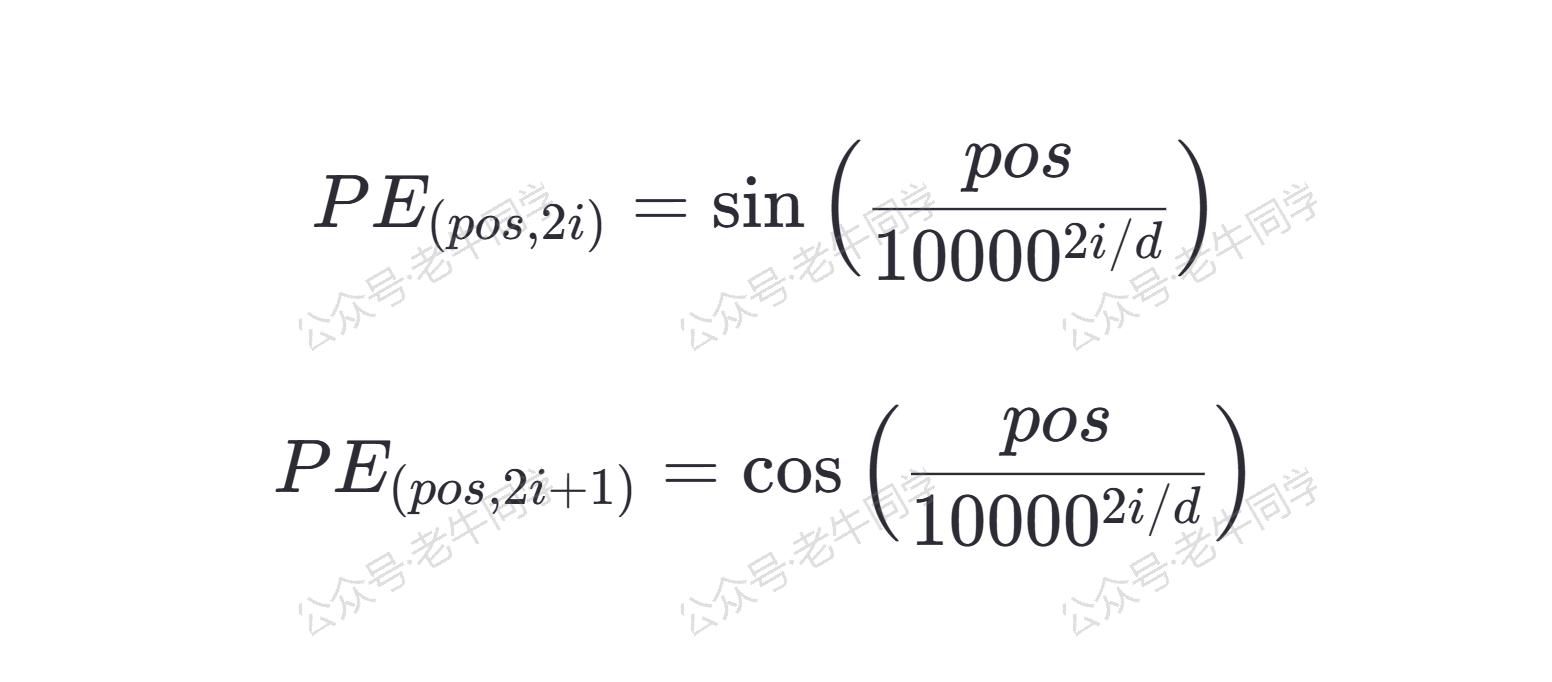
下面是位置嵌入计算的 Python 代码实现:
import torch
import torch.nn as nn
import math
class PositionalEn 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2088
2088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









