






本篇文章使用的是mmdetection社区中的RTMDET模型,实验数据集选取了一个自制的矿井检测数据,涉及6种类别,下面的展示仅用一种类别person。
#数据集准备
由于本身的数据标注结果是xml格式,在这里经过处理换成了是实验所需的CoCo2017格式,结构如下所示:
mmdetection/data(在根目录下新建一个data文件夹存放数据集):
XXX(数据集名字):
annotations:
instances_val2017.json
instances_train2017.json
train2017(训练集):存放训练图片
val2017(验证集):存放验证图片
注意:其中test用的实际上是val的数据所以不需要创建test文件夹。
#代码改动
1、首先运行以下命令安装python包
python setup.py install
运行结果如下图:
2、在configs目录下找到自己需要的配置文件,我用的是RTMDET的m模型
为了防止破坏原有的配置,建议复制一份再同一目录下面重名为my_XXX,在新的配置文件中进行修改相关参数。以我的配置文件为例:
_base_ = [
'../_base_/default_runtime.py', '../_base_/schedules/schedule_1x.py',
'../_base_/datasets/coco_detection.py', './rtmdet_tta.py'
]
model = dict(
type='RTMDet',
data_preprocessor=dict(
type='DetDataPreprocessor',
mean=[103.53, 116.28, 123.675],
std=[57.375, 57.12, 58.395],
bgr_to_rgb=False,
batch_augments=None),
backbone=dict(
看到上面有几个相关文件,我们需要改动的是../_base_/datasets/coco_detection.py文件,更改其中的数据集路径。如下(我的数据集名是mk):
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/mk/'
# Example to use different file client
# Method 1: simply set the data root and let the file I/O module
# automatically infer from prefix (not support LMDB and Memcache yet)
# data_root = 's3://openmmlab/datasets/detection/coco/'
3、修改配置文件中的内容
num_classes:类别数量
bbox_head=dict(
type='RTMDetSepBNHead',
num_classes=1,
in_channels=256,
stacked_convs=2,
feat_channels=256,
anchor_generator=dict(
type='MlvlPointGenerator', offset=0, strides=[8, 16, 32]),
bbox_coder=dict(type='DistancePointBBoxCoder'),
loss_cls=dict(
type='QualityFocalLoss',
use_sigmoid=True,
beta=2.0,
loss_weight=1.0),
loss_bbox=dict(type='GIoULoss', loss_weight=2.0),
with_objectness=False,
exp_on_reg=True,
share_conv=True,
pred_kernel_size=1,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU', inplace=True)),
max_epochs:训练轮数
max_epochs = 200
stage2_num_epochs = 20
base_lr = 0.004
interval = 10
batch_size:看设备决定,显存小就降低
train_dataloader = dict(
batch_size=16,
num_workers=4,
batch_sampler=None,
pin_memory=True,
dataset=dict(pipeline=train_pipeline))
val_dataloader = dict(
batch_size=5, num_workers=4, dataset=dict(pipeline=test_pipeline))
test_dataloader = val_dataloader
4、修改tools/train.py文件:
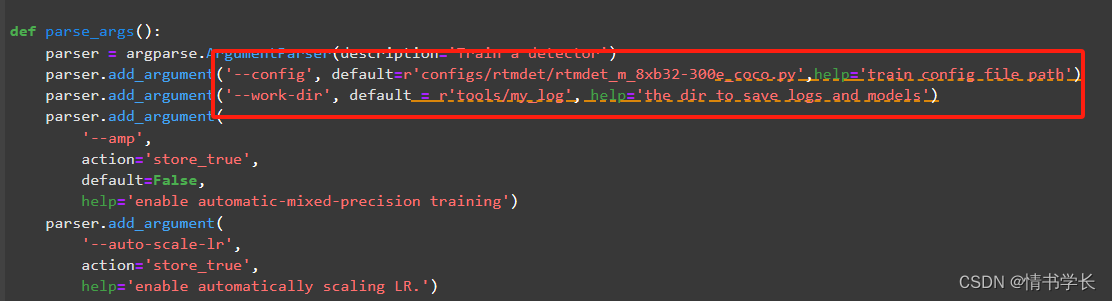
其中一个是配置文件路径,也就是上面自己命名那个配置文件的路径。
另一个是存放训练过程中log日志和最佳权重的部分,可以自定义路径。
#开始训练
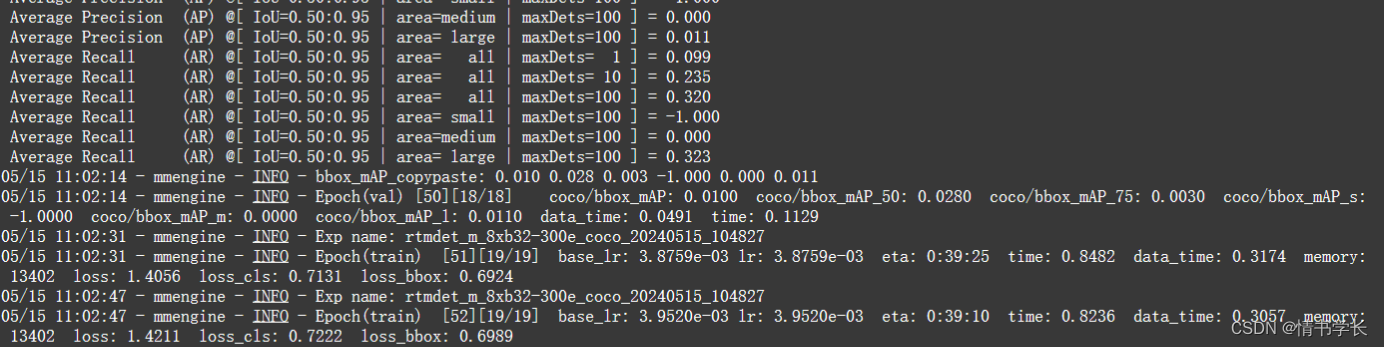
输入命令python tools/train.py运行训练文件,结果如下:
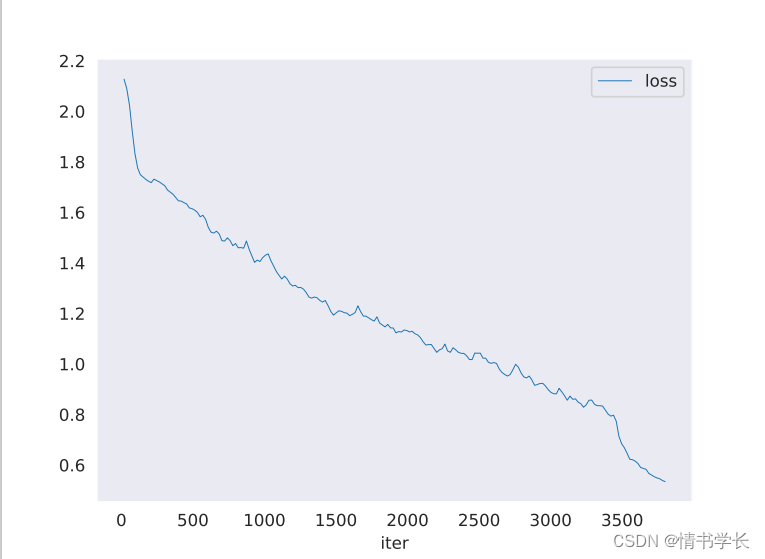
#查看训练loss曲线图
运行以下命令:
python tools/analyze_logs.py plot_curve work_dirs/faster_rcnn_r50_fpn_1x/20200306_175509.log.json --keys loss_cls --legend loss_cls --out loss.pdf
其中,
tools/analyze_logs.py:根据日志文件显示图像的文件路径;
work_dirs/faster_rcnn_r50_fpn_1x/20200306_175509.log.json:步骤4中自定义的日志文件夹中生成的json格式的日志文件;
loss_cls:要显示的纵坐标数据;
loss.pdf:生成出来图像的存放位置。
结果如图:

















 142
142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









