



主成分分析(PCA)
1. PCA算法简介
PCA(Principal Component Analysis,主成分分析)是一种常用的无监督学习算法,主要用于降维和特征提取。它的核心思想是将高维数据投影到低维空间,同时尽可能保留数据中的主要信息(即方差最大的方向)。
主要思想:找到数据中方差最大的方向(主成分),将数据投影到由这些主成分构成的低维空间中。
目的:降低数据维度,减少冗余信息,提高计算效率,同时保留数据的主要特征。
2.PCA 算法流程
2.1数据标准化:
对数据进行标准化处理,使每个特征的均值为 0,方差为 1。这一步可以消除不同特征之间的量纲差异。
x标准化=x−μσ
x_{\text{标准化}} = \frac{x - \mu}{\sigma}
x标准化=σx−μ
其中:
- xxx 是原始数据点,
- μ\muμ 是数据的均值,
- σ\sigmaσ 是数据的标准差。
2.2计算协方差矩阵:
协方差矩阵用于衡量不同特征之间的相关性。计算公式为:
Cov(X)=1n−1XTX
\text{Cov}(X) = \frac{1}{n-1} X^T X
Cov(X)=n−11XTX
其中,XXX 是标准化后的数据矩阵,每一行表示一个样本,每一列表示一个特征。
2.3计算协方差矩阵的特征值和特征向量:
对协方差矩阵 Σ\SigmaΣ 进行特征值分解,得到特征值 λ\lambdaλ 和对应的特征向量 vvv。特征值和特征向量满足以下方程:
Σ⋅v=λ⋅v \Sigma \cdot v = \lambda \cdot v Σ⋅v=λ⋅v
这一步的目的是找到数据中的主成分,即在哪些方向上数据变化最为显著。
2.4选择主成分:
根据特征值的大小排序,选择前 k 个最大的特征值对应的特征向量,构成降维后的目标子空间。
构成投影矩阵 W:
W=[v1,v2,…,vk] W = [v_1, v_2, \dots, v_k] W=[v1,v2,…,vk]
其中,v1,v2,…,vkv_1, v_2, \dots, v_kv1,v2,…,vk 是对应于前 k 个最大特征值的特征向量。
2.5数据投影:
将原始数据投影到由选中的特征向量构成的低维空间中,得到降维后的数据。
Z=XW
Z = X W
Z=XW
其中,XXX 是原始数据矩阵,WWW 是由选中的特征向量组成的投影矩阵,ZZZ 是降维后的数据矩阵。
3.PCA 算法功能及优缺点
3.1PCA功能
降维:PCA 将高维数据投影到低维空间,减少了数据的维度,降低了存储和计算成本。
特征提取:提取数据中的主要特征(主成分),去除冗余信息和噪声,增强数据的主要结构信息。
去相关性:PCA 将原始特征转换为相互正交(不相关)的主成分,有助于消除多重共线性问题。
数据可视化:将高维数据降到二维或三维,便于在散点图等可视化工具中展示数据的分布结构。
3.2PCA优缺点
解释性较差:主成分是原始特征的线性组合,难以解释其实际意义。
对数据分布的假设:假设数据线性可分,对方差较大的方向敏感,不适用于非线性数据。
对异常值敏感:异常值可能影响主成分的方向和方差,需要预处理数据。
计算复杂度:高维数据的协方差矩阵计算和特征值分解计算量较大。
信息损失:降维过程中可能丢失部分信息,需选择合适的主成分数量。
PCA实例代码分析(人脸识别)
1.加载人脸图像数据
功能:从指定路径加载 ORL_Faces 数据集中的灰度人脸图像。
实现细节:
遍历 s1 到 s40 的文件夹,每个文件夹包含 10 张图像。
使用 cv2.imread 以灰度模式读取图像。
如果图像读取成功,则将其添加到 images 列表中,并将对应的类别编号添加到 labels 列表中。
如果图像无法读取,打印警告信息。
如果没有读取到任何图像,抛出异常。
返回图像数组和标签数组。
def load_image_data(path='ORL_Faces'):
"""
功能:读取 ORL_Faces 数据集中的所有灰度人脸图像
参数:
path:数据集路径,默认为 'ORL_Faces'
返回:
images:形状为 (400, 高, 宽) 的图像数组
labels:形状为 (400,) 的标签数组(1~40)
"""
images = []
labels = []
for category in range(1, 41): # 类别 s1 ~ s40
for sample in range(1, 11): # 每类10张图
img_path = os.path.join(path, f"s{category}", f"{sample}.pgm")
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
if img is not None:
images.append(img)
labels.append(category)
else:
print(f"⚠️ 无法读取图像:{img_path}")
if not images:
raise RuntimeError("❌ 未读取到任何图像,请检查路径或格式。")
print(f"✅ 成功读取 {len(images)} 张图像。")
return np.array(images), np.array(labels)
2.绘制图像(支持原始图或特征脸)
功能:绘制图像矩阵,用于展示图像或特征脸。
实现细节:
使用 plt.figure 创建一个图像窗口,大小根据行数和列数动态调整。
使用 plt.subplots_adjust 调整子图的布局。
遍历图像数组,将每张图像绘制为一个子图。
使用 plt.imshow 显示灰度图像。
设置每个子图的标题,并隐藏坐标轴。
def plot_image_gallery(images, titles, image_height, image_width, n_row=3, n_col=4):
"""
功能:绘制图像矩阵,用于展示“特征脸”或其他图像
参数:
images:图像数组
titles:每个图像的标题数组
image_height:图像高度
image_width:图像宽度
n_row:显示行数,默认为 3
n_col:显示列数,默认为 4
"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(min(n_row * n_col, len(images))):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((image_height, image_width)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
3.主程序入口
功能:主程序入口,完成人脸图像的加载、预处理、PCA 降维、KNN 分类以及结果可视化。
实现细节:
读取数据:
调用 load_image_data 函数加载 ORL_Faces 数据集。
将图像数据展平为二维特征矩阵,形状为 (400, 高 × 宽)。
划分训练集和测试集:
使用 train_test_split 将数据集划分为训练集和测试集,比例为 75% 训练集、25% 测试集。
标准化处理:
使用 StandardScaler 对特征矩阵进行标准化处理,使其均值为 0,标准差为 1。
PCA 降维:
使用 PCA 对标准化后的特征矩阵进行降维,保留 150 个主成分。
对训练集和测试集分别进行降维。
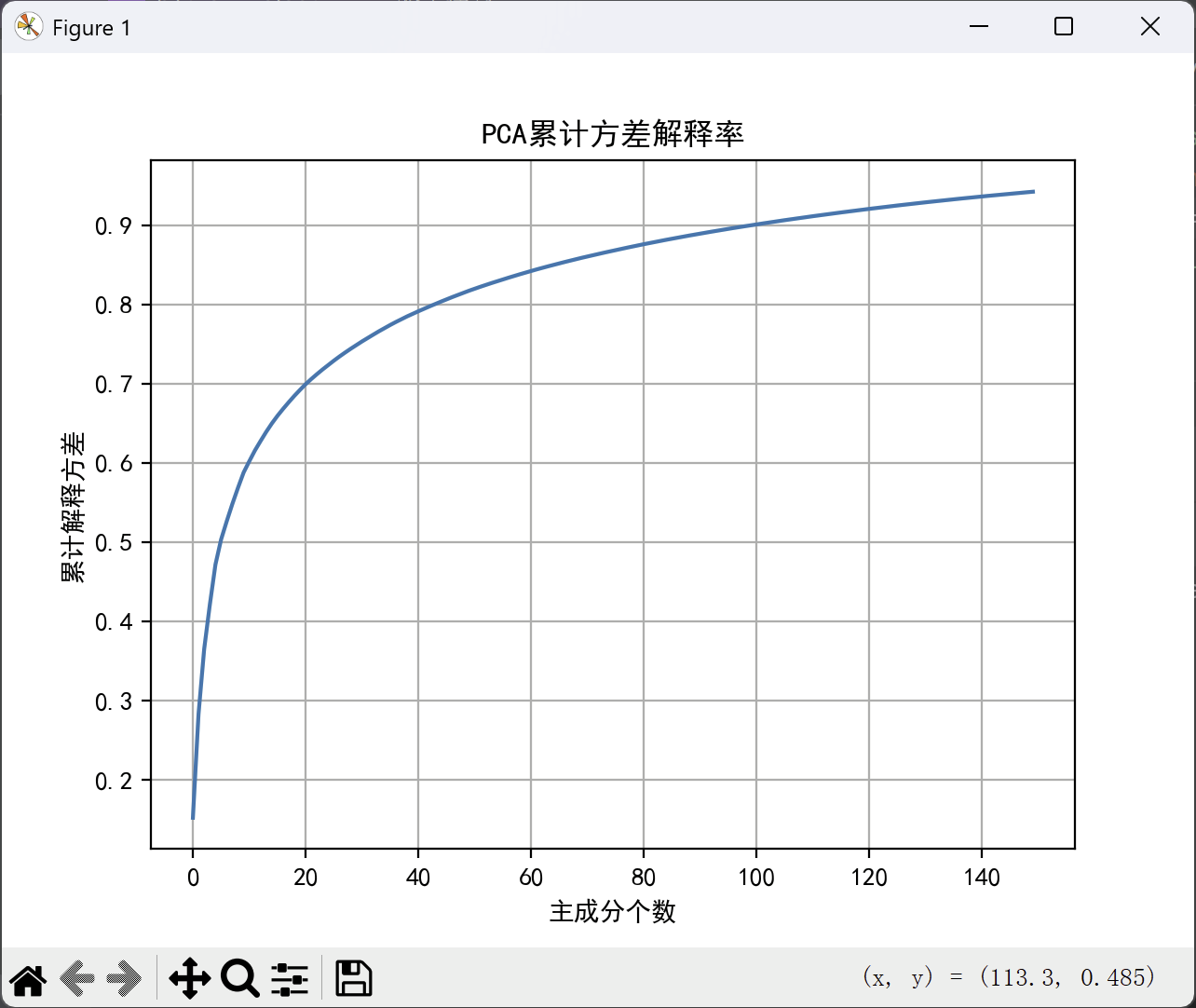
累计解释方差图:
绘制 PCA 的累计解释方差图,用于评估降维效果。
KNN 分类:
使用 KNN 分类器对降维后的数据进行分类。
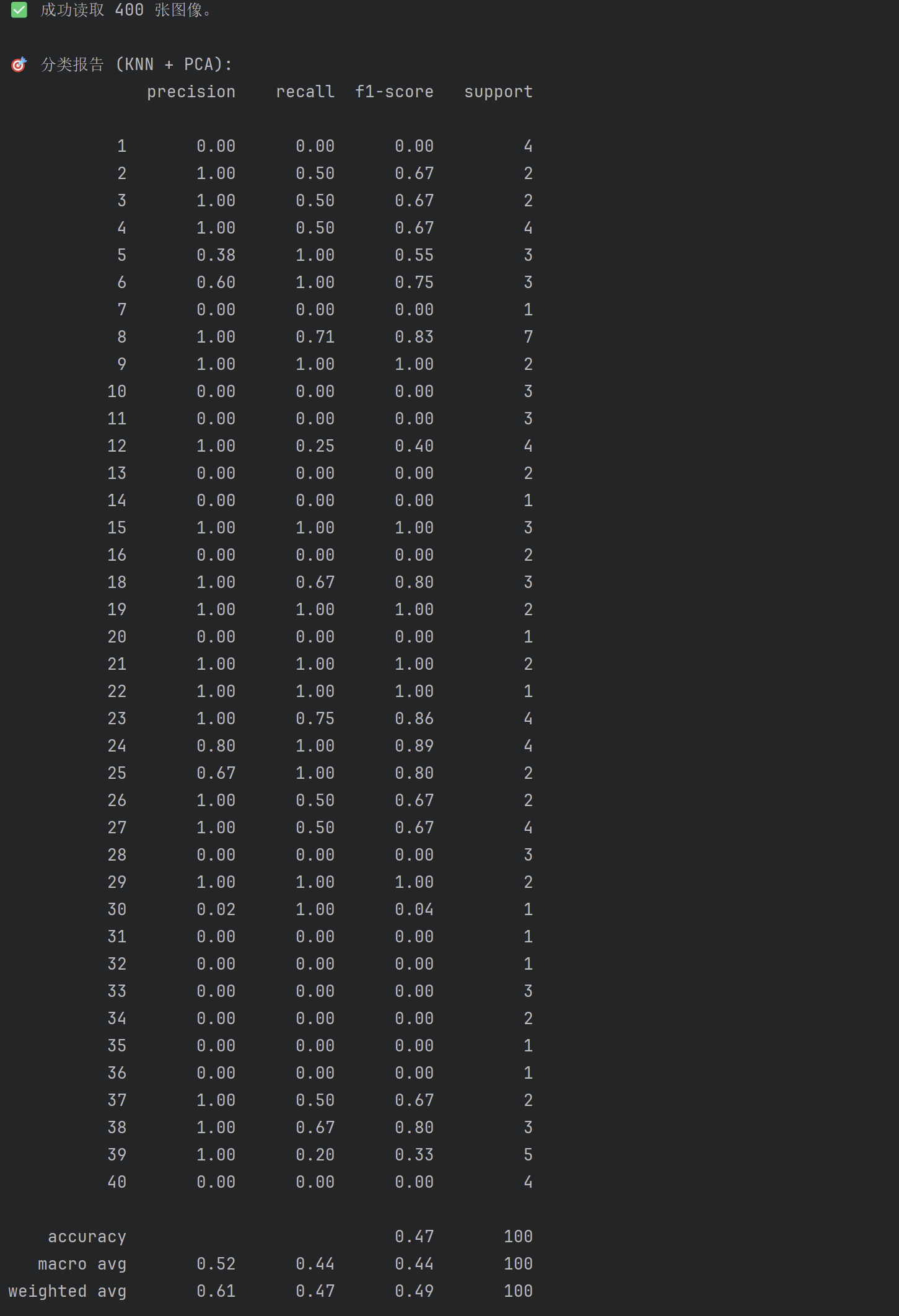
分类结果评估:
使用 classification_report 输出分类报告,包括准确率、召回率、F1 分数等指标。
可视化特征脸(Eigenfaces):
提取 PCA 的主成分,将其重塑为图像形状。
使用 plot_image_gallery 函数绘制特征脸图像。
def main():
# ① 读取数据
face_images, face_labels = load_image_data(path='ORL_Faces') # <-- 确保路径正确
num_samples, img_height, img_width = face_images.shape
feature_matrix = face_images.reshape((num_samples, -1)) # 图像展平成向量
# ② 划分训练集和测试集,默认 75% 训练、25% 测试
X_train, X_test, y_train, y_test = train_test_split(
feature_matrix, face_labels, test_size=0.25, random_state=42
)
# ③ 标准化处理
data_scaler = StandardScaler()
X_train_scaled = data_scaler.fit_transform(X_train)
X_test_scaled = data_scaler.transform(X_test)
# ④ PCA 降维
num_components = min(150, X_train_scaled.shape[0]) # 不超过样本数
pca_model = PCA(n_components=num_components, whiten=True, random_state=42)
X_train_pca = pca_model.fit_transform(X_train_scaled)
X_test_pca = pca_model.transform(X_test_scaled)
# ⑤ 累计解释方差图
plt.figure()
plt.plot(np.cumsum(pca_model.explained_variance_ratio_))
plt.xlabel("主成分个数")
plt.ylabel("累计解释方差")
plt.title("PCA累计方差解释率")
plt.grid()
plt.show()
# ⑥ KNN 分类
knn_classifier = KNeighborsClassifier(n_neighbors=5)
knn_classifier.fit(X_train_pca, y_train)
y_pred = knn_classifier.predict(X_test_pca)
# ⑦ 分类结果评估
print("\n🎯 分类报告 (KNN + PCA):")
print(classification_report(y_test, y_pred))
# ⑧ 可视化特征脸(Eigenfaces)
eigen_faces = pca_model.components_.reshape((num_components, img_height, img_width))
eigen_face_titles = [f"特征脸 {i + 1}" for i in range(eigen_faces.shape[0])]
plot_image_gallery(eigen_faces, eigen_face_titles, img_height, img_width, n_row=3, n_col=4)
plt.show()
4. 执行主函数
if __name__ == "__main__":
main()
5.完整代码
import cv2
import os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler
# === 字体设置(支持中文显示)===
font_path = "C:/Windows/Fonts/simhei.ttf"
font_prop = FontProperties(fname=font_path)
plt.rcParams['font.family'] = font_prop.get_name()
plt.rcParams['axes.unicode_minus'] = False
# 加载人脸图像数据
def load_image_data(path='ORL_Faces'):
"""
功能:读取 ORL_Faces 数据集中的所有灰度人脸图像
参数:
path:数据集路径,默认为 'ORL_Faces'
返回:
images:形状为 (400, 高, 宽) 的图像数组
labels:形状为 (400,) 的标签数组(1~40)
"""
images = []
labels = []
for category in range(1, 41): # 类别 s1 ~ s40
for sample in range(1, 11): # 每类10张图
img_path = os.path.join(path, f"s{category}", f"{sample}.pgm")
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
if img is not None:
images.append(img)
labels.append(category)
else:
print(f"⚠️ 无法读取图像:{img_path}")
if not images:
raise RuntimeError("❌ 未读取到任何图像,请检查路径或格式。")
print(f"✅ 成功读取 {len(images)} 张图像。")
return np.array(images), np.array(labels)
# 绘制图像(支持原始图或特征脸)
def plot_image_gallery(images, titles, image_height, image_width, n_row=3, n_col=4):
"""
功能:绘制图像矩阵,用于展示“特征脸”或其他图像
参数:
images:图像数组
titles:每个图像的标题数组
image_height:图像高度
image_width:图像宽度
n_row:显示行数,默认为 3
n_col:显示列数,默认为 4
"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(min(n_row * n_col, len(images))):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((image_height, image_width)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
# 主程序入口
def main():
# ① 读取数据
face_images, face_labels = load_image_data(path='ORL_Faces') # <-- 确保路径正确
num_samples, img_height, img_width = face_images.shape
feature_matrix = face_images.reshape((num_samples, -1)) # 图像展平成向量
# ② 划分训练集和测试集,默认 75% 训练、25% 测试
X_train, X_test, y_train, y_test = train_test_split(
feature_matrix, face_labels, test_size=0.25, random_state=42
)
# ③ 标准化处理
data_scaler = StandardScaler()
X_train_scaled = data_scaler.fit_transform(X_train)
X_test_scaled = data_scaler.transform(X_test)
# ④ PCA 降维
num_components = min(150, X_train_scaled.shape[0]) # 不超过样本数
pca_model = PCA(n_components=num_components, whiten=True, random_state=42)
X_train_pca = pca_model.fit_transform(X_train_scaled)
X_test_pca = pca_model.transform(X_test_scaled)
# ⑤ 累计解释方差图
plt.figure()
plt.plot(np.cumsum(pca_model.explained_variance_ratio_))
plt.xlabel("主成分个数")
plt.ylabel("累计解释方差")
plt.title("PCA累计方差解释率")
plt.grid()
plt.show()
# ⑥ KNN 分类
knn_classifier = KNeighborsClassifier(n_neighbors=5)
knn_classifier.fit(X_train_pca, y_train)
y_pred = knn_classifier.predict(X_test_pca)
# ⑦ 分类结果评估
print("\n🎯 分类报告 (KNN + PCA):")
print(classification_report(y_test, y_pred))
# ⑧ 可视化特征脸(Eigenfaces)
eigen_faces = pca_model.components_.reshape((num_components, img_height, img_width))
eigen_face_titles = [f"特征脸 {i + 1}" for i in range(eigen_faces.shape[0])]
plot_image_gallery(eigen_faces, eigen_face_titles, img_height, img_width, n_row=3, n_col=4)
plt.show()
# 执行主函数
if __name__ == "__main__":
main()
6.实验结果

总结
主成分分析(PCA)是一种强大的降维工具,通过线性变换将高维数据映射到低维空间,同时保留数据中的主要信息。在实际应用中,PCA不仅可以用于数据压缩和特征提取,还可以帮助我们更好地理解数据结构。希望通过本文的介绍和案例分析,能够让你对PCA有更深入的理解。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









