







Abstract
单目三维目标检测因其易于应用而成为自动驾驶领域的主流检测方法。一个突出的优点是在推理过程中不需要激光雷达点云。然而,目前大多数方法仍然依赖于3D点云数据来标记训练阶段使用的地面真相。这种训练和推理的不一致性使得大规模反馈数据难以利用,增加了数据收集的费用。为了弥补这一缺陷,我们提出了一种新的弱监督单眼三维目标检测方法,该方法可以只使用图像上标记的二维标签来训练模型。具体来说,我们在这个任务中探索了三种类型的一致性,即投影一致性、多视图一致性和方向一致性,并基于这些一致性设计了一个弱监督架构。此外,我们提出了一种新的二维方向标注方法,以指导模型进行准确的旋转方向预测。实验表明,弱监督方法与一些完全监督方法的性能相当。当用作预训练方法时,我们的模型仅使用1/3的3D标签就可以显著优于相应的完全监督基线。
网络架构图
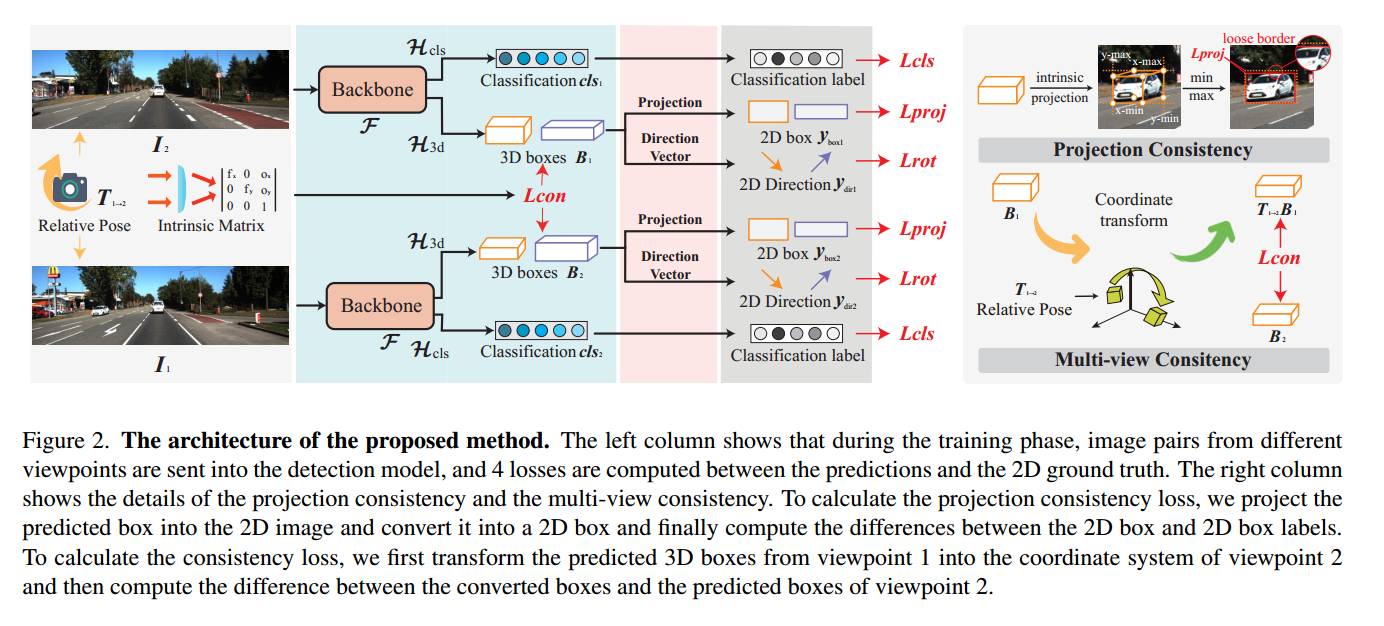
图2。所提出方法的体系结构。左列表示在训练阶段,将不同视点的图像对送入检测模型,在预测结果与二维地面真值之间计算4个损失。右列显示了投影一致性和多视图一致性的详细信息。为了计算投影一致性损失,我们将预测框投影到二维图像中,并将其转换为二维框,最后计算二维框与二维框标签之间的差异。
为了计算一致性损失,我们首先将视点1的预测3D盒转换到视点2的坐标系中,然后计算转换后的盒与视点2的预测盒的差值。
methods
本文提出的方法是一种弱监督的单目 3D 物体检测方法,仅使用 2D 标签进行训练。以下是该方法的关键组成部分:
- 架构:该方法设计为通用的,可以与现有的单目 3D 检测模型集成。它采用骨干模型(例如 DD3D)从不同视点拍摄的图像对中提取特征。
- 一致性类型:
- 投影一致性:这涉及将预测的 3D 边界框投影到 2D 图像空间中,并确保它们与相应的 2D 地面真实框对齐。投影损失被定义为最小化这些投影框与 2D 标签之间的差异。
- 多视图一致性:此方面确保从不同视点预测的同一物体的边界框在位置、大小和旋转方面一致。该方法最小化这些预测之间的差异,以提高 3D 空间的准确性。
- 方向一致性:引入一种新的二维方向标记方法来指导模型预测物体的正确旋转方向。
- 训练过程:使用来自不同视点的图像对来训练模型,这些图像对可以从多个摄像机或视频序列的相邻帧中获得。训练涉及根据投影和方向一致性计算损失。
- 数据增强:该方法采用数据增强技术,例如随机水平翻转、调整大小和颜色抖动,以增强模型的鲁棒性。
- 性能:实验表明,所提出的弱监督方法实现了与全监督方法相当的性能,甚至在用作具有明显较少的 3D 标签的预训练方法时优于其中一些方法。
总体而言,该方法利用弱监督和各种一致性约束来提高单目图像 3D 预测的准确性,从而有效地弥合了 2D 和 3D 物体检测之间的差距 [T1]、[T3]、[T6]。
results
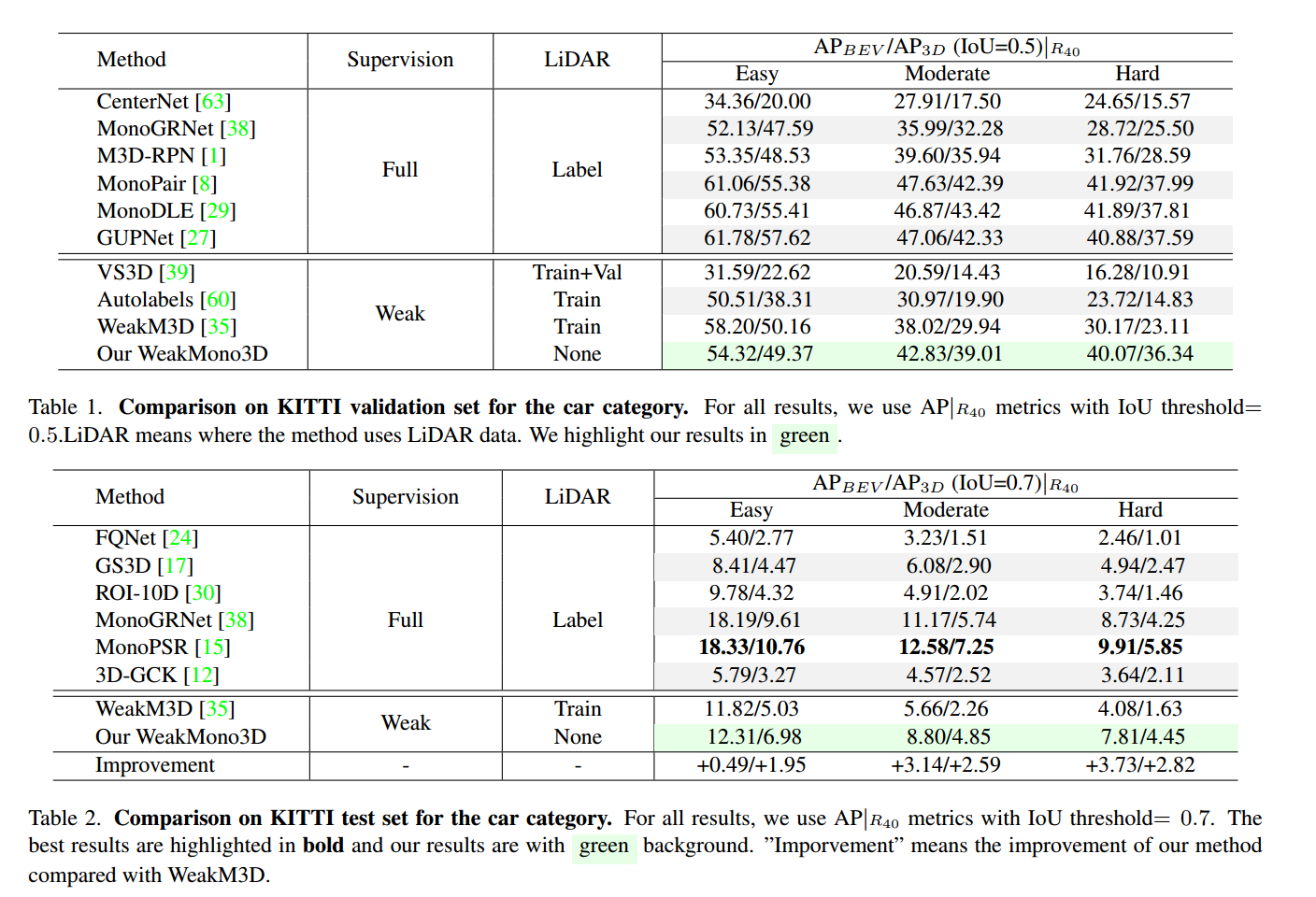
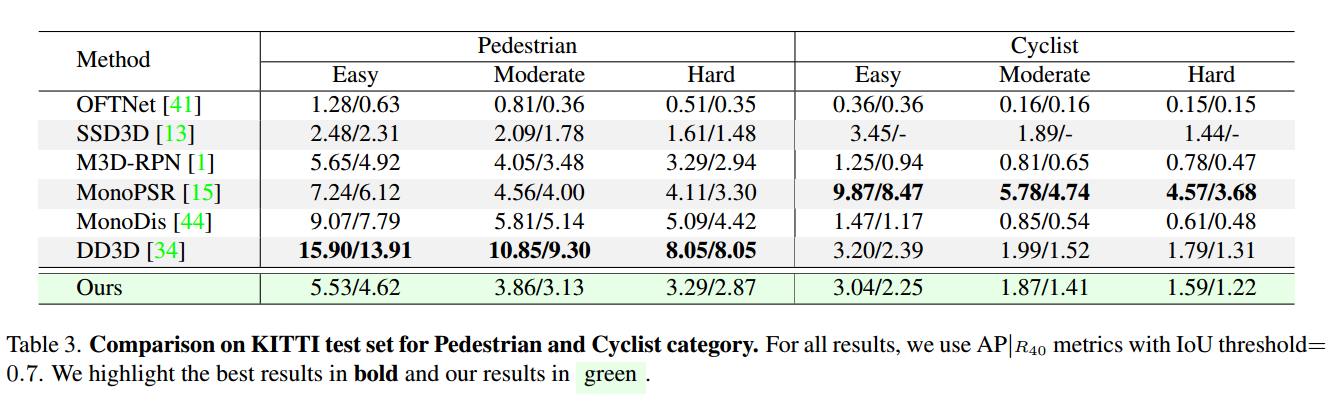
表1。汽车类别的KITTI验证集比较。对于所有结果,我们使用IoU阈值= 0:5的APjR40指标。激光雷达是指该方法使用激光雷达数据的地方。我们用绿色标出我们的结果。
表2。汽车类别的KITTI测试集比较。对于所有结果,我们使用IoU阈值= 0:7的APjR40指标。最好的结果以粗体突出显示,我们的结果以绿色为背景。”“improvement”是指我们的方法相对于WeakM3D的改进。
表3。行人与骑自行车者类别KITTI测试集的比较。对于所有结果,我们使用IoU阈值= 0:7的APjR40指标。我们用粗体突出最好的结果,用绿色突出我们的结果。
conclusion
- 弱监督方法:本文提出了一种新颖的弱监督方法,该方法允许仅使用图像上标记的 2D 标签来训练单目 3D 物体检测模型,从而无需在训练阶段使用 3D 点云数据。这解决了许多现有方法面临的训练和推理之间的不一致问题 [T3]、[T5]。
- 一致性探索:该方法探索了三种一致性——投影、多视图和方向一致性——并设计了相应的损失来指导模型准确预测 3D 边界框。这种综合方法增强了模型从有限监督中学习的能力 [T1]、[T2]。
- 数据集收集:作者收集了一个名为 ProdCars 的新数据集,其中包含带有 2D 框和方向标签的量产汽车图像。该数据集可作为评估所提方法的实用资源,并证明其在实际应用中的有效性 [T4]。
- 性能验证:实验结果表明,所提方法的性能可与全监督方法相媲美,甚至在使用少量 3D 地面真实标签进行微调时,其性能甚至优于其中一些方法。这表明该方法具有根据生产数据反馈改进模型的潜力 [T2]、[T4]。
- 通用框架:所提出的弱监督方法作为通用框架提出,可与各种单目 3D 检测模型集成,使其成为该任务的多功能解决方案 [T5]。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









