







目录
前言
本课程来自深度之眼《多模态》训练营,部分截图来自课程视频。
文章标题:SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
用于密集字幕的全卷积定位网络
作者:Long Chen等
单位:浙大
发表时间:2017 CVPR
Latex 公式编辑器
泛读
CNN具有三个非常重要的性质,channel,spatial,multilayer。现有的基于注意力机制的CNN方法大多只在网络最后一层的引入spatial attention机制。 spatial信息是用于回答“哪里”重要,即feature map中哪些位置更为重要(对应原图中的感受野更为重要),上一篇的adaptive attention则是回答什么时候看重要,这篇文章中提出channel信息是用于回答“哪些”重要,即feature map中的哪些channel
(特征)更为重要,因为不同的channel由不同的filter得到,不同的filter可以认为是不同的特征提取子。而单单在最后一层利用spatial attention,产生了感受野过大,feature map不同位对应感受野差异性不足的问题。
摘要
Visual attention has been successfully applied in structural prediction tasks such as visual captioning and question answering.
第一句提出你要研究什么?
视觉注意已成功应用于结构预测任务,如视觉字幕和问题回答。
Existing visual attention models are generally spatial, i.e., the attention is modeled as spatial probabilities that re-weight the last conv-layer feature map of a CNN encoding an input image.
当前的研究做法是什么?
现存的注意力机制模型大体上是空间的,例如对最后一个特征图的每一个位置赋予一个权值。这种空间注意力机制并不能有效的符合注意力机制的初衷,即:一个动态的与上下文有关系的横跨
时间的特征提取器。
However, we argue that such spatial attention does not necessarily conform to the attention mechanism — a dynamic feature extractor that combines contextual fixations over time, as CNN features are naturally spatial, channel-wise and multi-layer.
经典However引出本文观点:
我们认为空间注意力并太符合注意力机制——一种动态特征提取器,随着时间的推移结合上下文固定,因为CNN具有三个非常重要的性质,channel,spatial,multilayer(通道,空间,多层)。
In this paper, we introduce a novel convolutional neural network dubbed SCA-CNN that incorporates Spatial and Channel-wise Attentions in a CNN. In the task of image captioning, SCA-CNN dynamically modulates the sentence generation context in multi-layer feature maps, encoding where (i.e., attentive spatial locations at multiple layers) and what (i.e., attentive channels) the visual attention is.
继续展开说明本文的实现方法(破题):
在本文中,我们介绍了一种新的卷积神经网络,称为SCA-CNN,它在CNN中融合了空间和通道注意。在图像字幕任务中,SCA-CNN在多层特征图中动态调制句子生成上下文,编码视觉注意的位置(即多层注意的空间位置)和视觉注意的通道。
We evaluate the proposed SCA-CNN architecture on three benchmark image captioning datasets: Flickr8K, Flickr30K, and MSCOCO. It is consistently observed that SCA-CNN significantly out-performs state-of-the-art visual attention-based image captioning methods.
最后给出实验说明:SOTA
我们在
三个基准图像字幕数据集上评估了提出的SCA-CNN架构(Flickr8K, Flickr30K, and MSCOCO)SCA-CNN显著优于最先进的基于视觉注意力的图像字幕方法。
总的来说:
注意力机制已经在自然语言处理和计算机视觉领域取得了很大成功,但是大多数现有的基于注意力的模型只考虑了空间特征,即那些注意模型考虑特征图像中的局部更“重要”的信息,忽略了多通道信息的重要性关系。这篇文章介绍了一种新型的卷积神经网络——SCA-CNN,它融合了空间和信道的注意力机制。
Introduction
已有研究指出,视觉注意力在各种结构预测任务中有效,如图像/视频字幕和视觉问题回答。主要因为人类的视觉并不倾向于一次完整地处理整个图像;相反,人们可根据需要随时随地只关注整个视觉空间的选择性部分。具体来说,注意力不是将图像编码为静态向量,而是允许图像特征从头到尾参与句子向量生成,从而得到更丰富和更长的描述丰富的图像。这样,视觉注意可以被认为是一种动态的特征提取机制,它随着时间的推移结合了上下文固定(上下文向量加强)。
当前SOTA图像特征提取通常采用CNN,吃
W
×
H
×
3
W\times H\times 3
W×H×3的输入,通过包含
C
C
C个通道的filter的卷积层卷积后得到
W
′
×
H
′
×
C
W'\times H'\times C
W′×H′×C大小的特征图,然后再将其作为下一个卷积层的输入。
每个3D特征图中的2D切片通过卷积通道将空间视觉信息进行编码,其中下层过滤器检测低级视觉线索,如边缘和角落,而高层过滤器检测高级语义模式,如某些部件和对象。通过堆叠层,CNN 通过视觉抽象层次结构提取图像特征。因此,CNN图像特征本质上是空间的、通道的和多层的。然而,大多数现有的基于注意力的图像描述模型只考虑了空间特征,即那些注意力模型仅仅通过空间注意力权重将句子上下文提取到最后一个卷积层特征图中。
在本文中,我们将充分利用 CNN 的三个特征(channel,spatial,multilayer)进行基于视觉注意力的图像描述。因此我们提出了一种新颖的基于空间和通道注意力机制的卷积神经网络,称为 SCA-CNN,它学习关注多层 3D特征图中的每个特征条目。图1说明了如何在多层特征图中引入通道注意的动机。
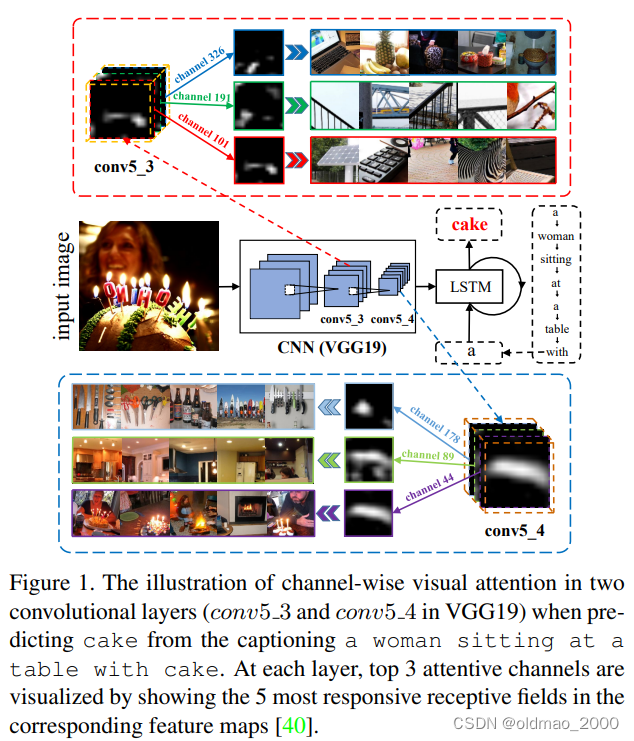
首先,由于channel-wise feature map本质上是相应过滤器的检测器响应图,channel-wise attention可以看作是根据句子上下文的需求选择语义属性的过程。例如,当我们想要预测“蛋糕”这个词时,我们的通道级注意力(例如,在
c
o
n
v
5
_
3
/
c
o
n
v
5
_
4
conv5\_3/conv5\_4
conv5_3/conv5_4特征图中)将为 cake、fire、光和蜡烛的形状分配更多的注意力。
其次,由于特征图依赖于其下层特征图,因此很自然地在多层中应用注意力,从而在多个语义抽象上获得视觉注意力。例如,比如,在前层中对feature map中含有的较低级的semantic attributes,例如圆柱体(蛋糕的形状)、阵列(蜡烛的排放),赋予更大的权重,对于cake这个单词的预测是很有益的。
我们在三个数据集中验证了模型的有效性。在BLEU4中可以显著超过空间注意力模型4.8%(这里对比的是Show, attend and tell那个模型)。
总之,我们提出了一个统一的SCA-CNN框架,以有效地将空间、频道和多层视觉注意力集成到CNN图像字幕特征中。特别是,提出了一种新的空间和通道注意模型。该模型是通用的,因此可以应用于任何CNN架构中的任何层,如流行的VGG和ResNet。SCA-CNN帮助我们更好地理解CNN特征在句子生成过程中的演变。
Related Work
本文致力于研究将视觉注意力机制应用到Encoder-Decoder框架中,以解决当前流行的neural image/video captioning (NIC)和visual question answering (VQA)任务。然后啰嗦一下当前是怎么做的。
接However转折提出不足,并分三个小节进行详细解读:
然而,静态向量无法使图像特征适应当前的句子语境。受机器翻译中引入的注意力机制的启发,解码器会动态选择有用的源语言单词或子序列翻译成目标语言,视觉注意力模型已被广泛应用于 NIC 和 VQA 中。我们将这些基于注意力的模型分为以下三个领域(亦为SCA-CNN提供了灵感):
Spatial Attention.
【Show, attend and tell】一文第一次提出图像字幕的视觉注意力模型。他们使用“硬”注意力来选择最可能关注的区域,或者使用“软”注意力来平均具有关注权重的空间特征。对于VQA任务,李飞飞团队提出使用“软”注意力来合并图像区域特征。为了进一步细化空间注意力,两个团队应用了堆叠的空间注意力模型,其中第二注意力基于第一注意力调制的注意力特征图。本文与之不同,本文的多层注意力应用于CNN的多层。
以上研究的空间模型的一个常见缺陷是,它们通常依赖于关注特征图上的加权池。因此,空间信息将不可避免地丢失。更严重的是,他们的注意力仅应用于最后一个对流层,在那里,感受野的大小将非常大,每个感受野区域之间的差异非常有限,导致空间注意力不显著。
Semantic Attention.
【 Image captioning with semantic attention(第五篇带读)】在NIC任务中提出了选择语义概念,其中图像特征是属性分类器的置信度向量。【Guiding the long-short term memory model for image caption generation】提出利用图像及其字幕之间的相关性作为全局语义信息来
指导LSTM生成句子。
然而,这些模型需要外部资源来训练这些语义属性。在本文的模型中,卷积层的每个滤波器内核充当语义检测器,因此,通道式注意力原理与语义注意力类似。
Multi-layer Attention.
CNN对应于不同特征图层的各个感受野的大小是不同的。为了克服上一个卷积层注意力中感受野较大的弱点,【Hierarchical attention networks.】提出了一种多层注意力网络,SCA-CNN也使用了该设计。
精读
Spatial and Channel-wise Attention CNN
Overview
本文模型是对图像字幕任务的Encoder-Decoder框架进行魔改,该框架通常使用CNN做Encoder吃图片吐向量,然后使用LSTM将向量Decoder为一个词序列。
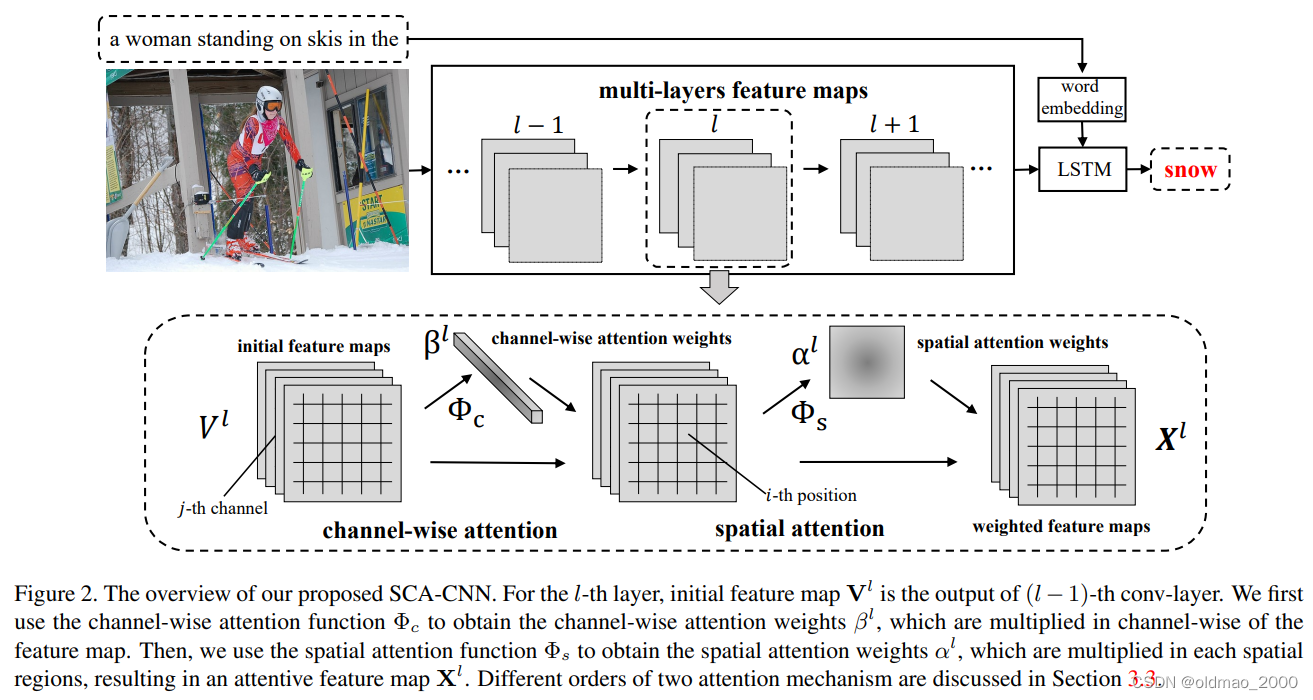
如上图所示,SCA-CNN通过多层的通道关注和空间关注,使原来的CNN多层特征图可适应句子的上下文。
假设我们想要生成图像标题的第
t
t
t个单词,已知条件包括:
上个句子上下文编码在LSTM的隐藏层为
h
t
−
1
∈
R
d
h_{t-1}\in\R^d
ht−1∈Rd,
d
d
d为隐藏层的维度;
在第
l
l
l层的空间和channel-wise注意力权重为
γ
l
\gamma^l
γl,该权重可由
h
t
−
1
h_{t-1}
ht−1以及当前的CNN特征
V
l
V^l
Vl通过某函数计算得来;
则SCA-CNN的多层迭代表示为:
V
l
=
C
N
N
(
X
l
−
1
)
,
γ
l
=
Φ
(
h
t
−
1
,
V
l
)
,
X
l
=
f
(
V
l
,
γ
l
)
.
\begin{aligned}V^l&=CNN(X^{l-1}),\\ \gamma^l&=\Phi(h_{t-1},V^l),\\ X^l&=f(V^l,\gamma^l). \end{aligned}
VlγlXl=CNN(Xl−1),=Φ(ht−1,Vl),=f(Vl,γl).
其中,
X
l
X^l
Xl是调制特征;
Φ
(
⋅
)
\Phi(\cdot)
Φ(⋅) 是空间和信道注意函数;
V
l
V^l
Vl是前一个卷积层(conv+pooling)的输出特征图;
f
(
⋅
)
f(\cdot)
f(⋅)是线性加权函数,用于调制CNN特征和注意力权重,这里不使用将视觉特征累加求和的方式来调制CNN特征(又是 Show, attend and tell),而是使用element-wise的乘法来完成。
生成第
t
t
t个单词的公式可表示为:
h
t
=
LSTM
(
h
t
−
1
,
X
L
,
y
t
−
1
)
,
y
t
∼
p
t
=
softmax
(
h
t
,
y
t
−
1
)
.
\begin{aligned}h_t&=\text{LSTM}(h_{t-1},X^L,y_{t-1}),\\ y_t&\sim p_t = \text{softmax}(h_t,y_{t-1}). \end{aligned}
htyt=LSTM(ht−1,XL,yt−1),∼pt=softmax(ht,yt−1).
L
L
L是卷积层的层数;
p
t
∈
R
∣
D
∣
p_t\in \R^{|\mathcal{D}|}
pt∈R∣D∣是概率向量,
D
\mathcal{D}
D是预先定义的词表大小(含所有caption单词)。
由于注意力
γ
l
\gamma^l
γl与
V
l
,
X
l
V^l,X^l
Vl,Xl维度一样,因此注意力计算的空间复杂度高达:
O
(
W
l
H
l
C
l
k
)
\mathcal{O}(W^lH^lC^lk)
O(WlHlClk),这里的
k
k
k是CNN隐藏层维度大小。这个大小内存吃不消,因此,本文提出了分别计算通道层面的注意力
β
l
\beta^l
βl和空间层面的注意力
α
l
\alpha^l
αl分开计算:
α
l
=
Φ
s
(
h
t
−
1
,
V
l
)
,
(3)
\alpha^l=\Phi_s(h_{t-1},V^l),\tag 3
αl=Φs(ht−1,Vl),(3)
β
l
=
Φ
c
(
h
t
−
1
,
V
l
)
.
(4)
\beta^l=\Phi_c(h_{t-1},V^l).\tag 4
βl=Φc(ht−1,Vl).(4)
分开计算后空间复杂度为:通道层面的注意力:
O
(
W
l
H
l
k
)
\mathcal{O}(W^lH^lk)
O(WlHlk);空间层面的注意力:
O
(
C
l
k
)
\mathcal{O}(C^lk)
O(Clk)。
Spatial Attention
一般来说,标题词只与图像的特定区域有关。例如,在图 1 中,当我们要预测“cake”时,只有包含蛋糕的图像区域才有用。因此,应用全局图像特征向量来生成标题可能会因无关区域而导致次优结果。空间注意力机制不应该对每个图像区域一视同仁,而是应试图更多地关注与语义相关的区域。
在不失一般性的前提下,我们去掉层notation的上标
l
l
l。并对原始V的宽度和高度进行flatten操作,得到:
V
=
[
v
1
,
v
2
,
⋯
,
v
m
]
\text{V}=[\text{v}_1,\text{v}_2,\cdots,\text{v}_m]
V=[v1,v2,⋯,vm],其中
v
i
∈
R
C
,
m
=
W
⋅
H
\text{v}_i\in\R^C,m=W\cdot H
vi∈RC,m=W⋅H,
v
i
\text{v}_i
vi是第
i
i
i个位置的视觉特征。给定LSTM的上一个隐藏层为
h
t
−
1
h_{t-1}
ht−1,我们使用单层神经网络,然后使用Softmax函数来生成图像区域上的注意力分布
α
\alpha
α,则空间层面的注意力模型
Φ
s
\Phi_s
Φs可以写为:
a
=
tanh
(
(
W
s
V
+
b
s
)
⊕
W
h
s
h
t
−
1
)
,
α
=
softmax
(
W
i
a
+
b
i
)
.
\begin{aligned}\text{a}&=\tanh((W_s\text{V}+b_s)\oplus W_{hs}h_{t-1}),\\ \alpha &= \text{softmax}(W_i\text{a}+b_i).\end{aligned}
aα=tanh((WsV+bs)⊕Whsht−1),=softmax(Wia+bi).
其中
W
s
∈
R
k
×
C
,
W
h
s
∈
R
k
×
d
,
W
o
∈
R
k
W_s\in\R^{k\times C},W_{hs}\in\R^{k\times d},W_o\in\R^k
Ws∈Rk×C,Whs∈Rk×d,Wo∈Rk均为变换矩阵,将图像视觉特征和隐藏状态映射到相同维度;
⊕
\oplus
⊕⨁为矩阵和向量之间的加法,矩阵和向量之间的加法是通过将矩阵的每一列与向量相加来实现的;
b
s
∈
R
k
,
b
i
∈
R
l
b_s\in\R^k,b_i\in\R^l
bs∈Rk,bi∈Rl为模型的偏置。
Channel-wise Attention
需要注意的是,公式(3)中的空间注意函数仍然需要视觉特征
V
\text{V}
V 来计算空间注意权重,但空间注意中使用的视觉特征
V
\text{V}
V 事实上并不是基于注意的。因此,我们引入了一种通道式注意力机制来关注特征
V
\text{V}
V。
值得注意的是,每个 CNN 滤波器都是一个模式检测器,而 CNN 中特征图的每个通道都是相应卷积滤波器的响应激活。因此,以通道方式应用注意力机制可以被视为一个选择语义属性的过程。
首先将
V
\text{V}
V reshape为
U
U
U,
U
=
[
u
1
,
u
2
,
⋯
,
u
C
]
,
u
i
∈
R
W
×
H
U=[u_1,u_2,\cdots,u_C],u_i\in\R^{W\times H}
U=[u1,u2,⋯,uC],ui∈RW×H,
u
i
u_i
ui表示
V
\text{V}
V中第
i
i
i个通道的特征,
C
C
C为通道总数,然后,我们对每个通道进行平均池化以获得通道特征
v
\text{v}
v:
v
=
[
v
1
,
v
2
,
⋯
,
v
C
]
,
v
∈
R
C
\text{v}=[v_1,v_2,\cdots,v_C],\text{v}\in\R^C
v=[v1,v2,⋯,vC],v∈RC
其中标量
v
i
v_i
vi是向量
u
i
u_i
ui的平均值,同理
Φ
c
\Phi_c
Φc的定义可写为:
b
=
tanh
(
(
W
c
V
+
b
c
)
⊗
W
h
c
h
t
−
1
)
,
α
=
softmax
(
W
′
i
b
+
b
′
i
)
.
\begin{aligned}\text{b}&=\tanh((W_c\text{V}+b_c)\otimes W_{hc}h_{t-1}),\\ \alpha &= \text{softmax}({W'}_i\text{b}+{b'}_i).\end{aligned}
bα=tanh((WcV+bc)⊗Whcht−1),=softmax(W′ib+b′i).
W
c
∈
R
K
,
W
h
c
∈
R
k
×
d
,
W
′
i
∈
R
k
W_c\in\R^K,W_{hc}\in\R^{k\times d},{W'}_i\in\R^k
Wc∈RK,Whc∈Rk×d,W′i∈Rk是变换矩阵;
原文
⊗
\otimes
⊗写成
⊕
\oplus
⊕了,应该是笔误,这里代表两个向量的外积;
b
c
∈
R
k
,
b
′
i
∈
R
l
b_c\in\R^k,{b'}_i\in\R^l
bc∈Rk,b′i∈Rl是偏置。
根据计算空间层面注意力和通道层面注意力的先后顺序,我们的SCA-CNN也可以细分为S-C(Spatial-Channel)和C-S(Channel-Spatial)类型,值得注意的是此时后一步运算用到的特征图样已不再是原始的特征图样,而是经前一步得到注意力加权得到的图样。
Channel-Spatial
通道-空间注意力流程见上面图2。在给定初始特征图
V
\text{V}
V,采用基于通道的注意权重
Φ
c
\Phi_c
Φc 来获得通道通道的注意权重
β
\beta
β。通过
β
\beta
β和
V
\text{V}
V的线性组合,我们得到了按通道加权的特征映射。然后将通道加权特征图反馈给空间注意力模型
Φ
s
\Phi_s
Φs,得到空间注意力权重
α
\alpha
α。在获得两个注意力权重
α
\alpha
α和
β
\beta
β后,我们可以将
V
\text{V}
V、
β
\beta
β,
α
\alpha
α丢到调制函数
f
f
f以计算调制特征图
X
\text{X}
X。
f
c
(
.
)
f_c(.)
fc(.)是特征图通道和相应通道权重的通道乘法。
β
=
Φ
c
(
h
t
−
1
,
V
)
,
α
=
Φ
s
(
h
t
−
1
,
f
c
(
V
,
β
)
)
,
X
=
f
(
V
,
α
,
β
)
.
(8)
\begin{aligned}\beta&=\Phi_c(h_{t-1},\text{V}),\\ \alpha&=\Phi_s(h_{t-1},f_c(\text{V},\beta)),\\ \text{X}&=f(\text{V},\alpha,\beta).\end{aligned}\tag8
βαX=Φc(ht−1,V),=Φs(ht−1,fc(V,β)),=f(V,α,β).(8)
Spatial-Channel
在给定初始特征图
V
\text{V}
V,采用基于通道的注意权重
Φ
s
\Phi_s
Φs 来获得通道通道的注意权重
α
\alpha
α。基于
α
\alpha
α、线性函数
f
s
(
⋅
)
f_s(\cdot)
fs(⋅)和通道方向注意模型
Φ
c
\Phi_c
Φc ,我们可以按照上面C-S类型的方法来计算调制特征
X
\text{X}
X。
α
=
Φ
s
(
h
t
−
1
,
V
)
,
β
=
Φ
c
(
h
t
−
1
,
f
s
(
V
,
α
)
)
,
X
=
f
(
V
,
α
,
β
)
.
(9)
\begin{aligned}\alpha&=\Phi_s(h_{t-1},\text{V}),\\ \beta&=\Phi_c(h_{t-1},f_s(\text{V},\alpha)),\\ \text{X}&=f(\text{V},\alpha,\beta).\end{aligned}\tag9
αβX=Φs(ht−1,V),=Φc(ht−1,fs(V,α)),=f(V,α,β).(9)
f
s
(
.
)
f_s(.)
fs(.)是特征图通道和区域权重的元素级乘法。
Experiments
我们将通过以下三个问题来验证所提出的 SCA-CNN 框架在图像字幕制作方面的有效性:
问题 1 通道注意力是否有效?它能提高空间注意力吗?
问题 2 多层注意力是否有效?
问题 3 与其他最先进的视觉注意力模型相比,SCA-CNN 的表现如何?
Dataset and Metric
数据集还是老三样,直接上表:
| Flickr8k | Flickr30k | MSCOCO | MSCOCO’ | |
|---|---|---|---|---|
| 图片总数 | 8,000 | 31,000 | ||
| Training set | 6,000 | 29,000 | 82,783 | 82,783 |
| Validation set | 1,000 | 1,000 | 40,504 | 5,000 |
| Test set | 1,000 | 1,000 | 40,775 | 5,000 |
MSCOCO’是应为官方数据集没有Ground truth,因此专门切了验证和测试的子数据集来进行模型选择和本地实验。
Metric包括:
BLEU (B@1,B@2, B@3, B@4)
METEOR(MT)
CIDEr(CD)
ROUGE-L (RG)
这四个指标衡量的是生成句子中的 n-gram 出现率与ground-truth句子中的 n-gram 出现率之间的一致性,这种一致性根据 n-gram 的显著性和稀有性进行加权。同时,所有四个指标都可以通过 MSCOCO 标题评估工具直接计算。
设置
本文的SCA-CNN模型对于图像编码部分用了两种CNN架构:VGG-19和ResNet-152。
对于字幕解码部分,我们使用LSTM来生成字幕词。词嵌入维度和LSTM隐藏状态维度分别设置为100和1,000。对于这两种类型的注意力,计算注意力权重的共同空间维度则设置为512。对于Flickr8k,迷你批次大小被设置为16,而对
于Flickr30k和MSCOCO, mini-batch大小被设置为64。我们使用抓爆和early stopping停止来避免过拟合。我们的整个框架是用Adadelta进行端到端的训练,这是一种使用自适应学习率算法的随机梯度下降法。当预测到END标记或达到预定的最大句子长度则停止caption生成。在测试过程中,还使用了波束大小为5的BeamSearch。我们注意到一个将波束搜索与长度归一化结合起来的技巧[11],它可以在一定程度上帮助提高性能。但是为了进行公平的比较,所有报告的结果都没有进行长度标准化。
评估Channel-wise Attention(问题1)
我们首先比较了空间注意和通道式注意。1)S:它是一个纯粹的空间注意模型。在获得基于最后一个卷积层的空间注意权重后,我们使用逐元素的乘法来产生一个空间加权的特征。对于VGG19和ResNet-152,最后一个卷积层分别代表
c
o
n
v
5
4
conv5_4
conv54层和
r
e
s
5
c
res5c
res5c。
我们不把加权特征图视为最终的视觉表现,而是把空间加权特征送入它们自己的后续CNN层。对于VGG-19,在
c
o
n
v
5
4
conv5_4
conv54层之后有两个全连接层,对于ResNet-152,
r
e
s
5
c
res5c
res5c层之后有一个平均池层。
2)C型:它是一个纯粹的逐通道的注意力模型。C型模型的整个策略与S型相同。唯一的区别是用逐通道的注意力代替空间注意力,如公式(4)。
3)C-S型:这是第一种类型的模型,包含两种注意机制,如公式(8)。
4)S-C。另一个结合了公式(9)的模型。
- SAT。这是在【Show, attend and tell】中引入的 "硬 "注意力模型。我们之所以报告 "硬 "注意力而不是 "软 "注意力的结果,是因为 "硬 "注意力在不同的数据集和指标上总是有更好的表现。SAT也是一个和S一样的纯空间注意模型,但有两个主要区别:第一个是用注意力权重来调节视觉特征的策略。第二个是是否将出席的特征送入其后续层。表1中报告的所有VGG结果都来自原始论文,ResNet结果是我们自己实现的。
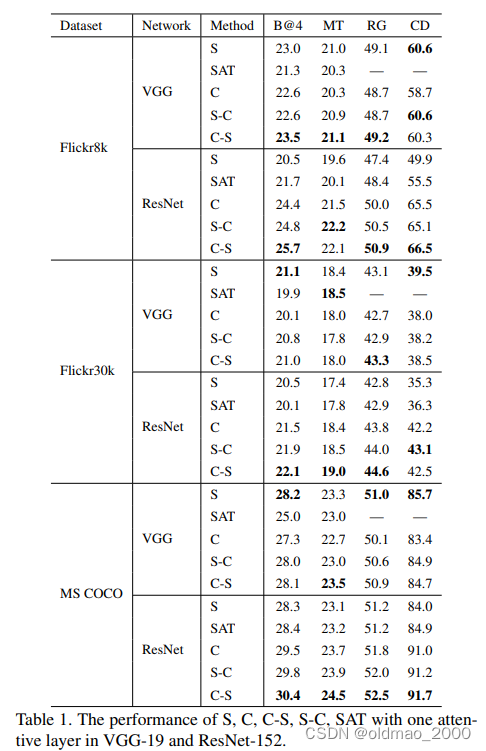
根据表1,我们得出以下结论:
1)使用VGG-19,S比SAT好;使用ResNet-152,SAT性能要优于S。这是因为VGG-19网络具有完全连接层,可以保留空间信息,但是,ResNet-152最后的卷积层后面平均池化层,因此无法保存空间信息。
2)比较C 和S的性能,ResNet-152可以比VGG-19网络显着改善C性能,这表明更多的通道数可以提高通道的注意性能,因为ResNet-152比VGG-19具有更多的通道数。
3)在VGG-19和ResNet-152中,S-C和S-C的性能非常相似。通常,C-S比S-C稍好一些,这可能是由于通道方向的特征更加关注。
4)在ResNet-152中,C-S或S-C可以明显改善S的性能。这表明,通过增加按通道注意,可以在通道数量较大时显着提高性能。
评估Multi-layer Attention(问题2)
这个实验将研究是否可以通过增加注意层来提高空间注意或通道注意性能。我们对 S 和 C-S 模型中不同的注意层数进行了消融实验。其中,我们分别用1层、2层、3层来表示配备注意力的层数。对于 VGG-19,第1层、第2层、第3层分别代表
c
o
n
v
5
4
conv5_4
conv54、
c
o
n
v
5
3
conv5_3
conv53、
c
o
n
v
5
2
conv5_2
conv52卷积层。至于 ResNet-152,它代表
r
e
s
5
c
res5c
res5c、
r
e
s
5
c
b
r
a
n
c
h
2
b
res5c_branch2b
res5cbranch2b、
r
e
s
5
c
b
r
a
n
c
h
2
a
res5c_branch2a
res5cbranch2a卷积层。具体来说,我们训练更多注意层模型的策略是利用以前训练过的注意层权重作为初始化,这样可以大大缩短训练时间,并取得比随机初始化更好的效果。
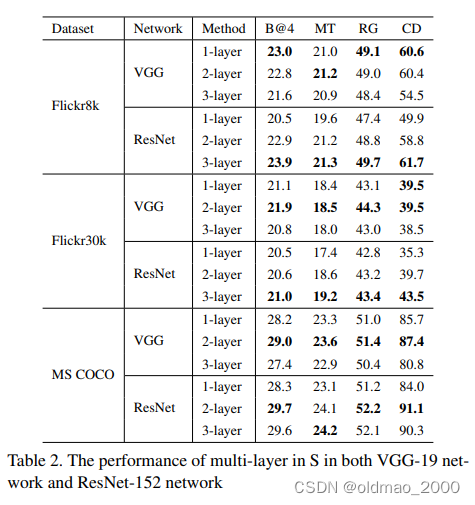
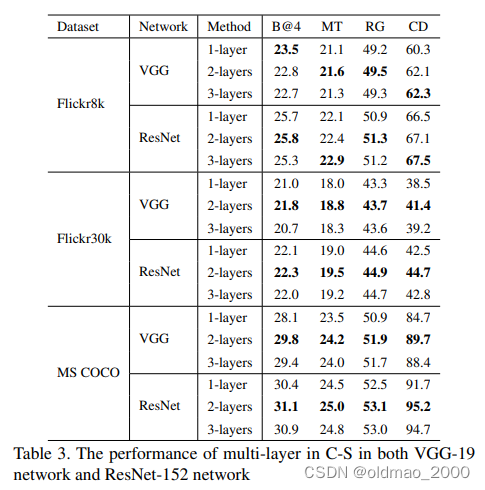
实验结果:
- 在大多数实验中,添加更多的注意力层可以在两个模型中取得更好的结果。原因是在多层中应用注意力机制有助于获得对多层语义抽象的视觉注意力。
2)层数过多也容易导致严重的过拟合。例如,由于 Flickr8k 的训练集规模(6000)远小于 MSCOCO(82783),因此在增加更多注意层时,Flickr8k 的性能比 MSCOCO 更容易下降。
与SOTA比较(问题3)
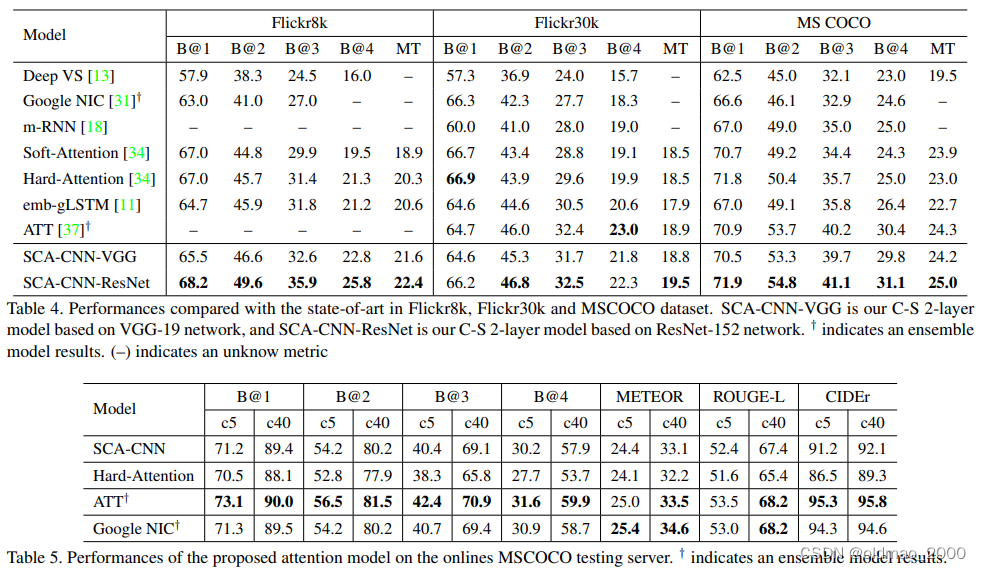
我们将所提出的 SCA-CNN 与SOTA模型进行了比较。
1)Deep VS、m-RNN和 Google NIC都是端到端的多模态网络,结合了用于图像编码的 CNN 和用于序列建模的 RNN。
2) Soft-Attention和 Hard-Attention都是纯空间注意力模型。"软"注意力加权将视觉特征相加作为注意力特征,而 "硬 "注意力加权则随机抽样区域特征作为注意力特征。
3) emb-gLSTM和 ATT都是语义注意模型。对于 emb-gLSTM,它利用图像与其描述之间的相关性作为全局语义信息,而对于ATT,它利用视觉概念对应的单词作为语义信息。
表 4 中报告的是 VGG-19 和 ResNet-152 网络的 2 层 C-S 模型的结果,因为这种模型在之前的实验中总是获得最佳性能。除了这三个基准测试,我们还在 MSCOCO 图像挑战赛 c5 和 c40 中对我们的模型进行了评估,并将结果上传到官方测试平台(结果见表5)。
实验结果:
我们可以看到,在大多数情况下,SCA-CNN优于其他模型。 这是由于SCA-CNN利用空间,通道和多层注意力,而大多数注意力模型仅关注一种注意力类型。请注意,我们不能超越ATT和谷歌NIC的原因有两个:
一是他们声称使用集成(ensemble)模型。然而,作为一个单一的模型,SCA-CNN仍然可以达到与集成模型相比较的结果。
二是他们使用更牛×的CNN模型,例如谷歌NIC魔改的Inception-v3分类性能吊打本文的ResNet。
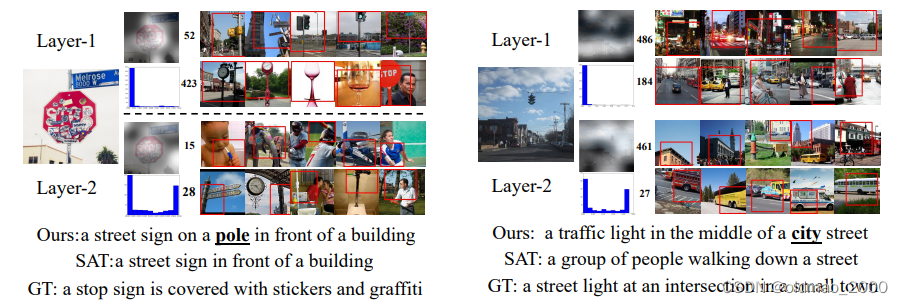
可视化
为简单起见,我们只将单词预测步骤的结果可视化。例如,在第一个样本中,当 SCA-CNN 模型尝试预测单词 umbrella 时,我们对通道的关注会根据语义(如伞、棍子和圆形)为过滤器生成的特征图通道分配更多权重。每一层的直方图表示所有通道的概率分布。直方图上方的地图是空间注意力地图,白色表示模型大致关注的空间区域。我们为每一层选择了两个关注度最高的通道。


结论
本文提出了一种新的深度注意力模型,称为SCA-CNN,用于图像字幕。SCA-CNN充分利用了CNN的特点,产生了关注的图像特征:空间、频道和多层,从而在流行的基准上实现了最先进的性能。
SCA-CNN的贡献不仅在于更强大的注意力模型,还在于更好地理解在句子生成过程中演变的CNN中注意力的位置(即空间)和内容(即频道)。在未来的工作中,我们打算在SCA-CNN中引入时间注意力,以便关注视频字幕的不同视频帧中的特征。我们还将研究如何在不过度拟合的情况下
增加关注层的数量。
















 5463
5463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











