







1. 前言
视觉上的attention已经被成功运用在了结构预测任务中。例如,visual captioning与question answering。现有的视觉attention模型都是基于空间的,既是重新加权最后一个卷积层的feature map。其原理如下图所示,但是这样的或许并不能会很好符合attention的机制。
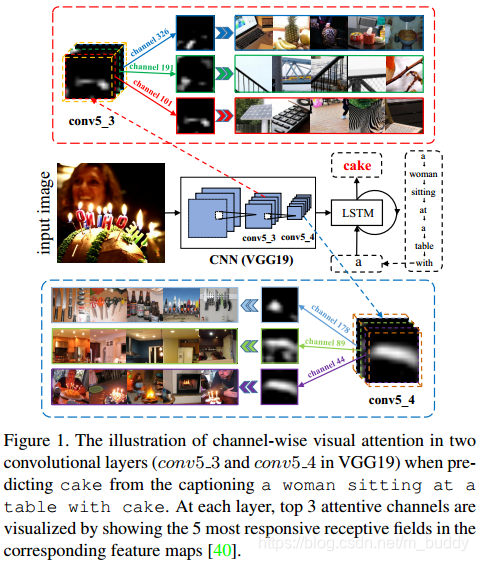
文章中指出,基于CNN的原理,其所提取的feature map具有spatial、channel-wise(semantic)、multi-layer的属性。但现有的一些image caption方法主要考虑spatial的属性,其中运用的attention机制也都是spatially attentive weight。因而在此基础上论文提出,充分利用CNN以上三个属性来进行image caption的任务,提出利用spatial、channel-wise(semantic)和multi-layer结合的属性进行attention机制的应用,相互影响,相互促进,有很好的效果,取名SCA-CNN。
2. SCA-CNN网络
2.1 网络结构
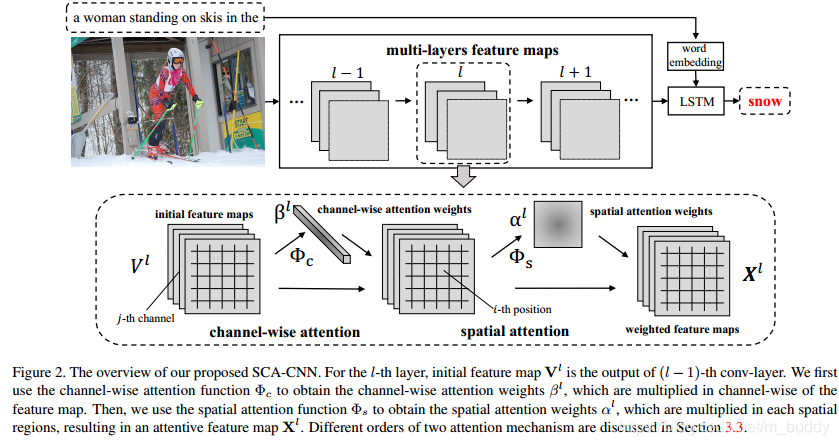
其网络结构如上图,可以看到在每层的feature map上先后做了channel-wise与spatial的attention,里面根据卷积feature map中channel与spatial的特性对其进行加权组合。对于前面两种:spatial、channel-wise的attention比较容易理解,那么如何将其扩展到multi-layer上呢?论文中是使用模块堆叠实现的。也正如上面结构中的 l − 1 l-1 l−1、 l l l、 l + 1 l+1 l+1特征层。了解了网络的结构,那么接下来就看一下其内部是怎么实现这些的。
2.2 spatial attention
首先,来看一下整个attention的更新方式,其更新方式如下:
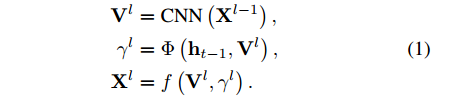
其中, X l − 1 X^{l-1} Xl−1是卷积特征层; V l V^{l} Vl可以看作是SCA-CNN的模块运算中间变量; h t − 1 h_{t-1} ht−1是 d d d维度的上一时刻的LSTM层hidden输出; γ l \gamma^{l} γ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1040
1040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









