







1、动态规划(dynamic Programming)
动态规划不像贪心算法,从名字上很难理解具体的算法思想,如果换个名字应该就好理解了,动态规划在一定程度上可以简单理解为自顶向下的有缓存的递归,当然也可以使用自底向上的循环解法。大家应该知道,递归过程中产生了大量的重复计算,从而导致大量耗时,那如何避免这些不必要的重复计算呢?
那就是 缓 存 \color{#F00}{缓存} 缓存,当第一次计算这些值的时候,把它们缓存起来,等到再次使用,直接把它们拿过来用,这样就不用做大量的重复计算了。这就是动态规划的核心思想。
2、两个条件:
如果可以把局部子问题的解结合起来得到全局最优解,那这个问题就具备最优子结构;
如果计算最优解时需要处理很多相同的问题,那么这个问题就具备重复子问题。
3、比较动态规划与递归
fibonacci数列是递归算法的一个典型的例子,现利用fibonacci数列来比较两种算法,看一下缓存带来的速度提升:
(1)递归实现:
import time
def fibonacci(n):
if n == 0 or n == 1:
return 1
else:
return fibonacci(n - 1) + fibonacci(n - 2)
n = 36
start = time.perf_counter()
fibonacci(n)
end = time.perf_counter()
print ("fibnacci sequense costs:", end-start)
运行结果:
fibnacci sequense costs: 10.546088888
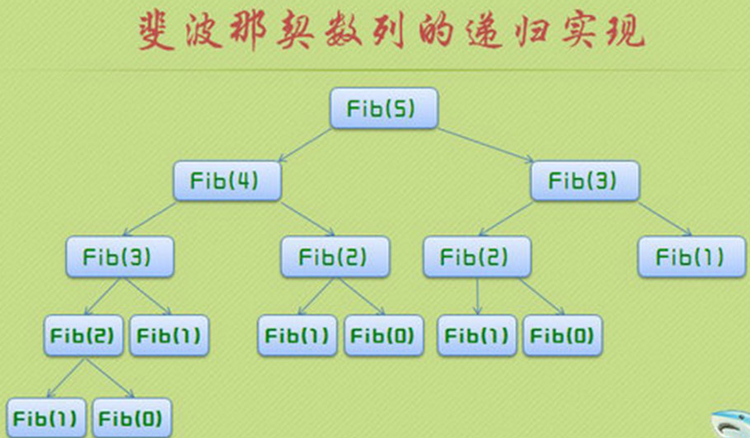
以fibnacci(5) 位例子,每次计算fibnacci(5) 都要计算fibnacci(4) 和fibnacci(3) ,而fibnacci(4)要计算fibnacci(3) 和fibnacci(2) ,fibnacci(3)要计算fibnacci(2) 和fibnacci(1) ,一直这样递归下去,做了大量的重复计算。而函数调用是很费时间和空间的。
函数调用的过程(C++):
• 函数执行前,把实参复制给形参,复制过程是由形参类型的复制构造函数来完成的;
• 函数返回时,返回的是一个值,返回的对象被复制到调用环境中;
• 当函数运行结束时,形参类型的析构函数负责释放形参,临时变量生存期结束,所占用的空间均被释放,函数调用不会修改与形参对应的实参的值。
由下图可以直观的看出递归的重复计算:
(2)动态规划实现:
- 自顶向下的有缓存的递归实现
import time
def fibonacci_dp(n, memo={}):
if n == 0 or n == 1:
return 1
try:
return memo[n]
except KeyError:
result = fibonacci_dp(n - 1) + fibonacci_dp(n - 2)
memo[n] = result
return result
n = 36
start = time.perf_counter()
fibonacci_dp(n)
end = time.perf_counter()
print ("fibnacci sequense costs:", end-start)
运行结果:
fibnacci sequense costs: 4.7621999999997167e-05
从结果可以看出,使用缓存后的递归(动态规划),时间上提升了5个数量级,从算法复杂度上来讲动态规划每次只调用fibonacci_dp函数一次,所以复杂度为O(n) ,这就是缓存带来的速度提升。
- 自底向上的循环实现:
def fibonacci(n):
fib = [0] * (n + 1)
fib[0] = 1
fib[1] = 1
for i in range(2, n + 1):
fib[i] = fib[i - 1] + fib[i - 2]
return fib[n]
if __name__ == '__main__':
start_time = time.perf_counter()
result = fibonacci(36)
end_time = time.perf_counter()
print(result)
print("fibnacci sequense costs:", end_time - start_time)
运行结果:
24157817
fibnacci sequense costs: 1.477910169335663e-05
采用从底向上的循环解法,速度提升更明显。
4、动态规划解决0/1背包问题
[0-1背包问题] 有一个背包,背包容量是M=150kg。有7个物品,物品不可以分割成任意大小。
要求:尽可能让装入背包中的物品总价值最大,但不能超过总容量。
| 物品 | A | B | C | D | E | F | G |
|---|---|---|---|---|---|---|---|
| 重量 | 35kg | 30kg | 6kg | 50kg | 40kg | 10kg | 25kg |
| 价值 | 10 | 40 | 30 | 50 | 35 | 40 | 30 |
   \;
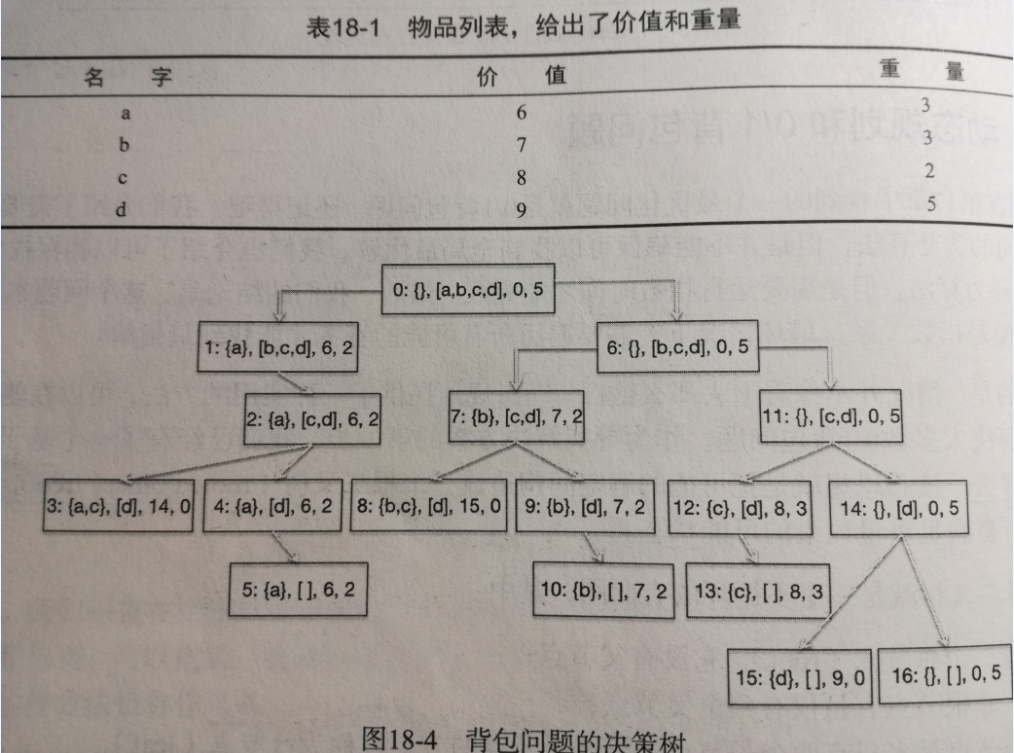
0-1背包问题转化为二叉树:
其中:二叉树的节点中,第一项为已选物品,第二项为待选物品,第三项为背包价值,第四项为背包剩余容量;
0-1背包问题如何转化为递归解决?
背包问题就是对已有的物品作出选择,每个物品有两种选择:装包或不装包,因此该问题可以转化为二叉树,如上图所示。
左子树为选择待选物品中的第一个物品,右子树为不选择该物品;
若选择的物品容量比背包剩余容量要大,则该节点只有右子树。
递归终止条件:
1、没有剩余物品;
2、背包没有剩余空间。
算法实现(python 3):
(1)递归:
import time
"""
递归:
"""
class Item(object):
def __init__(self, n, v, w):
self.name = n
self.value = float(v)
self.weight = float(w)
def get_name(self):
return self.name
def get_value(self):
return self.value
def get_weight(self):
return self.weight
def __str__(self):
return '<' + self.name + ',' + str(self.value) + ',' + str(self.weight) + '>'
# 递归终止条件:没有剩余物品;背包没有剩余空间
def max_value(bag_set, remain_room):
# leaf
if bag_set == [] or remain_room == 0:
return 0, ()
# only has the right tree
elif bag_set[0].get_weight() > remain_room:
return max_value(bag_set[1:], remain_room)
# select max value from left and right tree
else:
next_item = bag_set[0]
left_value, left_taken = max_value(bag_set[1:], remain_room - next_item.get_weight())
left_value += next_item.get_value()
right_value, right_taken = max_value(bag_set[1:], remain_room)
if left_value > right_value:
return left_value, left_taken + (next_item,)
else:
return right_value, right_taken
def built_item():
names = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
values = [35, 30, 6, 50, 40, 10, 25]
weights = [10, 40, 30, 50, 35, 40, 30]
Items = []
for i in range(len(names)):
Items.append(Item(names[i], values[i], weights[i]))
return Items
if __name__ == '__main__':
start = time.perf_counter()
items = built_item()
max_value, taken = max_value(items, 150)
print('Total value of items taken = ', max_value)
print('the items of bag is: ')
for item in taken:
print(item)
end = time.perf_counter()
print("runing time is %f" % (end - start))
运行结果:
Total value of items taken = 155.0
the items of bag is:
<E,40.0,35.0>
<D,50.0,50.0>
<B,30.0,40.0>
<A,35.0,10.0>
runing time is 0.000422
(2)动态规划:
要想用动态规划,首先要满足两个条件:重复子问题 和 最优子结构
- 同一层的每个节点剩余的可选物品集合都是一样的,所以具有重复子问题;
- 每个父节点会组合子节点的解来得到这个父节点为根的子树的最优解,所以存在最优子结构;
故采用动态规划实现0-1背包问题:
import time
"""
动态规划:
"""
class Item(object):
def __init__(self, n, v, w):
self.name = n
self.value = float(v)
self.weight = float(w)
def get_name(self):
return self.name
def get_value(self):
return self.value
def get_weight(self):
return self.weight
def __str__(self):
return '<' + self.name + ',' + str(self.value) + ',' + str(self.weight) + '>'
# 递归终止条件:没有剩余物品;背包没有剩余空间
def max_value_dp(bag_set, remain_room, memo={}):
# select from memory
if (len(bag_set), remain_room) in memo:
result = memo[(len(bag_set), remain_room)]
# leaf
elif bag_set == [] or remain_room == 0:
result = 0, ()
# only has the right tree
elif bag_set[0].get_weight() > remain_room:
result = max_value_dp(bag_set[1:], remain_room)
# select max value from left and right tree
else:
next_item = bag_set[0]
left_value, left_taken = max_value_dp(bag_set[1:], remain_room - next_item.get_weight())
left_value += next_item.get_value()
right_value, right_taken = max_value_dp(bag_set[1:], remain_room)
# 获得最优子结构
if left_value > right_value:
result = left_value, left_taken + (next_item,)
else:
result = right_value, right_taken
memo[(len(bag_set), remain_room)] = result
return result
def built_item():
names = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
values = [35, 30, 6, 50, 40, 10, 25]
weights = [10, 40, 30, 50, 35, 40, 30]
Items = []
for i in range(len(names)):
Items.append(Item(names[i], values[i], weights[i]))
return Items
if __name__ == '__main__':
start = time.perf_counter()
items = built_item()
max_value, taken = max_value_dp(items, 150)
print('Total value of items taken = ', max_value)
print('the items of bag is: ')
for item in taken:
print(item)
end = time.perf_counter()
print("runing time is %f" % (end - start))
运行结果:
Total value of items taken = 155.0
the items of bag is:
<E,40.0,35.0>
<D,50.0,50.0>
<B,30.0,40.0>
<A,35.0,10.0>
runing time is 0.000360
动态规划相对于普通递归没有太大提升,甚至有时候不一定会快,这是因为数据量较小,基本发挥不出缓存的作用,当数据量比较大时,这个时间的节省就比较可观了。
1) 动态规划为什么会快?
因为不需要调用函数计算重复子问题。而且当问题的数据量大时,对时间的节省比较明显。
2)动态规划的核心:
核心在于memory的设计,这里我们利用了memo[(len(oraSet),leftRoom)]中的(len(oraSet),leftRoom)字典作为键,为什么可以利用len(oraSet)而不是oraSet呢(当然oraSet也是可以的)?这是因为对于每一层的子节点来说,剩余物品的个数都是一致的,这个个数可以区分重复子问题。而动态规划相较于普通的递归算法,主要的就是增加了memory。
3)如何设计动态规划算法:
首先看问题是否满足动态规划的两个条件:重复子问题,最优子结构;
然后利用递归算法解决问题,设计memory,然后修改递归算法的实现,加入memory,最终实现动态规划的算法。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









