








TL; DR:使用TensorFlow作为数据流程序的分布式计算框架,我们通过联网实现了SPDZ协议的全面实施,从而实现了对加密数据的优化机器学习。
与之前我们关注安全计算背后的概念以及潜在的应用程序不同 ,我们在这里构建了一个完全正常工作(被动安全)的实现,其中运行在不同机器上的玩家以及通过典型网络堆栈进行通信。 作为其中的一部分,我们研究了在实验安全计算时使用现代分布式计算平台的好处,而不是从头开始构建一切。
此外,这也可以看作是将私人机器学习掌握在从业者手中的一个步骤,与TensorFlow等现有和流行工具的集成起着重要作用。 具体而言,虽然我们这里只做了一个相对较浅的集成,但没有使用TensorFlow附带的一些强大的工具(例如自动分化 ),但我们确实展示了如何克服基本的技术障碍,为更深入的研究铺平道路集成。
向前看,回想起来,TensorFlow是一个明显的候选框架,可以快速尝试安全计算协议,至少在私人机器学习的背景下。
所有代码都可以在本地或在Google Cloud上使用 。 为了简单起见,我们运行的示例始终是使用逻辑 回归的私人预测,这意味着给定一个私有的(即加密的)输入x我们希望安全地为私有但预先训练的权重计算sigmoid(dot(w, x) + b) w和偏见b ( w和b私人培训被视为后续职位)。 实验表明,对于具有100个特征的模型,这可以在TensorFlow中完成,延迟低至60ms,速率高达每秒20,000个预测。
非常感谢Andrew Trask , Kory Mathewson , Jan Leike和OpenMined社区为这个主题提供灵感和有趣的讨论!
免责声明 :此实现仅适用于实验,可能无法达到所需的安全性。 特别是,TensorFlow目前似乎并没有考虑到这个应用程序的设计,虽然现在看起来并非如此,但是例如在未来的版本中,可能会在该场景后面执行优化来打破预期的安全属性。 下面更多注释 。
动机
正如上文所暗示的那样,实施安全计算协议(如SPDZ )由于其分布式性质是一项不平凡的任务,只有在我们开始引入各种优化( 但 可以 完成 )时才会变得更糟。 例如,必须考虑如何最好地协调多个程序的同时执行,如何最小化跨网络发送数据的开销,以及如何有效地将其与计算交错,以便一台服务器很少在另一台服务器上等待。最重要的是,我们可能还想支持不同的硬件平台,包括CPU和GPU等,并且对于任何认真的工作来说,使用可视化检查,调试和分析工具来识别问题和瓶颈是非常有价值的。
此外,还应该很容易地尝试各种优化,例如改进计算以提高性能, 重新使用中间结果和屏蔽值 ,以及在执行期间以三元组形式提供新鲜的“原材料”,而不是仅生成大批量提前在离线阶段。 获得所有这一切都是正确的,这是以前的博客文章集中在安全计算协议背后的原理并简单地在本地完成的一个原因。
幸运的是,现代分布式计算框架,如TensorFlow ,由于其在大型数据集上的高级机器学习中的使用, 近来正在接受大量研究和工程关注。 由于我们的重点是私人机器学习,所以存在一个自然的大的基本重叠。 特别是,我们感兴趣的安全操作是张量加法,减法,乘法,点积,截断和采样,它们在TensorFlow中都具有不安全但高度优化的对应物。
先决条件
我们假设TensorFlow和SPDZ协议背后的主要原理已经被理解了 - 如果不是这样的话,前者(包括白皮书 )和后者的前期 博客 文章都有很多 优秀的 资源 。 至于涉及到的不同方面,我们在这里也假定有两个服务器,一个加密生产者,一个输入提供者和一个输出接收者。
但是一个重要的注意事项是TensorFlow的工作原理是首先构造一个随后在会话中执行的静态计算图 。 例如,检查我们从TensorBoard中的sigmoid(dot(w, x) + b)得到的图表显示如下。
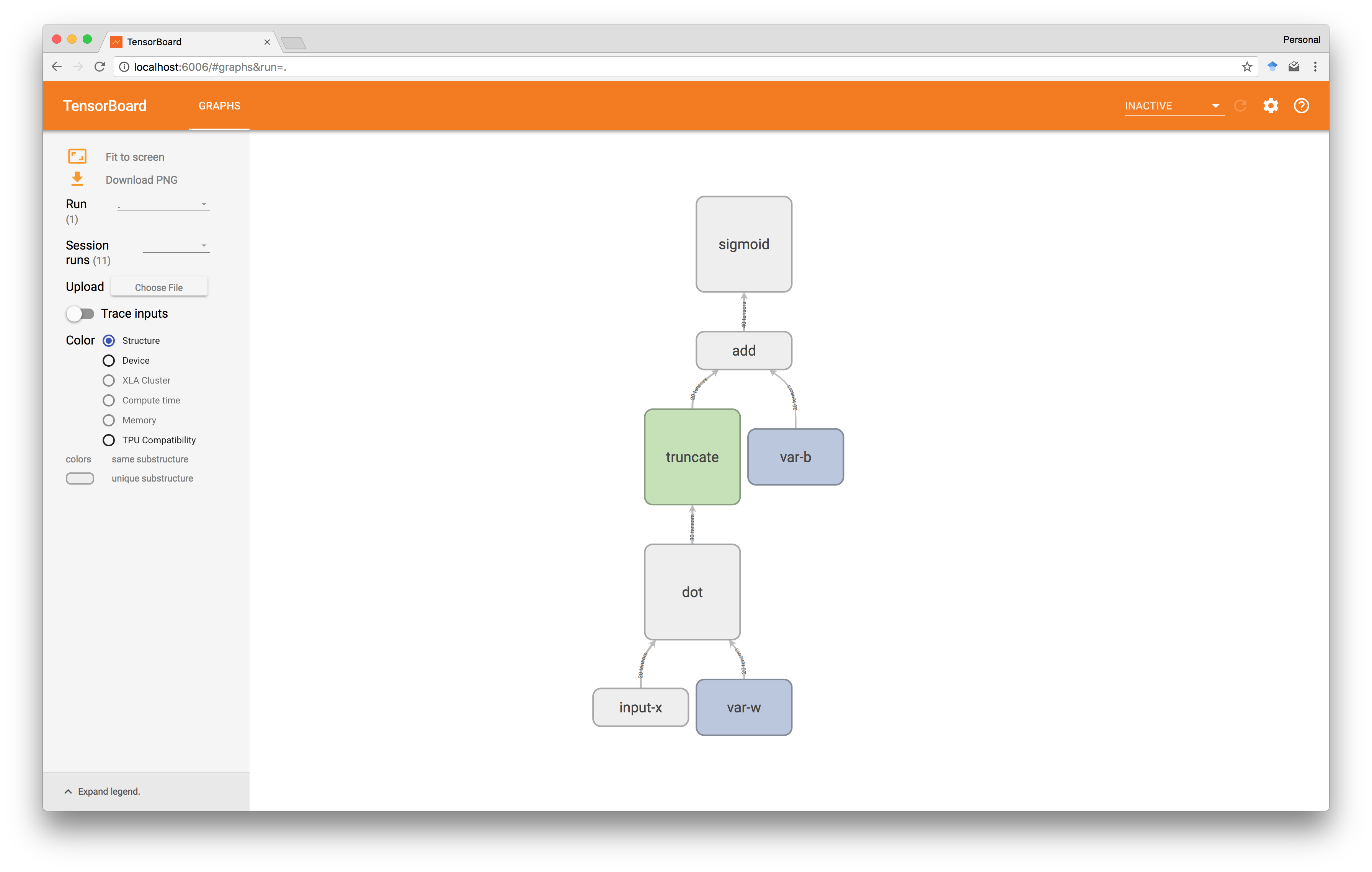
这意味着我们在这篇文章中的努力关注于构建这样一个图表,而不是像之前的实际执行:我们在某种程度上制作了一个小型编译器,将用简单语言表达的安全计算转换为TensorFlow程序。 因此,我们不仅可以从更高层次的抽象中受益,而且可以从TensorFlow中已经进入优化图形执行的大量工作中受益。
查看完整代码示例的实验 。
基本
我们的需求与TensorFlow已经提供的操作很好地吻合,如下所示,除了一个主要的例外:当在安全设置中处理固定点数字时,为了匹配浮点数的典型精度,我们最终编码并操作整数大于32或64位的典型字长,但今天这些是TensorFlow提供操作的唯一尺寸(与当前GPU支持有关的限制)。
幸运的是,对于我们需要的操作,有效的方法可以让我们模拟使用一组具有相同形状但是例如32位整数的张量列表对〜120位整数的张量进行算术运算。 此外,这种分解还具有我们可以独立地对列表中的每个张量进行操作的好特性,因此除了启用TensorFlow之外,这还允许大多数操作并行执行,并且实际上可以提高效率尽管它听起来可能听起来更加昂贵,但它的数量更大。
我们在其他地方讨论这个细节 ,并在本文的其余部分简单地假定在张量列表上执行预期操作的操作crt_add , crt_sub , crt_mul , crt_dot , crt_mod和sample。 请注意, crt_mod , crt_mul和crt_sub一起允许我们为定点截断定义右移操作。
私人张量
每个私人张量由两台服务器决定。 由于上面提到的原因,每个份额都由张量列表给出,这些张量由图中的节点列表表示。 为了隐藏这种复杂性,我们引入一个简单的类如下。
class PrivateTensor : def __init__ ( self , share0 , share1 ): self . share0 = share0 self . share1 = share1 @property def shape ( self ): return self . share0 [ 0 ] . shape @property def unwrapped ( self ): return self . share0 , self . share1
并且感谢TensorFlow,我们可以在图形创建时知道张量的形状,这意味着我们不必自己跟踪这些。
简单的操作
由于安全操作通常会用几个TensorFlow操作来表示,因此我们使用抽象操作(如add, mul和dot作为构造计算图的便捷方式。 第一个是add ,其中结果图简单地指示两台服务器在本地合并它们各自使用由crt_add构建的子图的crt_add 。
def add ( x , y ): assert isinstance ( x , PrivateTensor ) assert isinstance ( y , PrivateTensor ) x0 , x1 = x . unwrapped y0 , y1 = y . unwrapped with tf . name_scope ( 'add' ): with tf . device ( SERVER_0 ): z0 = crt_add ( x0 , y0 ) with tf . device ( SERVER_1 ): z1 = crt_add ( x1 , y1 ) z = PrivateTensor ( z0 , z1 ) return z
注意使用tf.device()来表示哪个服务器正在做什么很容易! 该命令将计算及其结果值绑定到指定主机,并指示TensorFlow自动插入适当的网络操作,以确保输入值在需要时可用!
例如,在上面的例子中,如果x0先前是输入提供者,那么TensorFlow将插入发送和接收指令,将SERVER_0作为计算add一部分复制到SERVER_0 。 所有这些都被抽象出来,框架将尝试找出最佳策略,以便准确优化何时执行发送和接收,包括批量更好地利用网络并保持计算单元繁忙。
另一方面, tf.name_scope()命令仅仅是一个逻辑抽象,它不会影响计算,但可用于通过将子图组合为单个组件来使图更容易在TensorBoard中可视化,如前所述。
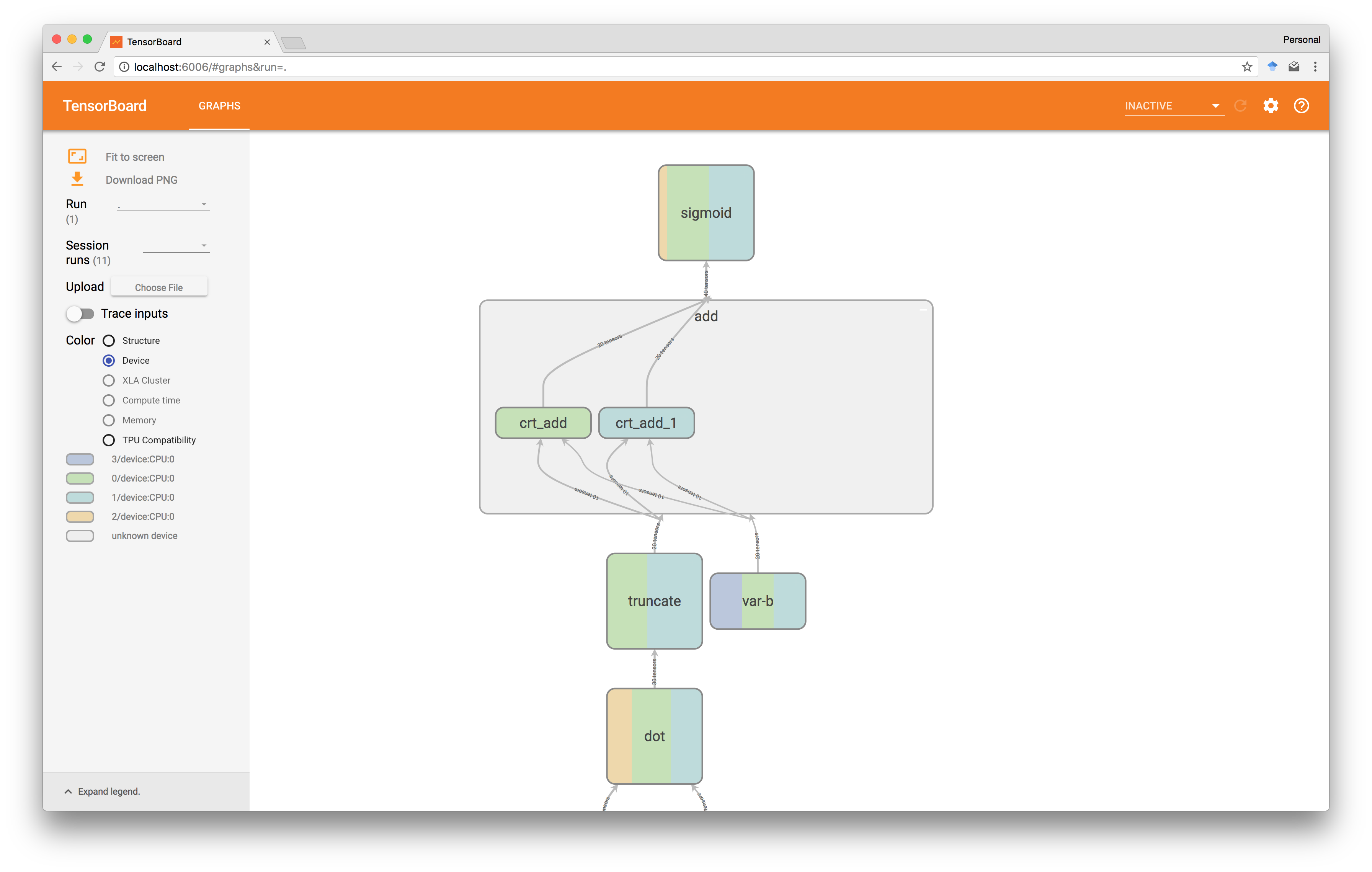
请注意,如上所述,选择TensorBoard中的Device coloring,我们也可以使用它来验证操作实际计算的位置,在这种情况下,添加确实是由两台服务器在本地完成的(绿色和绿松石)。
点产品
接下来我们转向点产品。 这是比较复杂的,至少因为我们现在需要涉及加密生产者,还因为两个服务器必须相互通信作为计算的一部分。
def dot ( x , y ): assert isinstance ( x , PrivateTensor ) assert isinstance ( y , PrivateTensor ) x0 , x1 = x . unwrapped y0 , y1 = y . unwrapped with tf . name_scope ( 'dot' ): # triple generation with tf . device ( CRYPTO_PRODUCER ): a = sample ( x . shape ) b = sample ( y . shape ) ab = crt_dot ( a , b ) a0 , a1 = share ( a ) b0 , b1 = share ( b ) ab0 , ab1 = share ( ab ) # masking after distributing the triple with tf . device ( SERVER_0 ): alpha0 = crt_sub ( x0 , a0 ) beta0 = crt_sub ( y0 , b0 ) with tf . device ( SERVER_1 ): alpha1 = crt_sub ( x1 , a1 ) beta1 = crt_sub ( y1 , b1 ) # recombination after exchanging alphas and betas with tf . device ( SERVER_0 ): alpha = reconstruct ( alpha0 , alpha1 ) beta = reconstruct ( beta0 , beta1 ) z0 = crt_add ( ab0 , crt_add ( crt_dot ( a0 , beta ), crt_add ( crt_dot ( alpha , b0 ), crt_dot ( alpha , beta )))) with tf . device ( SERVER_1 ): alpha = reconstruct ( alpha0 , alpha1 ) beta = reconstruct ( beta0 , beta1 ) z1 = crt_add ( ab1 , crt_add ( crt_dot ( a1 , beta ), crt_dot ( alpha , b1 ))) z = PrivateTensor ( z0 , z1 ) z = truncate ( z ) return z
但是,通过tf.device()我们发现这仍然是相对直接的,至少如果安全点产品的协议已经被理解了。 我们首先构造一个图形,使加密生成器生成一个新的点三元组。 该图的输出节点是a0, a1, b0, b1, ab0, ab1
随着crt_sub我们然后分别为使用a和b屏蔽x和y的两台服务器构建图。 TensorFlow将再次SERVER_0在执行期间插入将例如a0的值发送到SERVER_0网络代码。
在第三步中,我们在每台服务器上重建alpha和beta ,并计算重组步骤以获得点积。 请注意,我们必须为每个服务器定义alpha和beta两次,因为虽然它们包含相同的值,但如果我们只在一台服务器上定义它们,但在两台服务器上都使用它们,那么我们会隐式插入其他网络操作,因此减慢了计算速度。
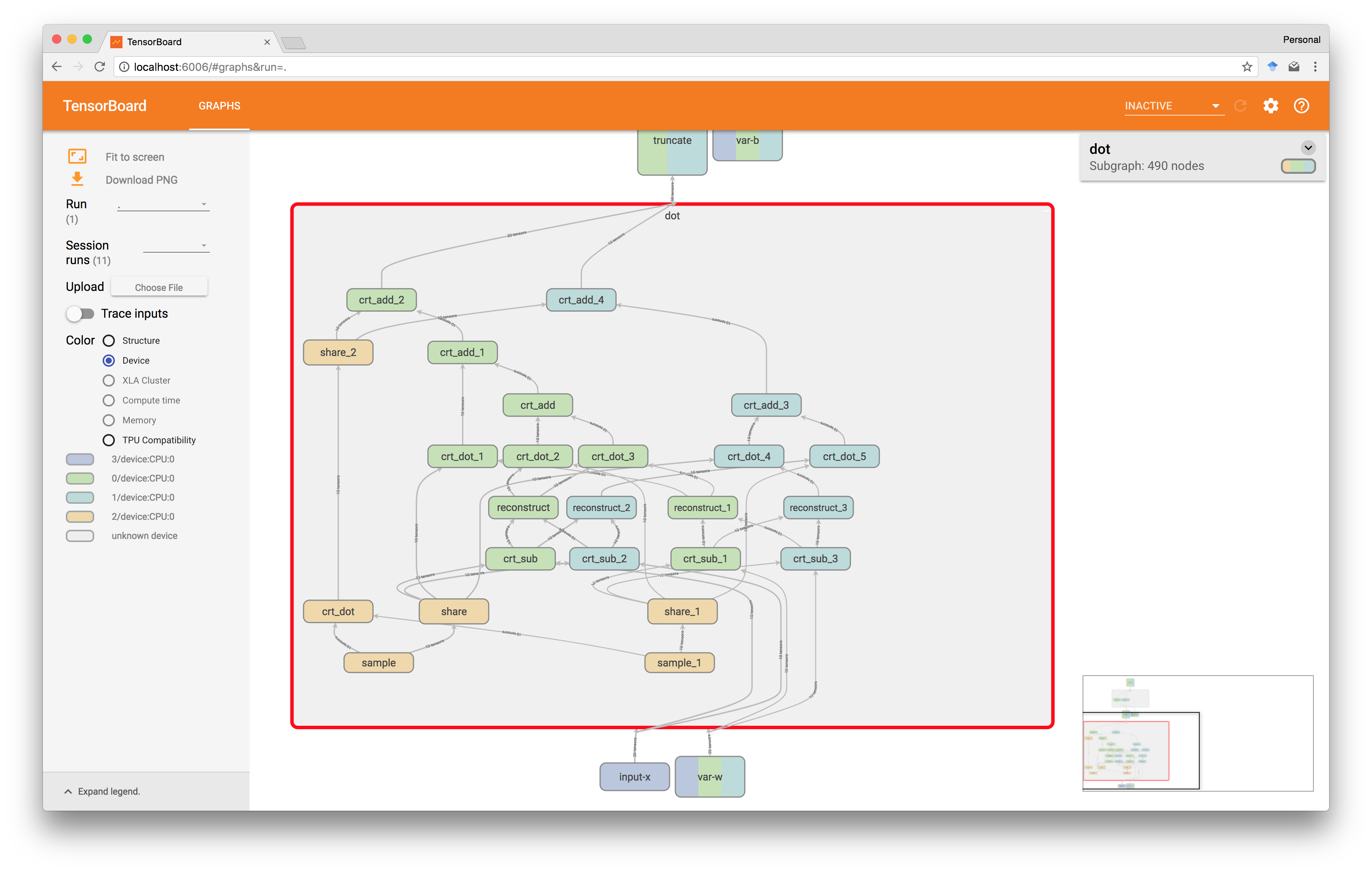
回到TensorBoard,我们可以验证节点确实与正确的玩家绑定在一起,黄色是加密制作者,绿色和绿松石是两个服务器。 注意这里有tf.name_scope()的方便。
组态
为了充分声明这使得安全计算的分布式方面更容易表达,我们还必须看到td.device()实际上需要什么才能按预期工作。 在下面的代码中,我们首先定义一个任意的作业名称,后面跟着我们五个玩家的标识符 更有意思的是,我们只需指定他们的网络主机并将其包装在ClusterSpec 。 而已!
JOB_NAME = 'spdz' SERVER_0 = '/job:{}/task:0' . format ( JOB_NAME ) SERVER_1 = '/job:{}/task:1' . format ( JOB_NAME ) CRYPTO_PRODUCER = '/job:{}/task:2' . format ( JOB_NAME ) INPUT_PROVIDER = '/job:{}/task:3' . format ( JOB_NAME ) OUTPUT_RECEIVER = '/job:{}/task:4' . format ( JOB_NAME ) HOSTS = [ '10.132.0.4:4440' , '10.132.0.5:4441' , '10.132.0.6:4442' , '10.132.0.7:4443' , '10.132.0.8:4444' , ] CLUSTER = tf . train . ClusterSpec ({ JOB_NAME : HOSTS })
请注意,在截图中,我们实际上是在同一主机上运行输入提供者和输出接收者,因此都显示为3/device:CPU:0 。
最后,每个玩家执行的代码都是如此简单。
server = tf . train . Server ( CLUSTER , job_name = JOB_NAME , task_index = ROLE ) server . start () server . join ()
这里ROLE的值是五个玩家运行的程序之间唯一不同的东西,通常作为命令行参数给出。
改进
随着基础知识的到位,我们可以看一些优化。
跟踪节点
我们的第一个改进允许我们重复使用计算。 例如,如果我们需要两次dot(x, y)的结果,那么我们希望避免第二次计算它,而是重新使用第一次。 具体而言,我们希望跟踪图中的节点并尽可能地链接到它们。
为此,我们只需在构建图时维护一个全局的PrivateTensor引用字典,并在添加新节点之前使用它查找已经存在的结果。 例如, dot现在变成如下。
def dot ( x , y ): assert isinstance ( x , PrivateTensor ) assert isinstance ( y , PrivateTensor ) node_key = ( 'dot' , x , y ) z = nodes . get ( node_key , None ) if z is None : # ... as before ... z = PrivateTensor ( z0 , z1 ) z = truncate ( z ) nodes [ node_key ] = z return z
虽然对于某些应用来说已经很重要,但是这一改变也为我们的下一个改进打开了。
重新使用蒙版张量
我们已经 提到过 ,我们最好想要掩盖每个私人张量最多一次,主要是为了节省网络。 例如,如果我们计算dot(w, x)和dot(w, y)那么我们希望在两者中都使用相同的w掩码版本。 具体而言,如果我们使用相同的掩蔽张量进行多项操作,那么掩盖它的成本可以分摊。
但是就目前的设置而言,我们每次计算时都会掩盖,例如dot或多dot ,因为掩模会被烧入这些点。 所以为了避免这种情况,我们只是简单地做一个明确的操作,另外还允许我们在不同的操作中使用相同的屏蔽版本。
def mask ( x ): assert isinstance ( x , PrivateTensor ) node_key = ( 'mask' , x ) masked = nodes . get ( node_key , None ) if masked is None : x0 , x1 = x . unwrapped shape = x . shape with tf . name_scope ( 'mask' ): with tf . device ( CRYPTO_PRODUCER ): a = sample ( shape ) a0 , a1 = share ( a ) with tf . device ( SERVER_0 ): alpha0 = crt_sub ( x0 , a0 ) with tf . device ( SERVER_1 ): alpha1 = crt_sub ( x1 , a1 ) # exchange of alphas with tf . device ( SERVER_0 ): alpha_on_0 = reconstruct ( alpha0 , alpha1 ) with tf . device ( SERVER_1 ): alpha_on_1 = reconstruct ( alpha0 , alpha1 ) masked = MaskedPrivateTensor ( a , a0 , a1 , alpha_on_0 , alpha_on_1 ) nodes [ node_key ] = masked return masked
请注意,我们引入了一个MaskedPrivateTensor类作为其中的一部分,这也是对从mask(x)得到的五个张量列表进行抽象的简便方法。
class MaskedPrivateTensor ( object ): def __init__ ( self , a , a0 , a1 , alpha_on_0 , alpha_on_1 ): self . a = a self . a0 = a0 self . a1 = a1 self . alpha_on_0 = alpha_on_0 self . alpha_on_1 = alpha_on_1 @property def shape ( self ): return self . a [ 0 ] . shape @property def unwrapped ( self ): return self . a , self . a0 , self . a1 , self . alpha_on_0 , self . alpha_on_1
有了这个,我们可以像下面这样重写dot ,它现在只负责重组步骤。
def dot ( x , y ): assert isinstance ( x , PrivateTensor ) or isinstance ( x , MaskedPrivateTensor ) assert isinstance ( y , PrivateTensor ) or isinstance ( y , MaskedPrivateTensor ) node_key = ( 'dot' , x , y ) z = nodes . get ( node_key , None ) if z is None : if isinstance ( x , PrivateTensor ): x = mask ( x ) if isinstance ( y , PrivateTensor ): y = mask ( y ) a , a0 , a1 , alpha_on_0 , alpha_on_1 = x . unwrapped b , b0 , b1 , beta_on_0 , beta_on_1 = y . unwrapped with tf . name_scope ( 'dot' ): with tf . device ( CRYPTO_PRODUCER ): ab = crt_dot ( a , b ) ab0 , ab1 = share ( ab ) with tf . device ( SERVER_0 ): alpha = alpha_on_0 beta = beta_on_0 z0 = crt_add ( ab0 , crt_add ( crt_dot ( a0 , beta ), crt_add ( crt_dot ( alpha , b0 ), crt_dot ( alpha , beta )))) with tf . device ( SERVER_1 ): alpha = alpha_on_1 beta = beta_on_1 z1 = crt_add ( ab1 , crt_add ( crt_dot ( a1 , beta ), crt_dot ( alpha , b1 ))) z = PrivateTensor ( z0 , z1 ) z = truncate ( z ) nodes [ node_key ] = z return z
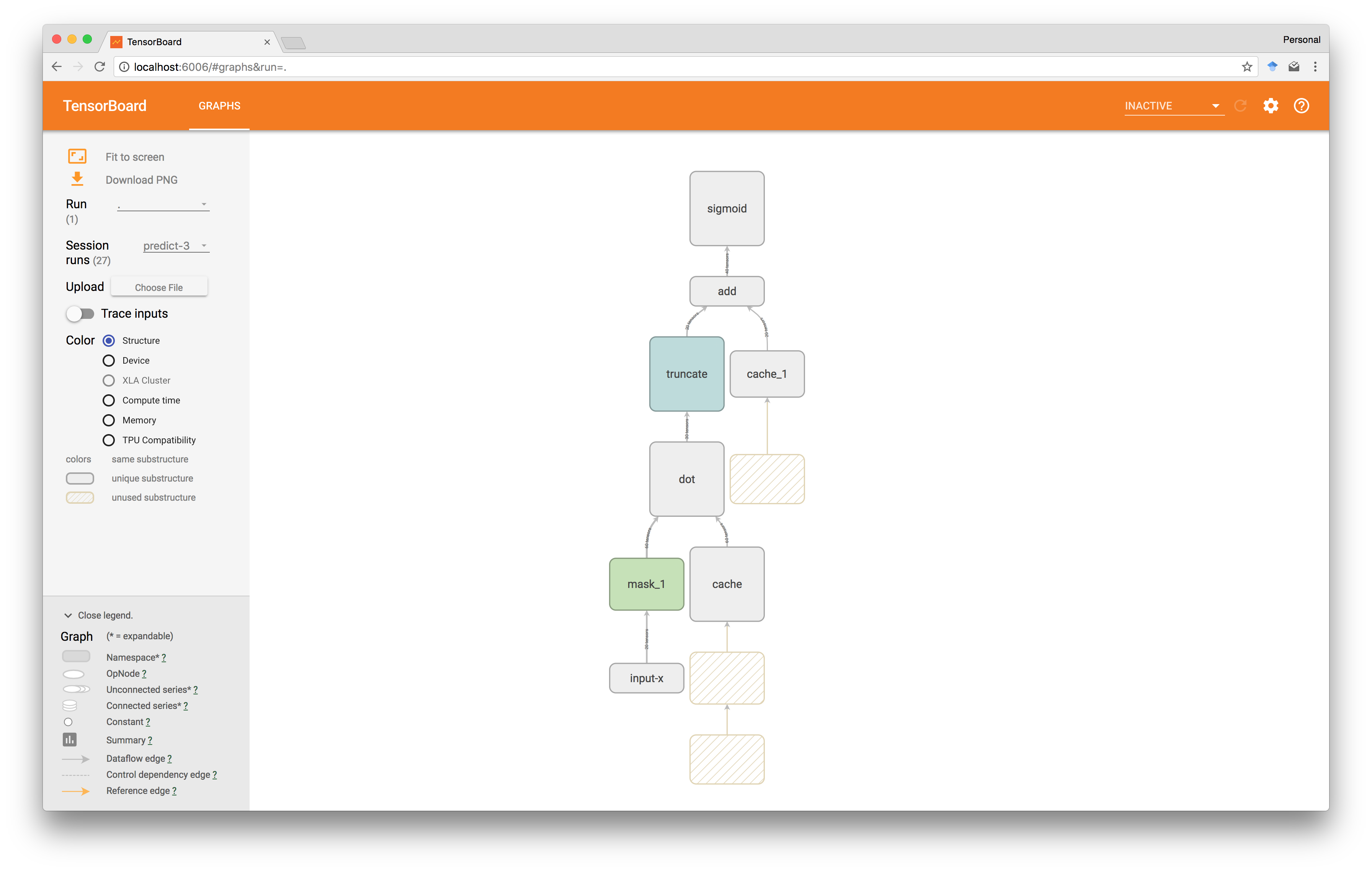
作为验证,我们可以看到TensorBoard向我们展示了预期的图结构,在这种情况下,在sigmoid图中。
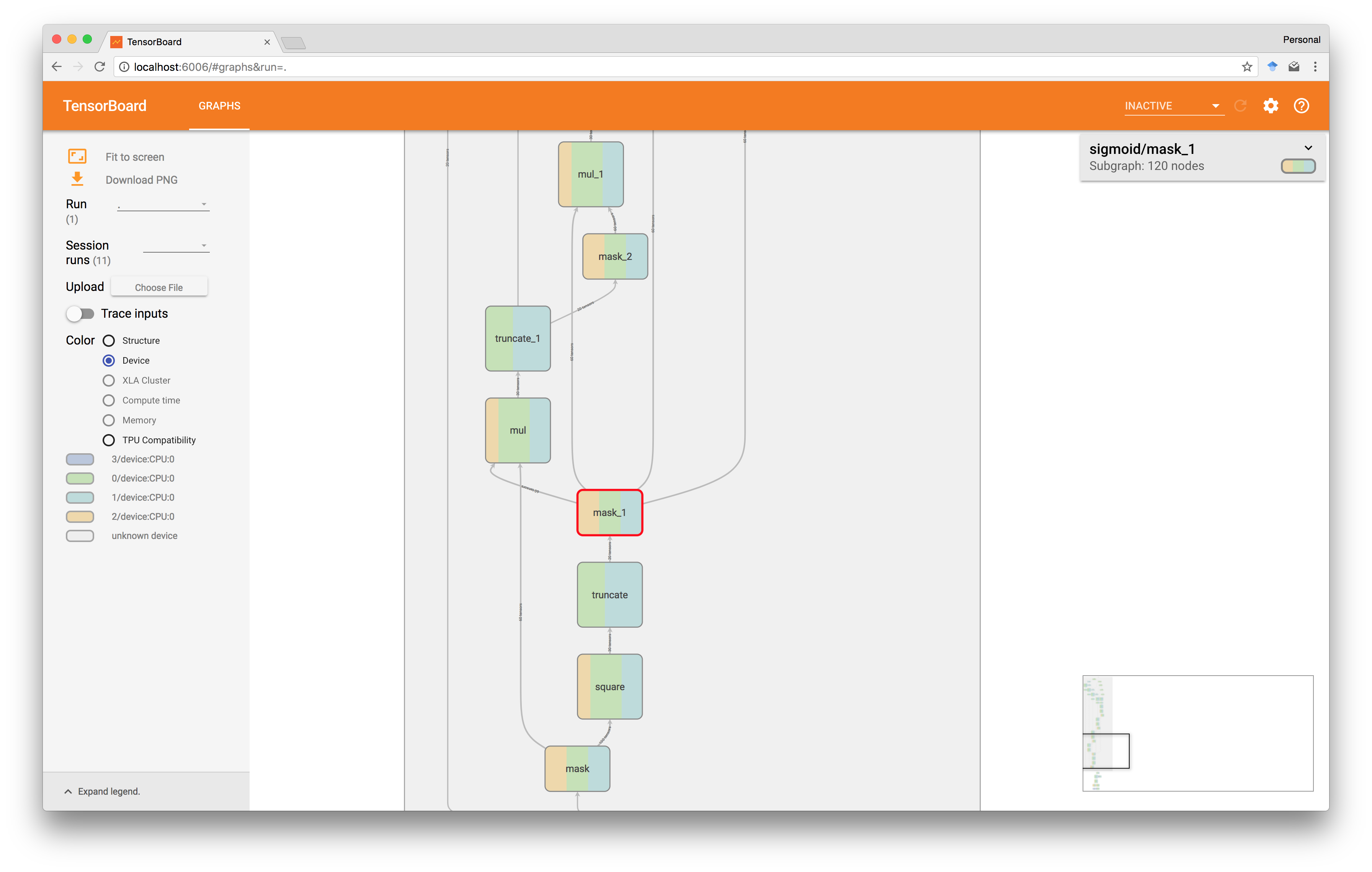
这里square(x)值首先被计算出来,然后被屏蔽,最后被重复使用四次。
虽然效率低下,但TensorFlow的数据流性质一般只会重新计算图表中在两次执行之间发生变化的部分,但这不适用于涉及通过例如tf.random_uniform进行采样的操作,该操作用于我们的分享和掩饰。 因此,掩码不会在执行过程中重复使用。
缓存值
为了解决上述问题,我们可以引入在图的不同执行过程中存活的值的缓存,并且一个简单的方法是将张量存储在变量中 。 正常执行将从这些读取,而明确的cache_populators操作集允许我们填充它们。
例如,用这种cache操作包装我们的两张张量w和b可以得到下面的图。
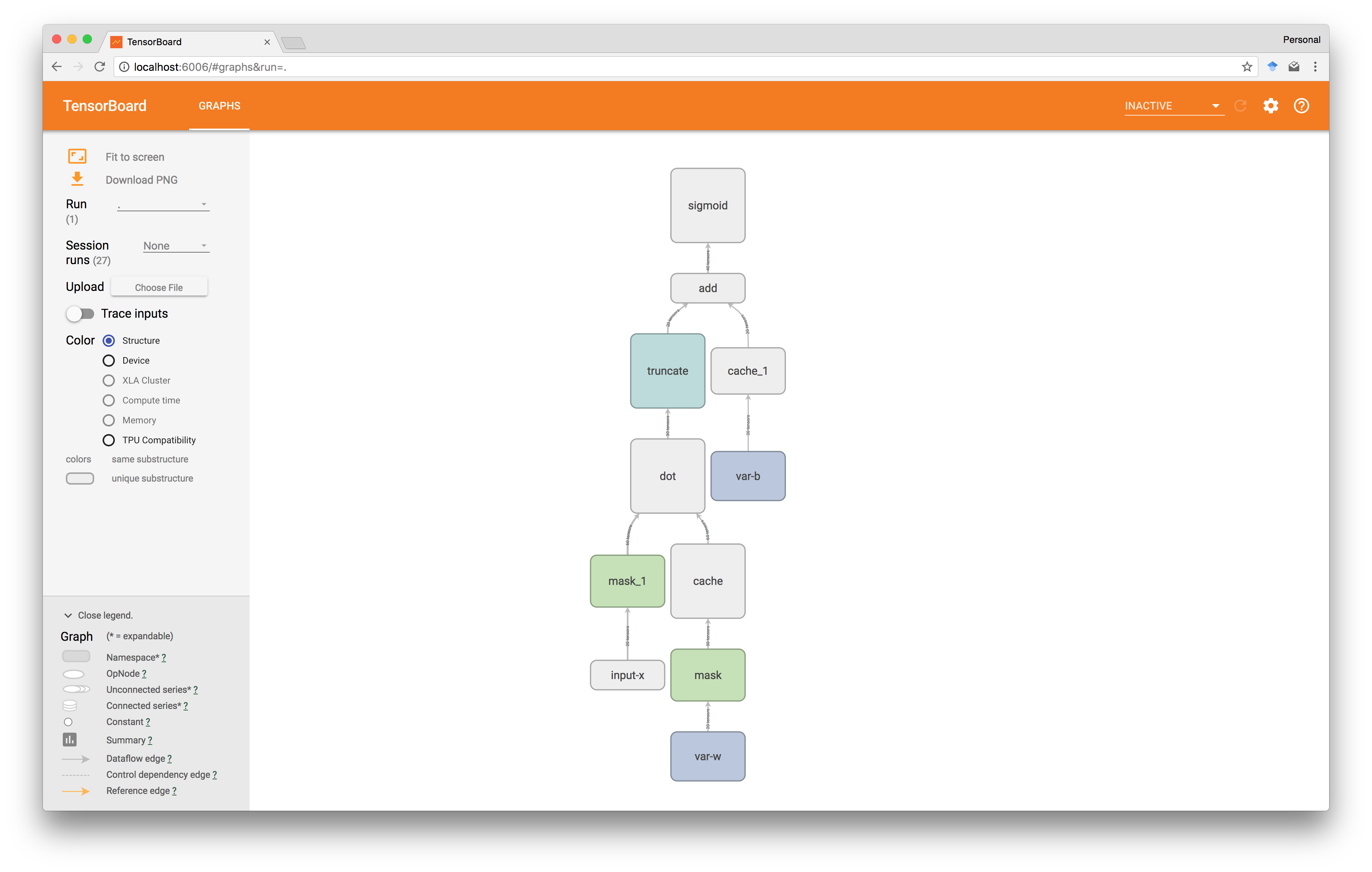
执行缓存填充操作时,TensorFlow会自动计算出需要执行的图的哪些子部分以生成要缓存的值,哪些可以忽略。
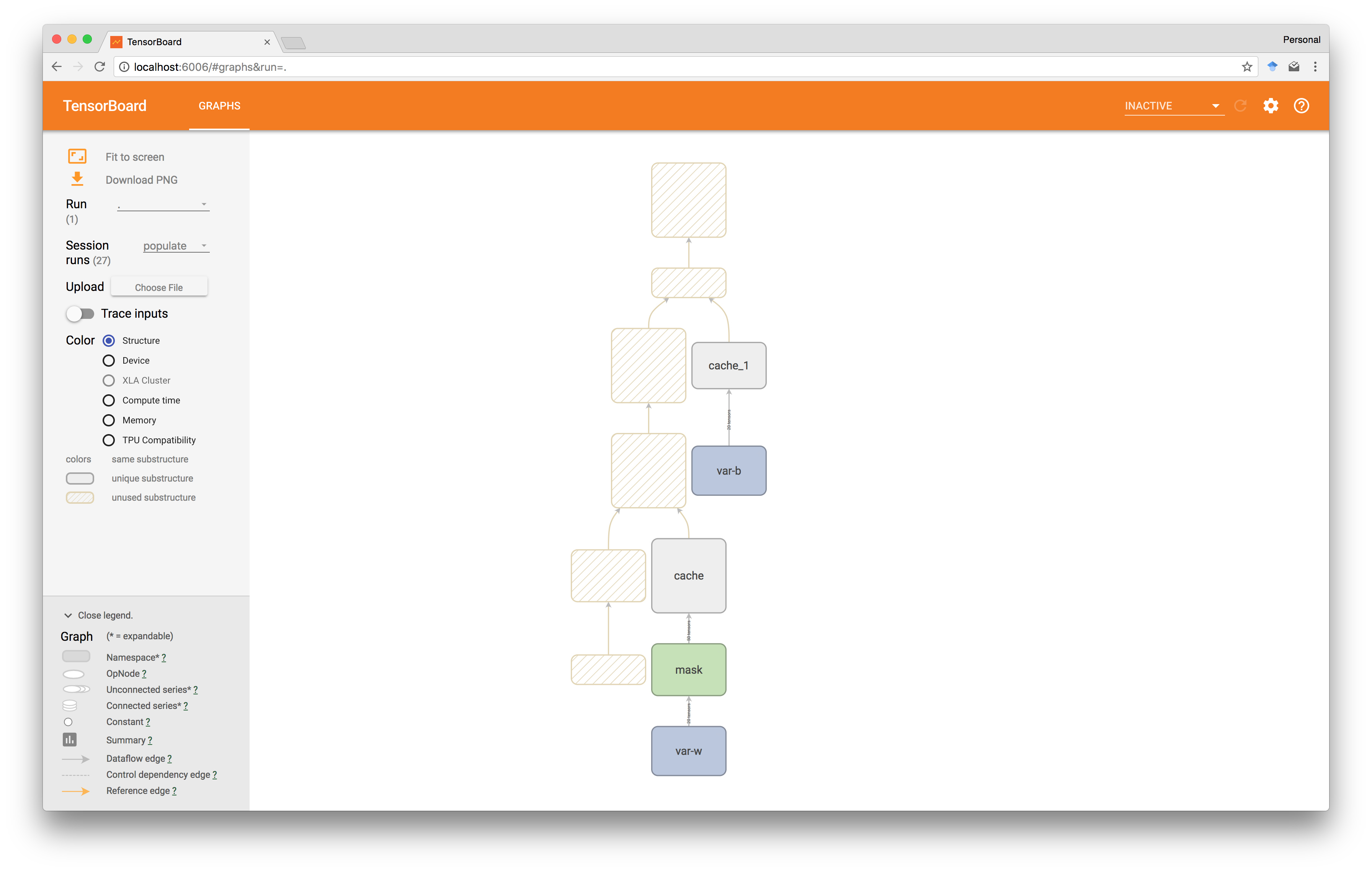
同样,在预测时,在这种情况下跳过共享和屏蔽。
缓冲三元组
回想一下, 三元组的主要目的是将加密生产者的计算转移到离线阶段,并提前将其结果分发给两个服务器,以便稍后在在线阶段加快计算速度。
到目前为止,我们还没有做过任何事情来指定这会发生,但通过阅读上述代码,假设加密生产者将与两台服务器同步计算,在其计算过程中注入空闲等待时间并非不合理。 然而,从实验看来,TensorFlow似乎已经足够聪明,可以优化图形来做正确的事情和批量三重分配,这大概是为了节省网络。 尽管我们仍然有一个初始等待期,但我们可以通过引入一个单独的计算和分配执行来填补缓冲区,从而摆脱困境。
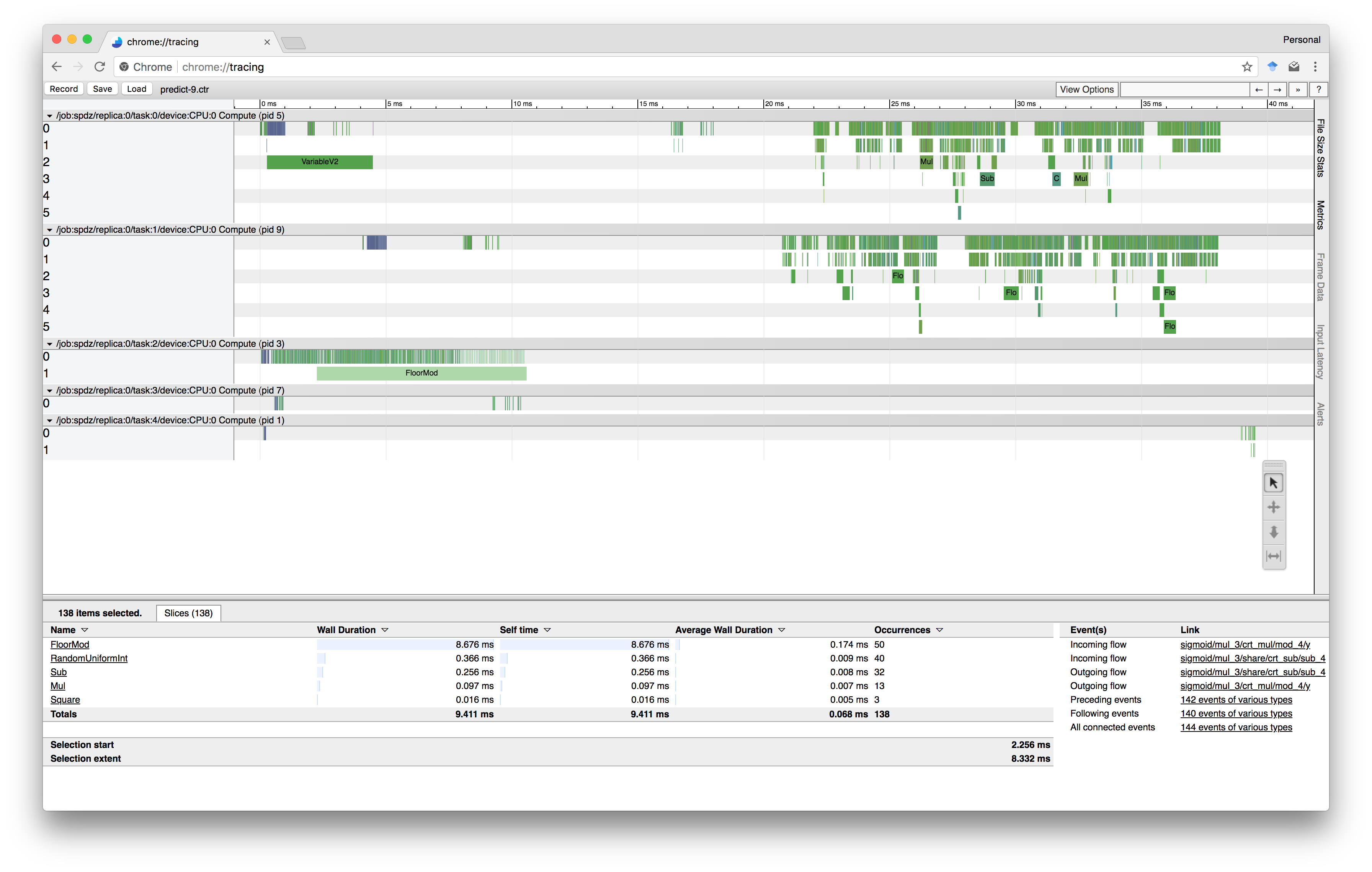
我们现在将跳过这个问题,而是在看私人培训时回到它,因为通过提前分发培训数据来期待显着的性能改进并不是不合理的。
剖析
作为在TensorFlow中构建数据流程序感到兴奋的最后一个理由,我们还会查看内置的运行时统计信息 。 我们已经在上面看到了内置的详细跟踪支持,但在TensorBoard中我们也可以很容易地看到每个操作在计算和内存方面的成本。 这里报告的数字来自下面的实验 。
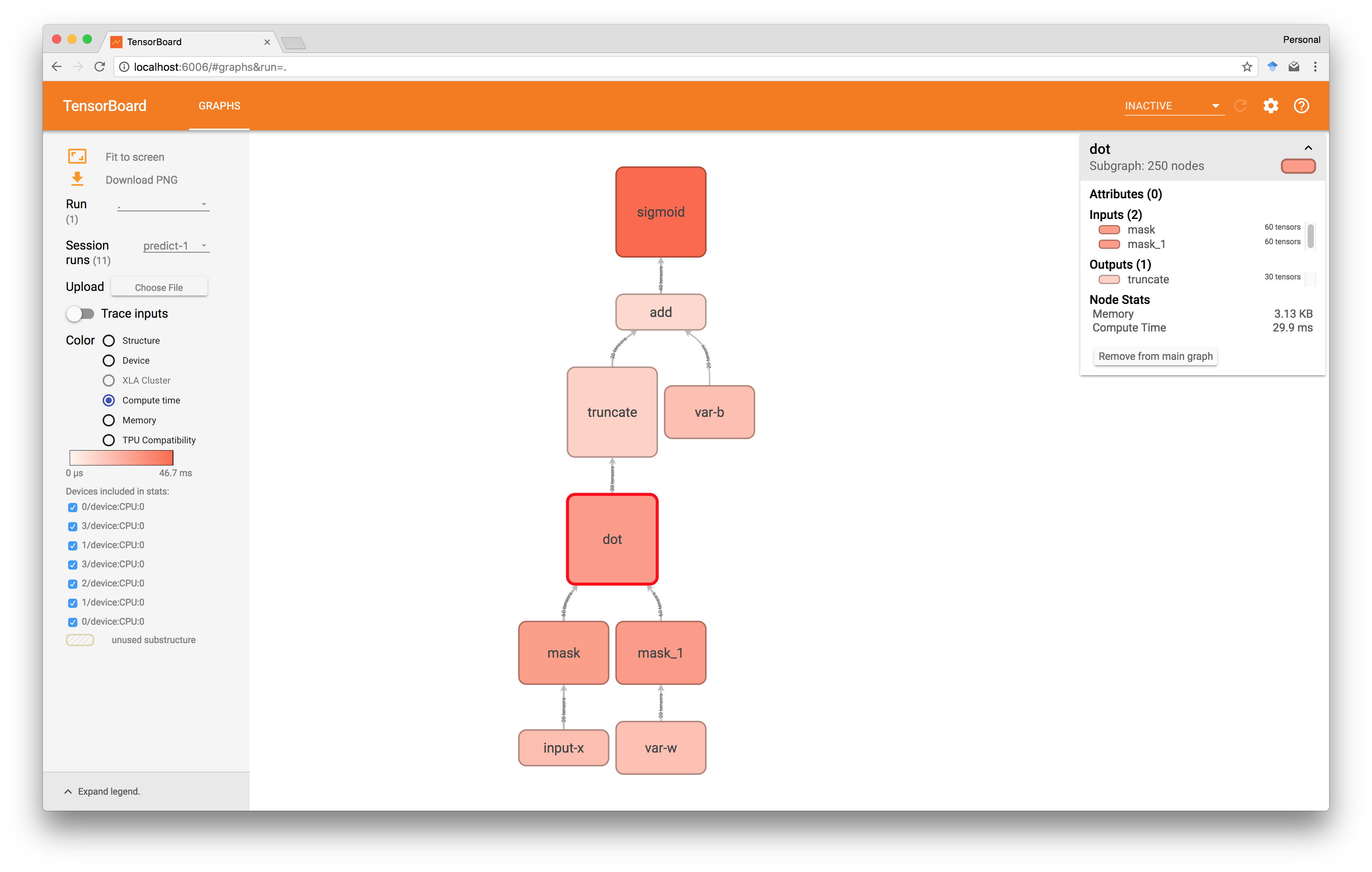
上面的热图表明, sigmoid是运行中最昂贵的操作,dot产品需要大约30ms才能执行。 此外,在下图中,我们已经进一步导航到点块,并看到在这个特定运行中共享大约3ms。
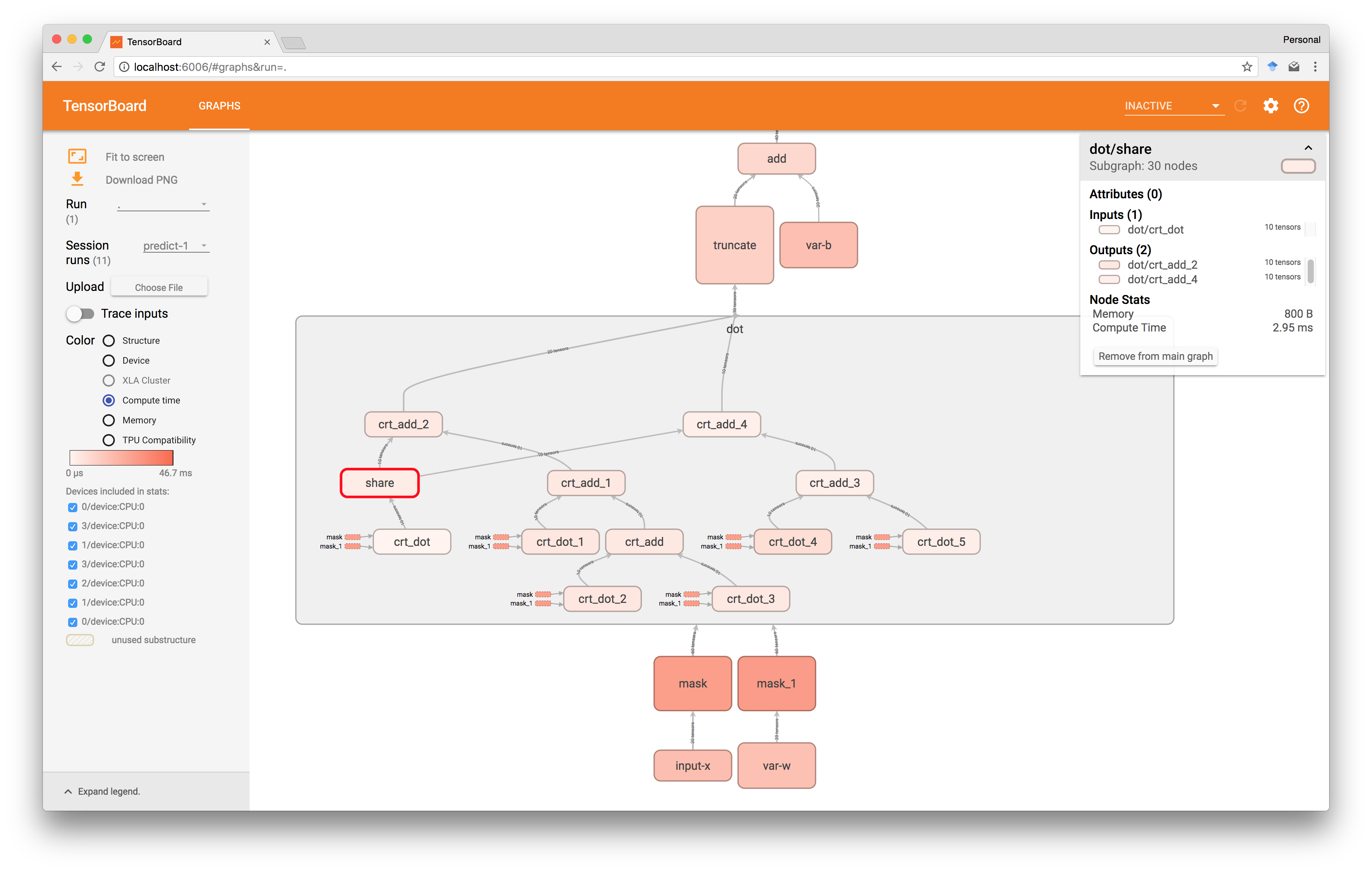
通过这种方式,我们可以识别瓶颈并比较不同方法的性能。 如果需要,我们当然可以切换到追踪更多细节。
实验
GitHub存储库包含实验所需的代码,包括用于设置主机的本地配置或GCP配置的示例和说明。 对于使用逻辑回归模型的私人预测的运行示例,我们使用GCP配置,即各方在位于同一Google Cloud区域的不同虚拟主机上运行,这里是一些较弱的实例,即双核和10 GB内存。
我们的程序的一个稍微简化的版本如下,我们首先公开训练一个模型,为私人预测计算建立一个图形,然后在新的会话中运行它。 该模型有点随意挑选有100个功能。
from config import session from tensorspdz import ( define_input , define_variable , add , dot , sigmoid , cache , mask , encode_input , decode_output ) # publicly train `weights` and `bias` weights , bias = train_publicly () # define shape of unknown input shape_x = X . shape # construct graph for private prediction input_x , x = define_input ( shape_x , name = 'x' ) init_w , w = define_variable ( weights , name = 'w' ) init_b , b = define_variable ( bias , name = 'b' ) if use_caching : w = cache ( mask ( w )) b = cache ( b ) y = sigmoid ( add ( dot ( x , w ), b )) # start session between all players with session () as sess : # share and distribute `weights` and `bias` to the two servers sess . run ([ init_w , init_b ]) if use_caching : # compute and store cached values sess . run ( cache_populators ) # prepare to use `X` as private input for prediction feed_dict = encode_input ([ ( input_x , X ) ]) # run secure computation and reveal output y_pred = sess . run ( reveal ( y ), feed_dict = feed_dict ) print decode_output ( y_pred )
以不同的X大小运行这几次会给出下面的计时,整个计算被考虑在内,包括三次生成和分配; 有点令人惊讶的是,高速缓存屏蔽值之间没有真正的区别。

处理大小为1,10和100的批处理时间大致相同,平均约为60ms,这可能意味着由于网络而导致的更低延迟限制。 在1000时间跳到〜110ms,在10000到600ms之间,最后在100,000到5s之间。 因此,如果延迟比我们可以每秒执行〜1600次预测更重要,而如果更灵活,那么至少每秒至少20,000次。

然而,这只是测量分析报告的时间,实际执行时间会稍长一些; 希望TensorFlow tf.serving一些面向生产的工具(如tf.serving可以改进这一点。
思考
在私人预测之后,看私人训练当然也会很有趣。 缓存蒙面训练数据在这里可能更加相关,因为它在整个过程中保持固定。
模型的服务也可以改进,例如使用生产就绪的tf.serving ,可以避免很多当前的编排开销,以及具有可以安全地向公众公开的端点。
最后,在五方之间的沟通等方面还有安全方面的改进。 特别是,在当前版本的TensorFlow中,所有通信都是通过未加密和未经身份验证的gRPC连接进行的,这意味着原则上监听网络流量的人可以了解所有私有值。 由于对gRPC的支持已经存在,所以在TensorFlow中使用它可能会很简单,而且不会对性能产生重大影响。 同样,TensorFlow目前不会为tf.random_uniform使用强大的伪随机生成器,因此共享和屏蔽并不像它们可能的那样安全; 增加一个密码强的随机性操作可能是直截了当的,应该给出大致相同的性能。
https://mortendahl.github.io/2018/03/01/secure-computation-as-dataflow-programs/















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









