







上节我们讨论到解SVM问题最终演化为求下列带约束条件的问题:
minW(α)=12(∑i,j=1Nαiyiαjyjxi∗xj)−∑i=1Nαis.t.0≤αi≤C∑i=1Nαiyi=0
问题的解就是找到一组 αi=(α1,α2,...,αn) 使得W最小。
现在我们来看看最初的约束条件是什么样子的:
1−yi(Wxi+b)≤0
这是最初的一堆约束条件吧,现在有多少个约束条件就会有多少个 αi 。那么KKT条件的形成就是让
αi(1−yi(Wxi+b))=0
。
我们知道 αi≥0 ,而后面那个小于等于0,所以他们中间至少有一个为0(至于为什么要这么做,第一节讨论过)。再简单说说原因,假设现在的分类问题如下:
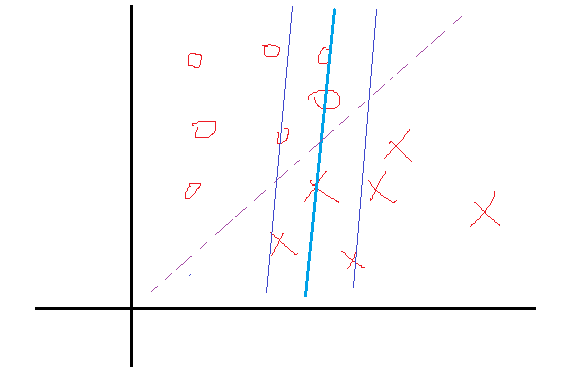
某一次迭代后,分类面为粗蓝线所示,上下距离为1的分界面如细蓝线所示,而理想的分界面如紫虚线所示。那么我们想想,要想把粗蓝线变化到紫虚线,在这一次是哪些个点在起作用?很显然是界于细蓝线边上以及它们之间的所有样本点在起作用吧,而对于那些在细蓝线之外的点,比如正类的四个圈和反类的三个叉,它们在这一次的分类中就已经分对了,那还考虑它们干什么?所以这一次就不用考虑这些分对了的点。那么我们用数学公式可以看到,对于在这一次就分对了的点,它们满足什么关系,显然 yi(Wxi+b)>1 ,然后还得满足 αi(1−yi(Wxi+b))=0 ,那么显然它们的 αi=0 。对于那些在边界内的点,显然 yi(Wxi+b)≤1 ,而这些点我们说是要为下一次达到更好的解做贡献的,那么我们就取这些约束条件的极限情况,也就是 yi(Wxi+b)=1 ,在这些极限约束条件下,我们就会得到一组新的权值W与b,也就是改善后的解。那么既然这些点的 yi(Wxi+b)=1 ,那它对应的 αi 就可以不为0了,至于是多少,那就看这些点具体属于分界面内的什么位置了,偏离的越狠的点,我想它对应的 αi 就越大,这样才能把这个偏得非常狠的点给拉回来,或者说使其在下一次的解中更靠近正确的分类面。
好了这就是KKT为什么要这么做的原因。那么整理一下,最终带松弛变量的KKT条件就如下所示:
(1)αi=0⇒yiui≥1(分对了)(2)0≤αi≤C⇒yiui=1(边界上,支持向量)(3)αi=C⇒yiui≤1(边界之间)
那么满足KKT条件的,我们说如果一个点满足KKT条件,那么它就不需要调整,一旦不满足,就需要调整。由上可知,不满足KKT条件的也有三种情况:
(1)yiui≤1但是αi<C(2)yiui≥1但是αi>0(3)yiui≤1但是αi=0或αi=C
这三种条件下的 α 都需要调整。那么怎么调整呢?比如说某一次迭代完后发现有10个点不满足,也就是有10个 α 需要调整,那么10个 α 在一起,你怎么知道去增加或者减少哪一个或者哪几个 α 呢?这个时候SMO采取的策略是选择这10个中的两个 α 出来,就假设为 α1,α2 吧,调整它们。看看前面有一个条件 ∑Ni=1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









