







在前两节曾经介绍过logistic回归与分类算法,并对线性与非线性数据集分别进行分类实验。Logistic采用的是一层向量权值求和的方式进行映射,所以本质上只能对线性分类问题效果较好(实验也可以看到),其模型如下所示(详细的介绍可看上两次博客:
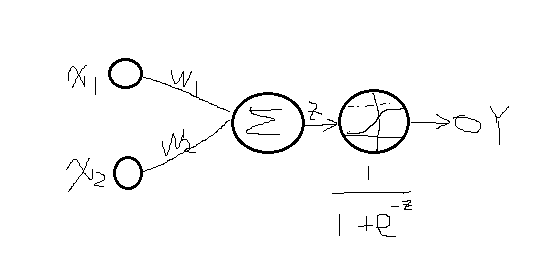
既然如此,我们可不可以在Y出来之前在多进行几次映射呢?答案是可以的,这就引出了多层网络,每层网络的输出后再进行sigmod映射到0-1之间,那么它就是神经网络系统了。比如上面的多加几层就可以表示为:
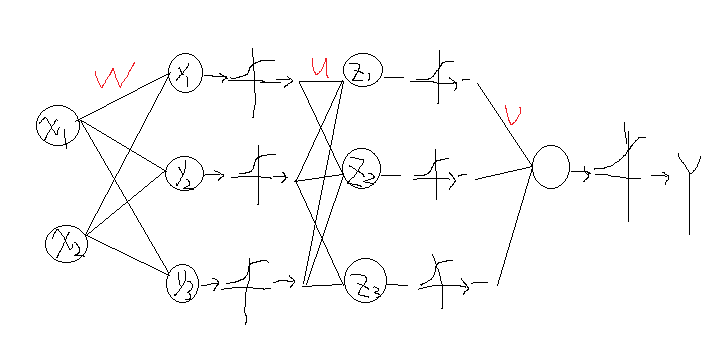
同样样本的输入从最左端开始,通过权值w矩阵计算得到第一层y值,得到的结果分别进行sigmod函数映射作为第二层的输入,然后经过权值矩阵u得到z,在进行映射,依次类推最终得到输出Y,那么这个多层网络和上面的单层相比有哪些不同?
首先可以看到最终输出Y和输入(x1,x2)已经不再是简单的权值相乘再映射了,而是权值相乘后映射,然后再权值相乘映射,再相乘映射最终得到Y,那么Y与(x1,x2)的关系在网络前后早已经不再是线性关系了,是什么关系,谁知道了。
可能会说,像这样的网络,为什么多加了两层?不是还可以继续增加吗?每层里面为什么是3个节点?不是还可以增加吗?没错,上述的层数以及每层的个数都可以增加,这就是神经网络的需要设计之处,每增加一层以及每层的节点数,网络的关系就会发生变化,至于变成什么样子,不用管,至于究竟用多少层多少个节点,那就看实际效果。这就涉及到神经网络的深层讨论范畴。
先说该网络,在一个网络确定后(什么叫确定?就是网络上的所有权值系数都知道)显然Y与(x1,x2)是一种非线性关系,可以简单的看到,上述y1,y2,y3分别与(x1,x2)有关,z1,z2,z3分别于y1,y2,y3有关,而最终的Y又分别与z1,z2,z3有关,在多层迭代后,Y就可以用(x1,x2)的非线性复合关系表示出来了。一般来说,这个网络是可以表示任意的非线性关系的。
- 在已知这样一个网络的所有参数以后,那么给定一个输入,得到输出是非常快的,就是一直正向计算,而计算机做这件事很轻松,所以说训练好的神经网络是一种非常快的分类方法。然而这个网络参数的训练过程却并不是那么轻松愉快。
经过上述的说明,我们已经知道神经网络的强大(表示任意的非线性关系的)。那么下面的问题就是如何训练这个网络。
在logistic分类算法中,我们知道,那样一个一层网络权值参数是通过结果与预测结果的误差值,通过梯度下降法不断调整权值参数的。那么这个多层网络呢?同样采用这种方法来实现,不同的是,这里需要一层一层的计算。
首先我们设定好隐含层以及每层的节点数,然后构造一个权值随机的网络,对于训练样本的每一个样本输入就会有一个输出值o,那么这个o与实际的值t会有一个误差e(既然是训练样本,一定会有一个目标分类结果t的),根据上图的结果可以看到,这个e将直接与最后一层的输入z’(sigmod出来的值)以及权值v相关,这样我们可以通过这个e来更新v,同时我们可以将这个误差e按照输入z’和权值v的大小分别分配到上一层的误差,也就是系统经过z后出来的误差值e1,e2,e3。(这个e1,e2,e3可以通过e、z’、v计算出来)。这样我们可以根据e1,e2,e3来更新权值u,同理再上一层y层,我们同样会有一组误差e4,e5,e6,而e4,e5,e6又可以通过其后面网络的值来表示,这样再更新权值w,如果还有,再继续往前面传播。对于权值的更新以及误差,这种通过后面网络的结果往前面传播的方法,就是神经网络中的反向传播算法。
下面来简单说说关于误差怎么往后面传播的,同时权值的计算公式是怎么更新的。这部分一本书
《机器学习》
的P74-P75上有详细的推导过程可以看看(考虑到两页公式,编辑公式实属不易就省了吧)。看不进书的,在附几个blog看看(书上最详细):
神经网络与反向传播算法
反向传播神经网络 BPNN
这里只给出最终的权值更新结果:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9173
9173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









