






MAPPO动作类型改进(一)——连续动作改进
说明
在前几篇文章中博主已经大致介绍过MAPPO算法代码的大致流程,在接下来的文章中博主会针对如何改进动作类型以更好地帮助大家结合自己的环境使用MAPPO算法。
本文和后续改进全部基于light_mappo进行改进。所有截图均为未进行操作的原始代码,代码块里为更改后的代码
第一步:更改env_wappers.py里面的参数
1.更改self.discrete_action_space为False
self.discrete_action_space = False
2.定义连续动作空间
原始代码Box函数中的shape=(2,),代表连续动作空间为2维;high和low为连续动作的上下限。

这里的2最好改成self.signal_action_dim,这样跟env的动作空间维度能保持一致。
if self.discrete_action_space:
u_action_space = spaces.Discrete(self.signal_action_dim) # 5个离散的动作
else:
u_action_space = spaces.Box(
low=-self.u_range, high=+self.u_range,
shape=(self.signal_action_dim,), dtype=np.float32
) # [-1,1]
if self.movable:
total_action_space.append(u_action_space)
第二步:更改distributions.py参数
由于上面的改进action_space已经变为Box,所以在act.py中
elif action_space.__class__.__name__ == "Box":(这里为true)
action_dim = action_space.shape[0]
self.action_out = DiagGaussian(inputs_dim, action_dim, use_orthogonal, gain)
但由于action_logits = self.action_out(x, available_actions)有两个参数需要传进函数,但class DiagGaussian下的def forward(self, x):只接受一个变量,因此可以:
action_logits = self.action_out(x)
或者可以:
def forward(self, x, available_actions=None):
第三步:更改env_runner.py
这里的代码基本意思就是把actions变成环境可识别的action_env,这个需要根据环境而定。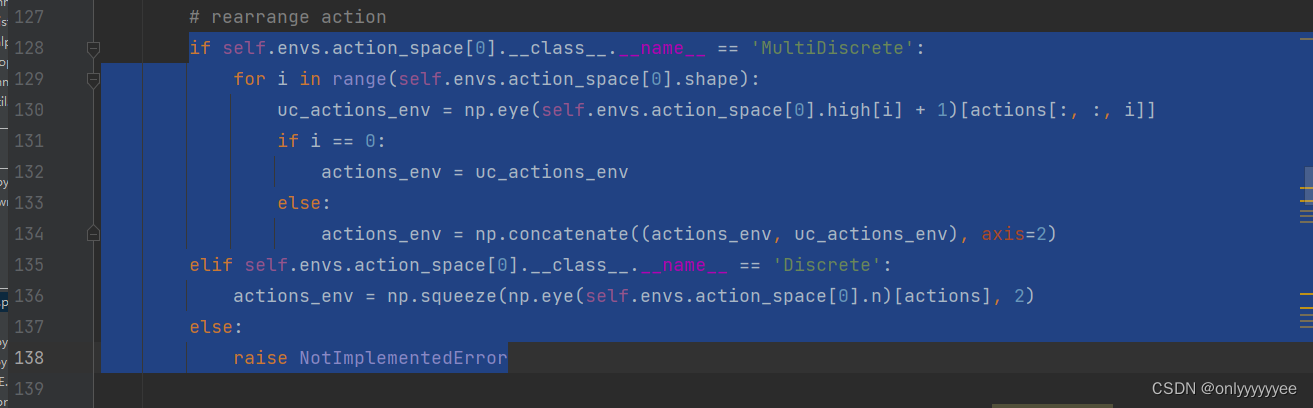
这里不更改会报错,为了方便可以删除,直接把actions赋给actions_env,后期在环境env.py中处理actions_env。
actions_env = actions
第四步:更改act.py
- 上面改完后基本就可以运行一个episode了,但是在运行到
train_infos = self.train()会出错,原因是act.py中evaluate_actions有问题。问题来源还是第二步中的问题一样,该进方法也是跟第二步一样,但处理方法需要前后保持一致。

- 改到这里点击运行后会出现如下错误:
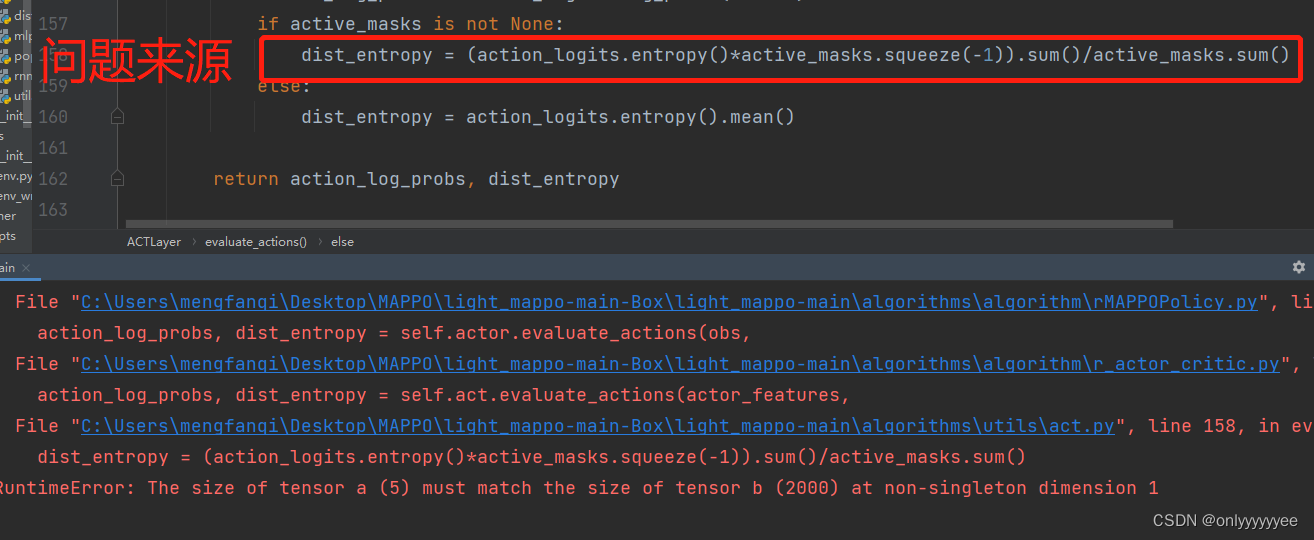
这里错误的原因是action_logits.entropy() 、active_masks.squeeze(-1)类型不一致造成的,action_logits.entropy() 的为Tensor:(2000, 5), active_masks.squeeze(-1) 为Tensor:(2000,),因此参照
if self.mixed_action:为True时执行的代码- 基于MAPPO改进的HAPPO
把问题来源那一行改成:
if self.action_type=="Discrete":
dist_entropy = (action_logits.entropy()*active_masks.squeeze(-1)).sum()/active_masks.sum()
else:
dist_entropy = (action_logits.entropy()*active_masks).sum()/active_masks.sum()
这一行的公式具体是干什么的我也搞不清楚。
结语
以上改进都来自个人经验,正确性还有需要结合具体环境验证,如有错误,欢迎指正。
对MAPPO算法代码总体流程不太了解,可以参考多智能体强化学习MAPPO源代码解读
对MAPPO算法理论知识不太了解,可以参考多智能体强化学习之MAPPO理论解读和多智能体强化学习(二) MAPPO算法详解














 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









