







paper:A Simple Framework for Contrastive Learning of Visual Representations
official implementation:https://github.com/google-research/simclr
third-party implementation:https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/models/selfsup/simclr.py
本文的创新点
本文提出了SimCLR:一种简单的视觉表示对比学习的框架。通过系统的研究该框架的主要组成部分,作者发现以下几个关键因素对于学习有效的表示至关重要:
- 数据增强的组合在定义有效的对比预测任务中起着关键作用。无监督对比学习相比于有监督学习,从数据增强的获益更多。
- 在representation和对比损失之间引入可学习的非线性变换可以显著提高学习到的表示的质量。
- 归一化的embedding和适当调整的温度参数对使用对比交叉熵损失的representation learning是有益的。
- 对比学习受益于更大的batch size和更长的训练时间。与监督学习一样,对比学习也受益于更深和更宽的网络。
方法介绍
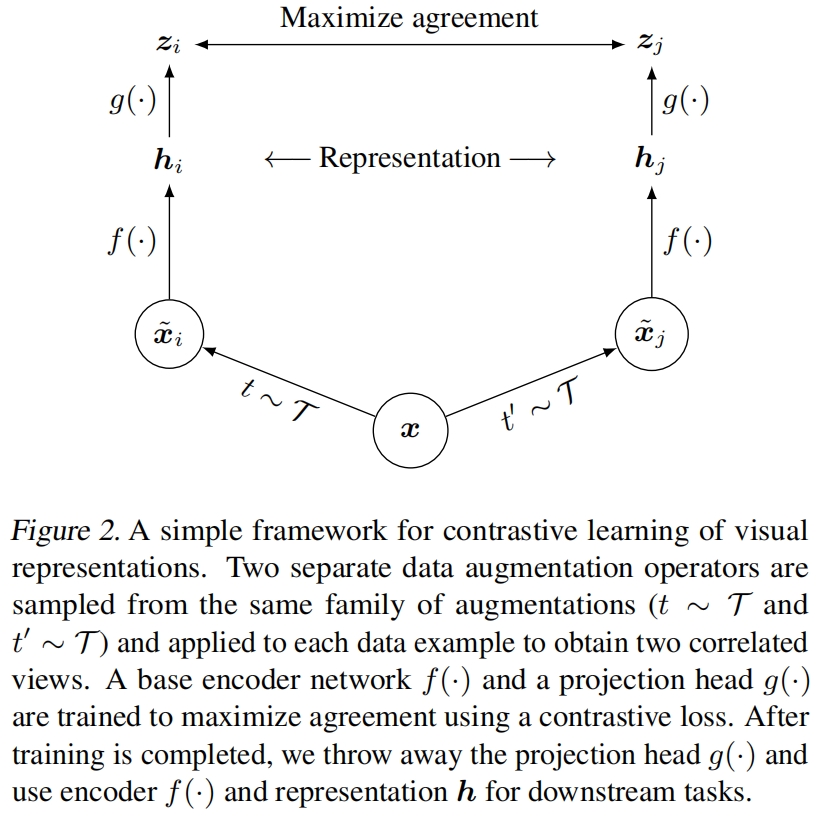
SimCLR的整体架构如图2所示,主要包括以下四个组成部分:
- 随机数据增强模块:这个模块对输入数据样本进行随机变换,得到同一示例的两个相关的视图,表示为 \(\widetilde{x}_i\) 和 \(\widetilde{x}_j\),我们将它们作为一个正样本对。本文依次应用三个简单的增强:随机裁剪然后resize到原来的大小、随机颜色失真、随机高斯模糊。后续实验表明,random crop和color distortion的组合是获得良好性能的关键。
- 基础编码网络 \(f(\cdot)\):它从增强后的数据样本中提取representation vector,SimCLR对编码网络的结构没有约束,为了简便,文本使用ResNet,得到 \(\boldsymbol{h}_i=f\left(\tilde{\boldsymbol{x}}_i\right)=\operatorname{ResNet}\left(\tilde{\boldsymbol{x}}_i\right)\),其中 \(\boldsymbol{h}_{i}\in \mathbb{R}^d\) 是average pooling层的输出。
- 投影头 \(g(\cdot)\):它是一个小型的神经网络,用于将表示映射到对比损失应用的空间。本文使用带有一个隐藏层的MLP来得到 \(\boldsymbol{z}_i=g\left(\boldsymbol{h}_i\right)=W^{(2)} \sigma\left(W^{(1)} \boldsymbol{h}_i\right)\),其中 \(\sigma\) 是ReLU激活函数。后续实验表明,对 \(\boldsymbol{z}_i\) 计算对比损失比对 \(\boldsymbol{h}_i\) 计算对比损失的效果好。
- 对比损失函数:给定集和 \(\left\{\tilde{\boldsymbol{x}}_k\right\}\) 其中包括一对正样本 \(\widetilde{x}_i\) 和 \(\widetilde{x}_j\),对比预测任务的目的是给定 \(\widetilde{x}_i\),从 \(\left\{\tilde{\boldsymbol{x}}_k\right\}_{k \neq i}\) 中识别出 \(\widetilde{x}_j\)。
我们随机采样 \(N\) 个样本组成一个minibatch,并对每个样本进行数据增强来定义对比预测任务,最终得到 \(2N\) 个data points。给定一对正样本,minibatch内其它 \(2(N-1)\) 个增强样本都视为负样本。\(\operatorname{sim}(\boldsymbol{u}, \boldsymbol{v})=\boldsymbol{u}^{\top} \boldsymbol{v} /\|\boldsymbol{u}\|\|\boldsymbol{v}\|\) 表示 \(\ell_2\) 归一化后的 \(\boldsymbol{u}\) 和 \(\boldsymbol{v}\) 之间的点积(即余弦相似度)。然后正样本对 \((i,j)\) 的损失定义如下

其中 \(\mathbb{1}_{[k \neq i]} \in\{0,1\}\) 是指示函数,当 \(k\ne i\) 时值为1。\(\tau\) 是温度参数。最终的loss值是minibatch内所有positive pairs的损失的均值,包括 \((i,j)\) 和 \((j,i)\)。这个损失在之前的文章中已经用过了,为了方便本文称之为NT-Xent(the normalized temperature-scaled cross entropy loss)。
SimCLR的伪代码如下

SimCLR的整体架构并没有太多创新的地方,之前的工作也用过相似的结构,除了最后多加了一个projection head。正文后续都是通过实验分析无监督对比学习中对学习有效的表示起关键作用的一些因素,包括数据增强、更大的batch size、更长的训练时长、多加一层非线性映射head、损失函数以及模型尺寸等。
Trainng with Large Batch Size. 在对比学习无监督的范式中,一般我们希望batch size越大越好,但受GPU显存限制,batch size不能太大。可行的解决方案包括使用memory bank,以及MoCo中的队列,本文是在谷歌的Cloud TPU上训练的,显存不是瓶颈,batch size可以设的很大,本文最大batch size=8192。但当batch size很大时,用SGD或Momentum优化器训练不稳定,因此本文采用了LARS优化器。
Global BN. ResNet中使用了BN层,在数据并行的分布式训练中,BN的均值和方差是在每个设备上聚合的,在本文的对比学习中,由于positive pairs也是在同一设备上计算的,模型可以利用局部的信息泄露在不提高representation的情况下提高预测精度。MoCo利用Shuffle BN解决这一问题,本文是通过在训练期间聚合所有设备的BN均值和方差来解决这一问题的。
数据增强操作的组合对学习good representation至关重要
为了系统的研究数据增强的影响,作者考虑了一些常见的增强方法。一类涉及数据的空间/几何变换,比如cropping、resize、flip、cutout。另一类涉及外观的变换,比如color distortion(包括color dropping、brightness、contrast、saturation、hue)、高斯模糊、Sobel滤波。图4可视化了提到的这些增强变换

图5展示了单个增强和两个增强组合下的linear evaluation结果,我们可以观察到,单个增强不足以学到良好的表示。而当组合两种增强方法时,对比预测任务变得更难,但表征质量显著提高了。
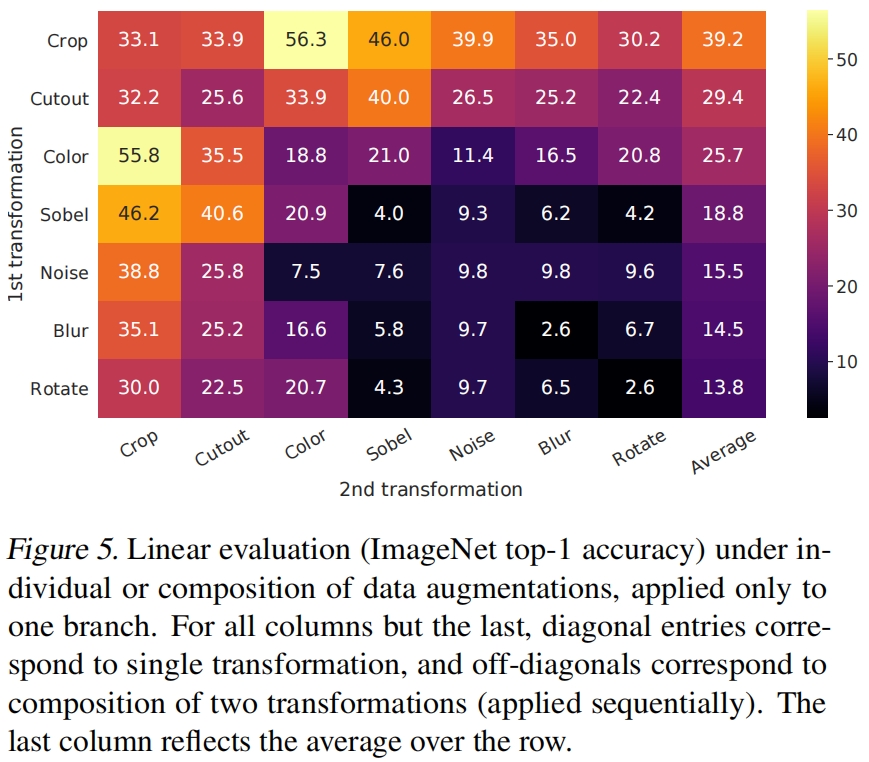
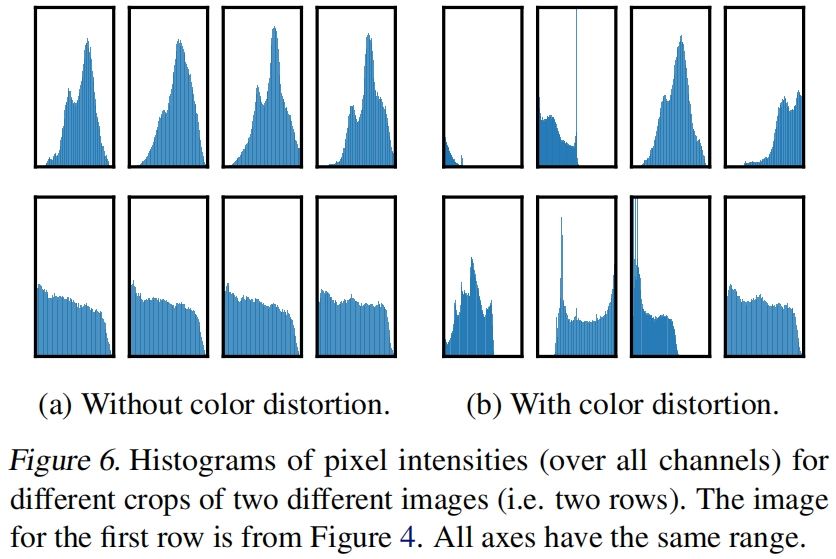
此外从图5还可以看出一个组合的表现很突出,random cropping和random color distortion。作者推测,当只使用随机裁剪时,一个严重的问题是图像中的大多数patch具有相似的颜色分布,如图6所示,仅颜色直方图就足以区分图像了。神经网络可以利用这个捷径来解决预测任务,所以为了学习可泛化的特征,组合使用裁剪和颜色抖动非常重要。
对比学习需要比监督学习更强的数据增强
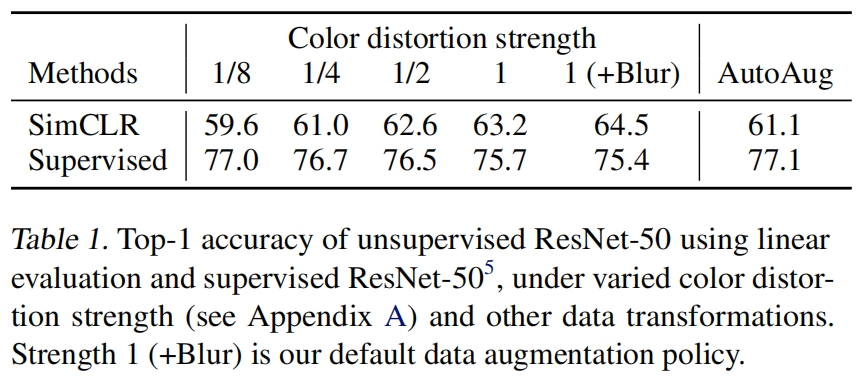
为了进一步证明color增强的重要性,作者调整了颜色增强的强度如表1所示。更强的颜色增强大大显著提高了无监督模型的线性评估结果。在这种情况下,AutoAugment(一种使用监督学习发现的复杂的增强策略)并不比简单的裁剪+更强的颜色增强的效果好。当用相同的增强方法训练监督模型时,作者观察到更强的颜色增强不会提高甚至会降低模型的性能。因此这个实验表明,无监督对比学习相比监督学习,更受益于更强的(颜色)增强。换句话说,对监督学习没有帮助的数据增强仍可以大大帮助对比学习。
代码解析
这里讲解的是mmpretrain的实现,完整实现如下,其中加了一些注释方便理解。
# Copyright (c) OpenMMLab. All rights reserved.
from typing import Any, Dict, List, Tuple
import torch
from mmengine.dist import all_gather, get_rank
from mmpretrain.registry import MODELS
from mmpretrain.structures import DataSample
from .base import BaseSelfSupervisor
class GatherLayer(torch.autograd.Function):
"""Gather tensors from all process, supporting backward propagation."""
@staticmethod
def forward(ctx: Any, input: torch.Tensor) -> Tuple[List]:
ctx.save_for_backward(input)
output = all_gather(input)
return tuple(output)
@staticmethod
def backward(ctx: Any, *grads: torch.Tensor) -> torch.Tensor:
input, = ctx.saved_tensors
grad_out = torch.zeros_like(input)
grad_out[:] = grads[get_rank()]
return grad_out
@MODELS.register_module()
class SimCLR(BaseSelfSupervisor):
"""SimCLR.
Implementation of `A Simple Framework for Contrastive Learning of Visual
Representations <https://arxiv.org/abs/2002.05709>`_.
"""
@staticmethod
def _create_buffer(
batch_size: int, device: torch.device
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""Compute the mask and the index of positive samples.
Args:
batch_size (int): The batch size.
device (torch.device): The device of backend.
Returns:
Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
- The mask for feature selection.
- The index of positive samples.
- The mask of negative samples.
"""
mask = 1 - torch.eye(batch_size * 2, dtype=torch.uint8).to(device)
pos_idx = (
torch.arange(batch_size * 2).to(device),
2 * torch.arange(batch_size, dtype=torch.long).unsqueeze(1).repeat(
1, 2).view(-1, 1).squeeze().to(device))
# (2N,), tensor([0, 0, 2, 2, 4, 4, 6, 6, ..., 2*(N-1), 2*(N-1)])
neg_mask = torch.ones((batch_size * 2, batch_size * 2 - 1),
dtype=torch.uint8).to(device)
neg_mask[pos_idx] = 0
return mask, pos_idx, neg_mask
def loss(self, inputs: List[torch.Tensor], data_samples: List[DataSample],
**kwargs) -> Dict[str, torch.Tensor]:
"""The forward function in training.
Args:
inputs (List[torch.Tensor]): The input images.
data_samples (List[DataSample]): All elements required
during the forward function.
Returns:
Dict[str, torch.Tensor]: A dictionary of loss components.
"""
assert isinstance(inputs, list)
# [(4,3,224,224),(4,3,224,224)]
inputs = torch.stack(inputs, 1) # (4,2,3,224,224)
inputs = inputs.reshape((inputs.size(0) * 2, inputs.size(2),
inputs.size(3), inputs.size(4))) # (8,3,224,224)
x = self.backbone(inputs) # [(8,2048,7,7)]
z = self.neck(x)[0] # (2n)xd
# avgpool->fc0->bn0->relu->fc1->bn1
# (8,128)
z = z / (torch.norm(z, p=2, dim=1, keepdim=True) + 1e-10) # / (8,1) -> (8,128)
z = torch.cat(GatherLayer.apply(z), dim=0) # (2N)xd
# [(8,128)] -> (8,128)
# 非分布式训练时没有用。分布式训练时用于将每个进程即每个GPU上的结果gather到一起
assert z.size(0) % 2 == 0
N = z.size(0) // 2
s = torch.matmul(z, z.permute(1, 0)) # (2N)x(2N), (8,8)
mask, pos_idx, neg_mask = self._create_buffer(N, s.device) # (8,8), (torch.Size([8]), torch.Size([8])), (8,7)
# remove diagonal, (2N)x(2N-1)
s = torch.masked_select(s, mask == 1).reshape(s.size(0), -1) # (56) -> (8,7)
positive = s[pos_idx].unsqueeze(1) # (2N)x1, (8)->(8,1)
# select negative, (2N)x(2N-2)
negative = torch.masked_select(s, neg_mask == 1).reshape(s.size(0), -1) # (48)->(8,6)
loss = self.head.loss(positive, negative)
losses = dict(loss=loss)
return losses
接下来我们详细讲解一下。如图2所示,同一张图片经过两次不同的增强分别经过encoder网络,这里网络参数是共享的,实际就是一个网络,具体选用了ResNet-50,batch size设为4。进入loss函数,输入inputs是一个列表,即一个batch的图片经过两次增强得到的结果[(4, 3, 224, 224), (4, 3, 224, 224)],经过经过同一个encoder网络,将两者stack起来直接送入backbone和neck,最后得到(8, 128)的representation vector,然后进行L2归一化,GatherLayer是在分布式训练时将不同GPU上的结果合并到一起。然后进行点积得到相似度矩阵s。
接下来重点讲一下_create_buffer函数,首先mask如下
tensor([[0, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 1, 1, 1, 1, 1, 1],
[1, 1, 0, 1, 1, 1, 1, 1],
[1, 1, 1, 0, 1, 1, 1, 1],
[1, 1, 1, 1, 0, 1, 1, 1],
[1, 1, 1, 1, 1, 0, 1, 1],
[1, 1, 1, 1, 1, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0]], dtype=torch.uint8)这里mask和相似度矩阵s的shape都是(2N, 2N),注意这里2N的排列顺序是0,1是第一张图片的两个增强,2,3是第二张图片的两个增强。
pos_idx输出如下,列表中第一个tensor是行index的值,第二个tensor是列index的值。
(tensor([0, 1, 2, 3, 4, 5, 6, 7]), tensor([0, 0, 2, 2, 4, 4, 6, 6]))neg_mask的输出如下
tensor([[0, 1, 1, 1, 1, 1, 1],
[0, 1, 1, 1, 1, 1, 1],
[1, 1, 0, 1, 1, 1, 1],
[1, 1, 0, 1, 1, 1, 1],
[1, 1, 1, 1, 0, 1, 1],
[1, 1, 1, 1, 0, 1, 1],
[1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 0]], dtype=torch.uint8)接下来代码s = torch.masked_select(s, mask == 1).reshape(s.size(0), -1) # (56) -> (8,7)去掉s中对角线的值,因为对角线的值是图片和自身的相似度,这样(8, 8)的s就变成了(8, 7)。接下来按pos_idx取出positive pair的相似度值,如下在原始的mask矩阵中,同颜色的圆圈表示同一张图片的两个增强图片之间的相似度,因为我们去掉了对角线的值,同一行后面的值会往前补,这样第一行index=1处的圆圈往前移index变成了0,这样在s中第一张图片两个增强之间的相似度的索引分比为(0, 0)和(1, 0)。这里同一张图片的两个增强i, j之间的相似度要取两次(i, j)和(j, i)是因为如式1,在计算损失时,虽然分子是相同的,但分母分别是增强i和其它所有图片的相似度以及增强j和其它所有图片的相似度。
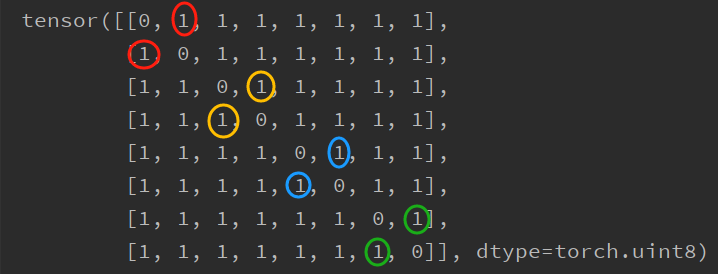
然后我们再根据neg_mask从s中取出negtive pair的相似度值,neg_mask中值为0的地方也就是上面同颜色的圆圈,因为我们去掉了对角线的值,奇数行就往前移了一位。
这里batch size=4,每张图片增强两次后得到8张图片,我们这里得到postive的shape=(8, 1),negative的shape=(8, 6)。最后计算损失loss = self.head.loss(positive, negative),这里损失采用交叉熵损失。head.loss的实现如下
def loss(self, pos: torch.Tensor, neg: torch.Tensor) -> torch.Tensor:
"""Forward function to compute contrastive loss.
Args:
pos (torch.Tensor): Nx1 positive similarity.
neg (torch.Tensor): Nxk negative similarity.
Returns:
torch.Tensor: The contrastive loss.
"""
N = pos.size(0)
logits = torch.cat((pos, neg), dim=1) # (8,7)
logits /= self.temperature
labels = torch.zeros((N, ), dtype=torch.long).to(pos.device) # (8,)
loss = self.loss_module(logits, labels)
return loss这里首先将pos和neg拼接起来得到一个(8, 7)的矩阵,接下里labels的设置非常巧妙,是一个长度为8值全为0的vector,这里logits的第一列是pos,后面6列是neg,对比下面交叉熵的式子和式1,这里可以将logits看做一个有7个类别的多分类问题,标签为第一类即0,我们希望模型将类别都预测为第一类即pos,这样pos pair的相似度越大越好,neg pair的相似度越小越好,这样就直接可以套用交叉熵的式子来计算损失了。
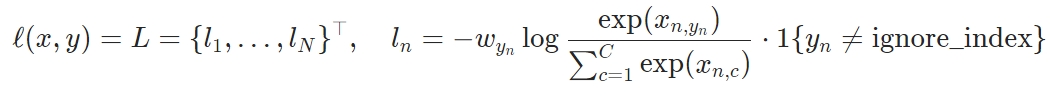
实验结果
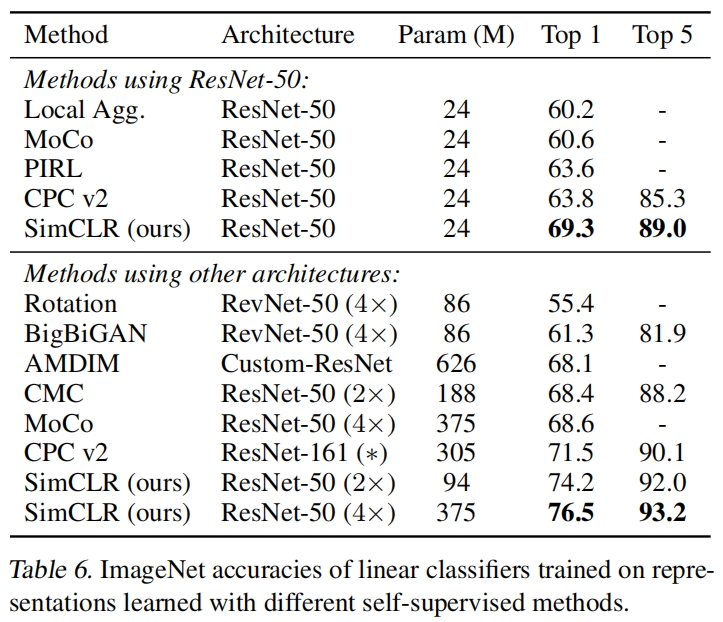
和其它无监督方法的对比如表6所示,可以看到SimCLR取得了最优的结果。
















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











