









paper:CCNet: Criss-Cross Attention for Semantic Segmentation
official implementation:https://github.com/speedinghzl/CCNet
third-party implementation:https://github.com/open-mmlab/mmcv/blob/main/mmcv/ops/cc_attention.py
存在的问题
传统的FCN网络受局部感受野的限制,无法捕获长距离的上下文信息。现有方法如扩张卷积和池化方法在聚合上下文信息时缺乏适应性,不能满足不同像素对不同上下文依赖的需求。基于图神经网络(GNN)的非局部神经网络虽然能够捕获全图像上下文信息,但计算复杂度高,占用大量GPU内存。
本文的创新点
本篇论文提出了一个新的语义分割网络CCNet,其中主要是提出了一个新的注意力模块Criss-Cross Attention Module(十字交叉注意力模块)。该模块通过在水平和垂直方向上聚合每个像素的上下文信息,通过递归操作使每个像素最终能够捕获全图像依赖关系。
Criss-Cross Attention
作者提出了一个交叉注意力模块,交叉注意力模块收集水平和垂直方向的上下文信息,以增强像素级表示能力。如图3所示
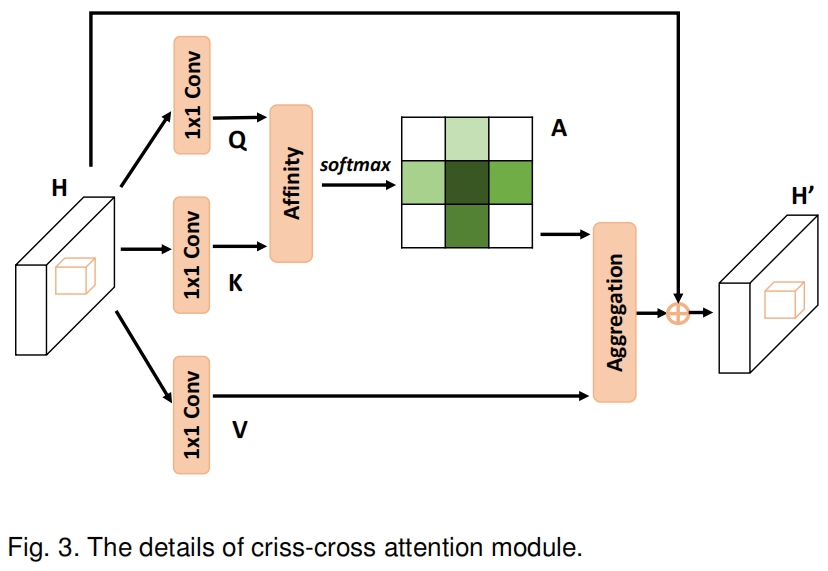
给定一个特征图 \(\mathbf{H}\in \mathbb{R}^{C\times W\times H}\),首先通过两个1x1卷积得到两个特征图 \(\{\mathbf{Q},\mathbf{K}\}\in \mathbb{R}^{C'\times W\times H}\),其中 \(C'\) 是通道数在降维时小于 \(C\)。
在得到 \(\mathbf{Q}\) 和 \(\mathbf{K}\) 后,我们通过Affinity operation得到一个attention map \(\mathbf{A}\in \mathbb{R}^{(H+W-1)\times (H\times W)}\)。对于 \(\mathbf{Q}\) 的每个空间位置 \(\mathbf{u}\),我们可以得到一个向量 \(\mathbf{Q}_{\mathbf{u}}\in \mathbb{R}^{C'}\)。同时我们提取 \(\mathbf{K}\) 中同一位置 \(\mathbf{u}\) 所在行列的所有特征向量得到一个集和 \(\mathbf{\Omega}_{\mathbf{u}}\in \mathbb{R}^{(H+W-1)\times C'}\)。\(\mathbf{\Omega}_{i,\mathbf{u}}\in \mathbb{R}^{C'}\) 是 \(\mathbf{Q}_{\mathbf{u}}\) 的第 \(i\) 个元素。Affinity operation定义如下
![]()
其中 \(d_{i,\mathbf{u}}\in \mathbf{D}\) 是特征 \(\mathbf{Q}_{\mathbf{u}}\) 和 \(\mathbf{\Omega}_{i,\mathbf{u}},\ i=[1,...,H+W-1]\) 之间的相关程度,\(\mathbf{D}\in \mathbb{R}^{(H+W-1)\times (W\times H)}\)。然后我们沿 \(\mathbf{D}\) 的通道维度计算softmax就得到了attention map \(\mathbf{A}\)。
\(\mathbf{H}\) 经过另一个1x1卷积得到 \(\mathbf{V}\in \mathbb{R}^{C\times W\times H}\)。对于 \(\mathbf{V}\) 的每个空间位置 \(\mathbf{u}\),我们可以得到一个向量 \(\mathbf{V}_{\mathbf{u}}\in \mathbb{R}^{C}\) 和 \(\mathbf{u}\) 所在行列所有特征的集和 \(\mathbf{\Phi}_{\mathbf{u}}\in \mathbb{R}^{(H+W-1)\times C}\)。然后按下式定义的Aggregation operation来聚合上下文信息
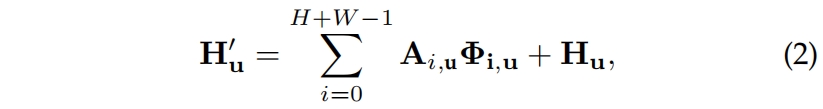
其中 \(\mathbf{H}'_{\mathbf{u}}\) 是 \(\mathbf{H}'\in \mathbb{R}^{C\times W\times H}\) 中位置 \(\mathbf{u}\) 处的特征向量,\(\mathbf{A}_{i,\mathbf{u}}\) 是 \(\mathbf{A}\) 中位置 \(\mathbf{u}\) 通道 \(i\) 处的标量值。将上下文信息添加到局部特征 \(\mathbf{H}\) 中,以增强像素级表示。因此,它具有广泛的上下文视角,并根据空间注意图选择性地聚合上下文。
代码
官方实现将十字交叉注意力分成横向、纵向两部分,其中将对角线的值设为INF是防止十字交叉的中心点计算两次注意力。
import torch
import torch.nn as nn
from torch.nn import Softmax
def INF(B, H, W): # 8,60,60
# ()->(H)->(H,H)->(1,H,H)->(BW,H,H)
return -torch.diag(torch.tensor(float("inf")).repeat(H), 0).unsqueeze(0).repeat(B * W, 1, 1)
class CrissCrossAttention(nn.Module):
"""Criss-Cross Attention Module.
.. note::
Before v1.3.13, we use a CUDA op. Since v1.3.13, we switch
to a pure PyTorch and equivalent implementation. For more
details, please refer to https://github.com/open-mmlab/mmcv/pull/1201.
Speed comparison for one forward pass
- Input size: [2,512,97,97]
- Device: 1 NVIDIA GeForce RTX 2080 Ti
+-----------------------+---------------+------------+---------------+
| |PyTorch version|CUDA version|Relative speed |
+=======================+===============+============+===============+
|with torch.no_grad() |0.00554402 s |0.0299619 s |5.4x |
+-----------------------+---------------+------------+---------------+
|no with torch.no_grad()|0.00562803 s |0.0301349 s |5.4x |
+-----------------------+---------------+------------+---------------+
Args:
in_channels (int): Channels of the input feature map.
"""
def __init__(self, in_channels: int) -> None:
super().__init__()
self.query_conv = nn.Conv2d(in_channels, in_channels // 8, 1)
self.key_conv = nn.Conv2d(in_channels, in_channels // 8, 1)
self.value_conv = nn.Conv2d(in_channels, in_channels, 1)
self.in_channels = in_channels # 512
def forward(self, x):
self.softmax = Softmax(dim=3)
m_batchsize, _, height, width = x.size() # (8,512,60,60)
proj_query = self.query_conv(x) # (8,64,60,60)
# (b,c,h,w)->(b,w,c,h)->(bw,c,h)->(bw,h,c)
proj_query_H = proj_query.permute(0, 3, 1, 2).contiguous().view(m_batchsize*width, -1, height).permute(0, 2, 1) # (bw,h,c),(480,60,64)
# (b,c,h,w)->(b,h,c,w)->(bh,c,w)->(bh,w,c)
proj_query_W = proj_query.permute(0, 2, 1, 3).contiguous().view(m_batchsize*height, -1, width).permute(0, 2, 1) # (bh,w,c),(480,60,64)
proj_key = self.key_conv(x) # (8,64,60,60)
# (b,c,h,w)->(b,w,c,h)->(bw,c,h)
proj_key_H = proj_key.permute(0, 3, 1, 2).contiguous().view(m_batchsize*width, -1, height) # (bw,c,h),(480,64,60)
# (b,c,h,w)->(b,h,c,w)->(bh,c,w)
proj_key_W = proj_key.permute(0, 2, 1, 3).contiguous().view(m_batchsize*height, -1, width) # (bh,c,w),(480,64,60)
proj_value = self.value_conv(x) # (8,512,60,60)
# (b,h,c,w)->(b,w,c,h)->(bw,c,h)
proj_value_H = proj_value.permute(0, 3, 1, 2).contiguous().view(m_batchsize*width, -1, height) # (bw,c,h),(480,512,60)
# (b,c,h,w)->(b,h,c,w)->(bh,c,w)
proj_value_W = proj_value.permute(0, 2, 1, 3).contiguous().view(m_batchsize*height, -1, width) # (bh,c,w),(480,512,60)
# (bw,h,c)@(bw,c,h)->(bw,h,h)=(480,60,60)
# INF->(bw,h,h)=(480,60,60)
# (bw,h,h)->(b,w,h,h)->(b,h,w,h)
energy_H = (torch.bmm(proj_query_H, proj_key_H) + INF(m_batchsize, height, width)).view(m_batchsize, width, height, height).permute(0, 2, 1, 3) # (8,60,60,60)
# (bh,w,c)@(bh,c,w)->(bh,w,w)->(b,h,w,w)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize, height, width, width) # (8,60,60,60)
# [(b,h,w,h),(b,h,w,w)]->(b,h,w,h+w)
# 实际应该是h+w-1,对角线设为-inf了,在softmax中不起作用,防止十字交叉中心点算两次
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:, :, :, 0: height].permute(0, 2, 1, 3).contiguous().view(m_batchsize*width, height, height)
# (b,h,w,h)->(b,w,h,h)->(bw,h,h)
att_W = concate[:, :, :, height:height+width].contiguous().view(m_batchsize*height, width, width)
# (b,h,w,w)->(bh,w,w)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize, width, -1, height).permute(0, 2, 3, 1)
# (bw,c,h)@(bw,h,h)->(bw,c,h)->(b,w,c,h)->(b,c,h,w)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize, height, -1, width).permute(0, 2, 1, 3)
# (bh,c,w)@(bh,w,w)->(bh,c,w)->(b,h,c,w)->(b,c,h,w)
return self.gamma*(out_H + out_W) + x
def __repr__(self) -> str:
s = self.__class__.__name__
s += f'(in_channels={self.in_channels})'
return s
if __name__ == '__main__':
model = CrissCrossAttention(512)
x = torch.randn(8, 512, 60, 60)
out = model(x)
print(out.shape)
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











